В данной статье я подробно опишу один из методов обучения с подкреплением - обучение на основе функции полезности (Q-обучение или Q-learning).

@AtmosferaVAread-only
User
Добавление собственных данных в LLM с помощью RAG
Medium
28 min
Translation

Этот материал посвящён тому, как добавлять собственные данные в предварительно обученные LLM (Large Language Model, большая языковая модель) с применением подхода, основанного на промптах, который называется RAG (Retrieval‑Augmented Generation, генерация ответа с использованием результатов поиска).
Большие языковые модели знают о мире многое, но не всё. Так как обучение таких моделей занимает много времени, данные, использованные в последнем сеансе их обучения, могут оказаться достаточно старыми. И хотя LLM знакомы с общеизвестными фактами, сведения о которых имеются в интернете, они ничего не знают о ваших собственных данных. А это — часто именно те данные, которые нужны в вашем приложении, основанном на технологиях искусственного интеллекта. Поэтому неудивительно то, что уже довольно давно и учёные, и разработчики ИИ‑систем уделяют серьёзное внимание вопросу расширения LLM новыми данными.
До наступления эры LLM модели часто дополняли новыми данными, просто проводя их дообучение. Но теперь, когда используемые модели стали гораздо масштабнее, когда обучать их стали на гораздо больших объёмах данных, дообучение моделей подходит лишь для совсем немногих сценариев их использования. Дообучение особенно хорошо подходит для тех случаев, когда нужно сделать так, чтобы модель взаимодействовала бы с пользователем, используя стиль и тональность высказываний, отличающиеся от изначальных. Один из отличных примеров успешного применения дообучения — это когда компания OpenAI доработала свои старые модели GPT-3.5, превратив их в модели GPT-3.5-turbo (ChatGPT). Первая группа моделей была нацелена на завершение предложений, а вторая — на общение с пользователем в чате. Если модели, завершающей предложения, передавали промпт наподобие «Можешь рассказать мне о палатках для холодной погоды», она могла выдать ответ, расширяющий этот промпт: «и о любом другом походном снаряжении для холодной погоды?». А модель, ориентированная на общение в чате, отреагировала бы на подобный промпт чем‑то вроде такого ответа: «Конечно! Они придуманы так, чтобы выдерживать низкие температуры, сильный ветер и снег благодаря…». В данном случае цель компании OpenAI была не в том, чтобы расширить информацию, доступную модели, а в том, чтобы изменить способ её общения с пользователями. В таких случаях дообучение способно буквально творить чудеса!
Я перевел книгу с помощью нейросети ChatGPT
Medium
12 min
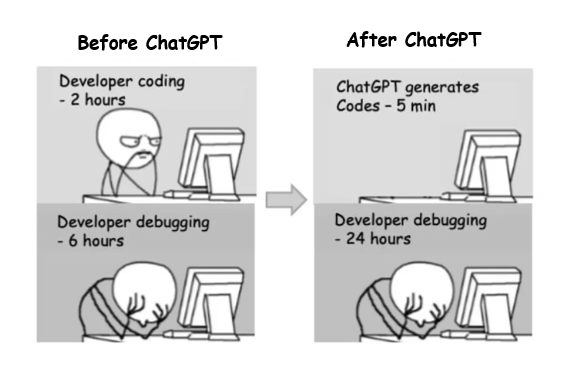
Когда речь идет о переводе книг, волнующие вопросы в части сохранения авторского стиля, передачи нюансов и точности перевода становятся неотъемлемой частью процесса. Но что если в этой сложной работе можно было бы найти современного помощника, способного справиться с решением этих сложных задач или, как минимум, в значительной степени упростить их? Начало 2023 года было ознаменовано взрывным развитием технологий искусственного интеллекта и нейросетей, с каждым днем они становится все более совершенными и способными решать задачи, с которыми ранее мог справиться только мыслительный процесс человека.
