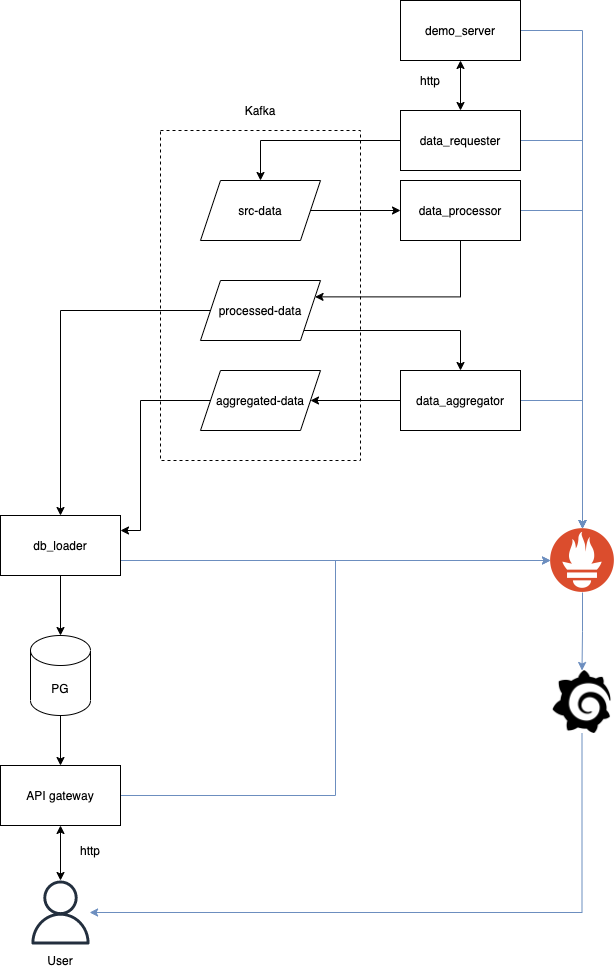
Сложные типы данных, такие как массивы (arrays), структуры (structs) и карты (maps), очень часто встречаются при обработке больших данных, особенно в Spark. Ситуация возникает каждый раз, когда мы хотим представить в одном столбце более одного значения в каждой строке, это может быть список значений в случае с типом данных массива или список пар ключ-значение в случае с картой.
Поддержка обработки этих сложных типов данных была расширена, начиная с версии Spark 2.4, за счет выпуска функций высшего порядка (HOFs). В этой статье мы рассмотрим, что такое функции высшего порядка, как их можно эффективно использовать и какие связанные с ними функции были выпущены в последних выпусках Spark 3.0 и 3.1.1. Для кода будем использовать Python API.
После агрегаций и оконных функций, которые мы рассмотрели в прошлой статье, HOF представляют собой еще одну группу более продвинутых преобразований в Spark SQL.
Давайте сначала посмотрим на разницу между тремя сложными типами данных, которые предлагает Spark.