В этой статье я хочу рассказать вам об увлекательном мире перевода книг, особенностей и вызовов, с которыми сталкиваются переводчики, а также поделиться опытом в части того, как искусственный интеллект становится надежным союзником в этом процессе. На примере перевода книги «Rebuilding Milo» (автор Aaron Horschig) на русский язык с помощью искусственного интеллекта, мы рассмотрим, какие преимущества и возможности предоставляет такой подход, и как он может изменить практику перевода.
Яндексу здесь не место…
Easy
4 min
Analytics
Recovery Mode
Здравствуйте, уважаемые читатели!
Тема сегодняшней статьи будет несколько нестандартная, однако, безусловно связанная с информационными технологиями, нейросетями и технологическим гигантом нашего времени – компанией Яндекс.
Сразу хочу отметить – я отлично осознаю факт того, что Хабр не является площадкой для сведения счетов, размещения жалоб или ломания копий. И идея о том, чтобы написать свой отзыв об опыте общения с компанией Яндекс так и осталась бы идеей, лежащей где-то чуть ли не на дальней полочке в моем мозге, если бы буквально на днях, 18.01.2024 г., спустя 5 месяцев после того, как поступили со мной, я не увидел полностью аналогичный случай, о котором написали в сети. См. ссылку ниже:
https://journal.tinkoff.ru/kak-ia-pytalas-ustroitsia-na-rabotu-v-iandeks/
Прочитав пост, я понял, что эпопея “Яндекс-швырялово” длится уже около полугода и при этом все её организаторы чувствуют себя предельно комфортно, поэтому я был просто вынужден расчехлить перо.
Айтишницы, айда рожать
10 min

Совсем недавно мы призывали вернуться на родину всех, кто уехал от мобилизации, рассказывая о том, как родное государство печётся о работниках сферы ИТ. Однако нельзя забывать: по российским законам тотально военнообязанными являются мужчины, в то время как призвать могут только тех женщин, у которых есть военно-учетная специальность. Значит ли это, что целая половина населения и заметное число занятых в ИТ женщин останутся без отеческой заботы правительства?
Нет, нет и ещё раз нет!
Несмотря на мнения отдельных представителей власти о том, что рождение ребёнка — это билет в бедность, общий курс заботы правительства о женской части населения уже ясен: всем срочно и много рожать!
Эмбеддинги для начинающих
Easy
5 min

Привет, Хабр!
В широком смысле, эмбеддинг - это процесс преобразования каких-либо данных (чаще всего текста, но могут быть и изображения, звуки и т.д.) в набор чисел, векторы, которые машина может не только хранить, но и с которыми она может работать. Звучит очень интересно. Казалось бы, наша речь - это так просто, все связано и понятно. Но как это объяснить машине?
В этой статье мы рассмотрим, что такое эмбеддинги и какие они бывают.
Проще говоря эмбеддинг - это способ преобразования чего-то абстрактного, например слов или изображений в набор чисел и векторов. Эти числа не случайны; они стараются отражают суть или семантику нашего исходного объекта.
В NLP, например, эмбеддинги слов используются для того, чтобы компьютер мог понять, что слова «кошка» и «котенок» связаны между собой ближе, чем, скажем, «кошка» и «окошко». Это достигается путем присвоения словам векторов, которые отражают их значение и контекстное использование в языке.
Эмбеддинги не ограничиваются только словами. В компьютерном зрении, например, можно использовать их для преобразования изображений в вектора, чтобы машина могла понять и различать изображения.
Аппаратные трояны под микроскопом
Hard
14 min
Translation
Хотя индустрия кибербезопасности в основном сфокусирована на атаках на программное обеспечение, не стоит забывать о влиянии на безопасность аппаратных дефектов более низкого уровня, например, тех, которые касаются полупроводников. За последние несколько лет площадь атаки на уровне кремния сильно расширилась. Так как в производстве интегральных схем (ИС) используется всё более сложная микроэлектроника, риски проникновения дефектов в эти системы возрастают.
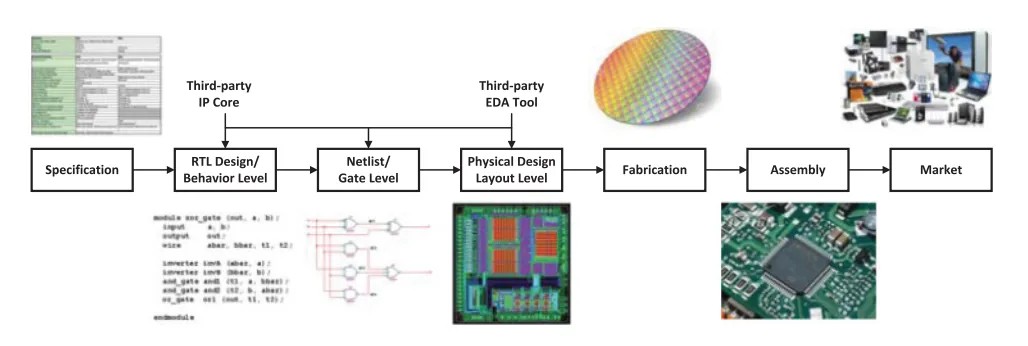
Процесс проектирования интегральных схем (ИС)
В этой статье мы расскажем об аппаратных троянах, в том числе о списках соединений, подготовке кристаллов, снимках электронных микроскопов и тестировании цепей. Также мы создадим собственную архитектуру и схему аппаратного трояна, которая будет проанализирована при помощи Klayout.
Процесс проектирования интегральных схем (ИС)
В этой статье мы расскажем об аппаратных троянах, в том числе о списках соединений, подготовке кристаллов, снимках электронных микроскопов и тестировании цепей. Также мы создадим собственную архитектуру и схему аппаратного трояна, которая будет проанализирована при помощи Klayout.
Как нашли бэкдор в радиосвязи TETRA — подробный разбор
Medium
19 min

Неприступных крепостей не бывает. Опасную брешь, то есть бэкдор, недавно обнаружили в шифрованном стандарте радиосвязи TETRA. А ведь он вот уже 25 лет используется военными, экстренными службами и объектами критической инфраструктуры по всему миру. Самое интересное, что на технические детали и контекст этой истории почти никто не обратил внимания.
Мы изучили статьи и доклады исследователей и собрали всю суть. Перед вами — подробная история взлома TETRA.
Качество переходного процесса ч.2
8 min
Tutorial
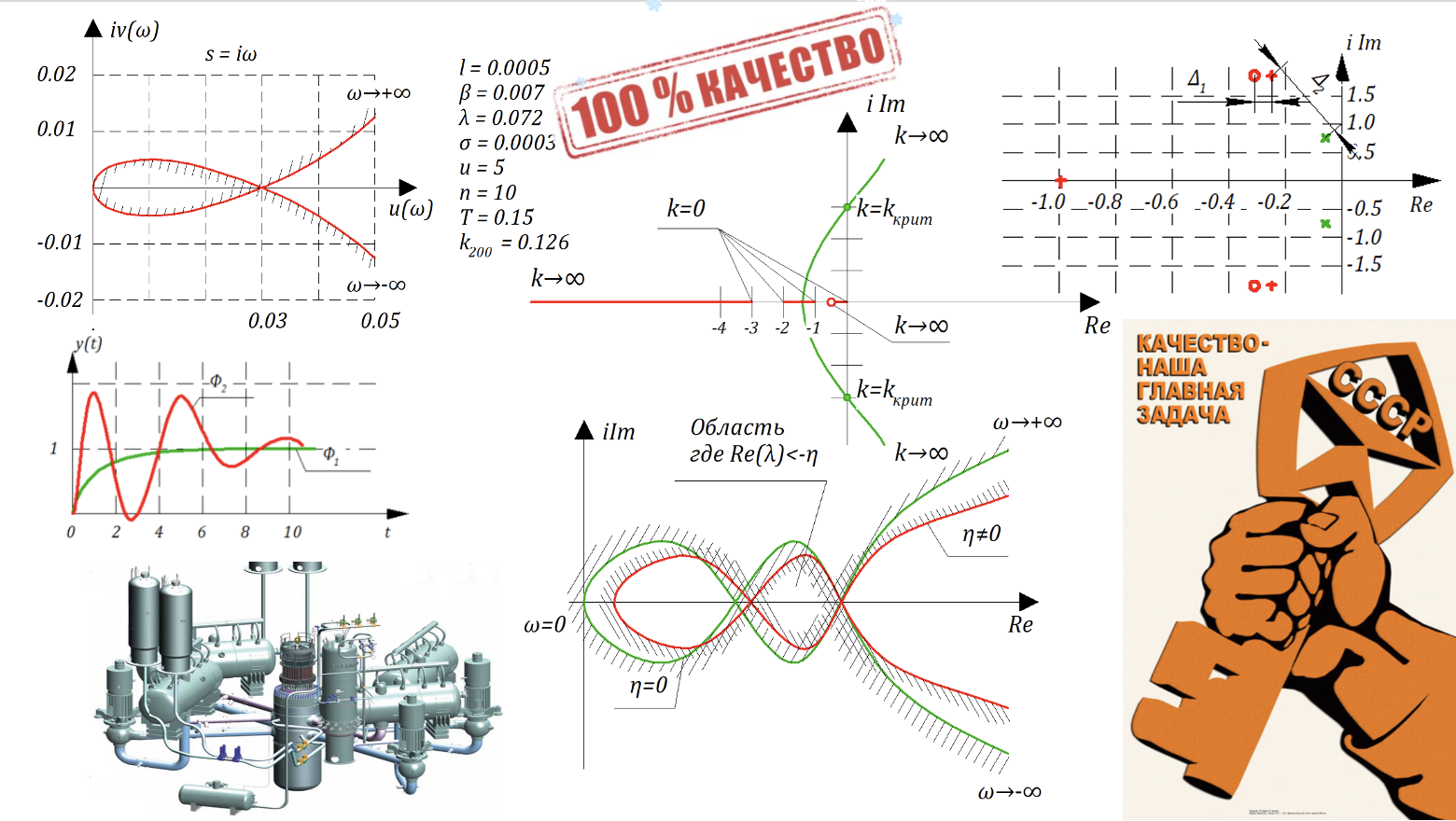
Продолжаем публикацию лекций Олега Степановича Козлова с кафедры Ядерные Энергетические Установки МГТУ им. Баумана. Вторая часть лекции про качество САР и модель реактора как бонус.
В предыдущих сериях:
1. Введение в теорию автоматического управления.2. Математическое описание систем автоматического управления 2.1 — 2.3, 2.3 — 2.8, 2.9 — 2.13.
3. Частотные характеристики звеньев и систем автоматического управления регулирования. 3.1. Амплитудно-фазовая частотная характеристика: годограф, АФЧХ, ЛАХ, ФЧХ. 3.2. Типовые звенья систем автоматического управления регулирования. Классификация типовых звеньев. Простейшие типовые звенья. 3.3. Апериодическое звено 1–го порядка инерционное звено. На примере входной камеры ядерного реактора. 3.4. Апериодическое звено 2-го порядка. 3.5. Колебательное звено. 3.6. Инерционно-дифференцирующее звено. 3.7. Форсирующее звено. 3.8. Инерционно-интегрирующее звено (интегрирующее звено с замедлением). 3.9. Изодромное звено (изодром). 3.10 Минимально-фазовые и не минимально-фазовые звенья. 3.11 Математическая модель кинетики нейтронов в «точечном» реакторе «нулевой» мощности.
4. Структурные преобразования систем автоматического регулирования.
5. Передаточные функции и уравнения динамики замкнутых систем автоматического регулирования (САР).
6. Устойчивость систем автоматического регулирования. 6.1 Понятие об устойчивости САР. Теорема Ляпунова. 6.2 Необходимые условия устойчивости линейных и линеаризованных САР. 6.3 Алгебраический критерий устойчивости Гурвица. 6.4 Частотный критерий устойчивости Михайлова. 6.5 Критерий Найквиста.
7. Точность систем автоматического управления. Часть 1 и Часть 2
На 50 оттенков красного меньше: обзор OSIO Focus Line F150i от PC HW-редактора
9 min

Привет, Хабр! На связи Иван Крылов (@Alaunquirie), сегодня изучаем отечественный ноутбук OSiO FocusLine F150i. Ко мне, как к HW-редактору с немалым опытом, обратились с предложением сделать обзор ноутбука, заглянуть в него, покопаться в железе и по максимуму выяснить, что девайс из себя представляет.
Как водится, отечественно в нём не так много (процессор и прочие комплектующие — заморские), но производитель (бренд OSiO создан группой компаний ICL) утверждает, что собираются ноутбуки в Иннополисе. Как правило, после этих слов морально готовишься увидеть неприличный ценник и сомнительного качества технику, но официальные розничные цены (от 40 до 50 тысяч рублей) приятно удивили. А после этого возник интерес: что внутри, как собрано, насколько адекватна цена и для кого производят такие лэптопы. Обо всём этом — под катом.
Прикладное терраформирование или как затратив 1 кВт получить 1.5 МВт
Easy
8 min
Recovery Mode

— А почему Белокуриху называют курортом?
— Ну как же, у нас тут природная аномалия, зимой вокруг — 40°С, а у нас — 20°С!
4 миллиарда операторов if
Medium
7 min
Review
Translation
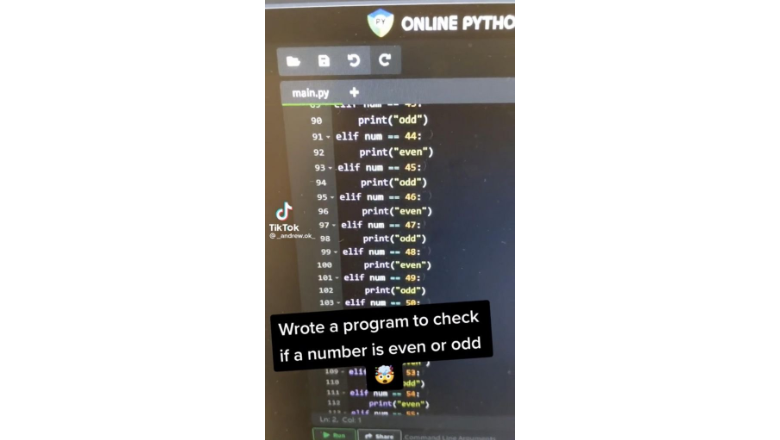
Просматривая недавно соцсети, я наткнулся на этот скриншот. Разумеется, его сопровождало множество злобных комментариев, критикующих попытку этого новичка в программировании решить классическую задачу computer science: операцию деления с остатком.
В современном мире, где ИИ постепенно заменяет программистов, отнимая у них работу и совершая переворот в том, как мы подходим к рассуждениям о коде, нам, возможно, следует быть более открытыми к мыслям людей, недавно пришедших в нашу отрасль? На самом деле, показанный выше код — идеальный пример компромисса между временем и задействованной памятью. Мы жертвуем временем и в то же время памятью и временем компьютера! Поистине чудесный алгоритм!
Поэтому я решил изучить эту идею проверки чётности числа при помощи одних сравнений, чтобы понять, насколько хорошо она работает в реальных ситуациях. Я сторонник высокопроизводительного кода, поэтому решил реализовать это на языке программирования C, потому что он и сегодня остаётся самым быстрым языком в мире с большим отрывом от других (благодаря гению Денниса Ричи).
«Квантовая» диаграма Виенна: как нас дурит научпоп
Easy
5 min

Хорошо, когда нам простыми словами объясняют сложные вещи, правда? Особенно когда речь про такие неочевидные эффекты как квантовая запутанность, суперпозиция и прочее квантовое. А как здорово, когда квантовый эффект можно увидеть своими глазами! Нам всего-то нужны три простые советские поляризующие пластинки...
Мой заржавелый мозг кипел. Я думал, что в 40+ лет нет смысла даже пытаться. Зачем предпринимателю идти в IT
Easy
9 min
Всё детство я что-то изобретал, ломал и чинил. Все были уверены, что я стану инженером или, в крайнем случае, телемастером. Но к окончанию вуза — а я учился на горного инженера-электромеханика — жизненный вектор изменился. Я стал изобретать, настраивать, ломать и чинить бизнесы. Был топ-менеджером компаний и делал своё — запускал кондитерское производство, продажу электроники, строительство купольных домов…
Сейчас мне 41 год, больше 15 лет я в бизнесе. Год назад я поступил в магистратуру на мехатроника-робототехника и стал изучать Python и машинное зрение. Как я пришёл к этой идее — не самое интересное (спойлер: через техническое хобби — спортивных дронов). А вот что из этого вышло и как новые знания помогают мне в бизнесе и могут помочь предпринимателям в целом — я подробно расскажу в этой статье.
Кто же такая это ваша LoRA
Medium
5 min
Review

В сети в последнее время регулярно мелькают статьи типа - как обучить Stable Diffusion генерировать ваши фотографии/фотографии в определенном стиле/фотографии определенного лора/такие фотографии итп.
Однако к сожалению, даже на хабре, об этой технологии рассказывают супер-поверхностно - как скачать какую-то GUI программу, и куда тыкать кнопочки. Поэтому я решил исправить это недоразумение, и выпустить первую статьи на русском, где полностью рассказывается что по настоящему стоит за этими 4-мя буквами.
Как дообучать огромные модели с максимальным качеством и минимальными затратами? LoRA
Medium
8 min
Review
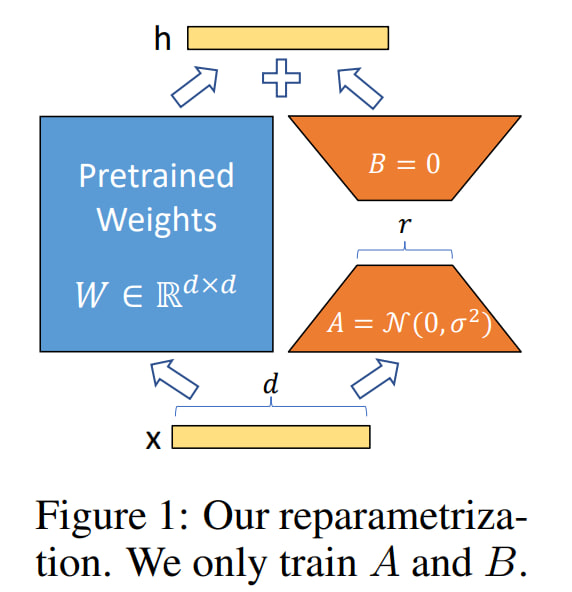
Для ответа на вопрос в заголовке - погрузимся в статью.
Саммари статьи:
Обычно LLM-ку предобучают на огромном корпусе, потом адаптируют на down-stream tasks. Если LLM-ка была большая, то мы не всегда можем в full fine-tuning. Авторы статьи предлагают Low-Rank Adaptation (LoRA), который замораживает предобученные веса модели и встраивает "rank decomposition matrices" в каждый слой трансформера, очень сильно понижая кол-во обучаемых параметров для downstream tasks.
Compared to GPT-3 175B fine‑tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times. LoRA performs on‑par or better than finetuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency.
Многие NLP-приложения требуют решения разных задач, что зачастую достигается путем дообучения большой модели на несколько разных downstream tasks. Самая важная проблема в классическом fine-tuning'е - новая модель содержит столько же параметров, сколько начальная.
Есть работы, где авторы адаптируют только некоторые параметры или обучают внешний модуль для каждой новой задачи. Таким образом, нам необходимо для каждой новой задачи хранить лишь веса, связанные с этой задачей. Однако, имеющиеся методы страдают от:
Inference latency (paper 1 - Parameter-Efficient Transfer Learning for NLP).
Reduced model's usable sequence length (paper 2 - Prefix-Tuning: Optimizing Continuous Prompts for Generation).
Часто не достигают бейзлайнов, если сравнивать с "классическим" fine-tuning'ом
Управление сервоприводами, часть 4. Управление «сервами» по I2C с Repka Pi через серво-драйвер Robointellect Controller
Medium
20 min
Tutorial
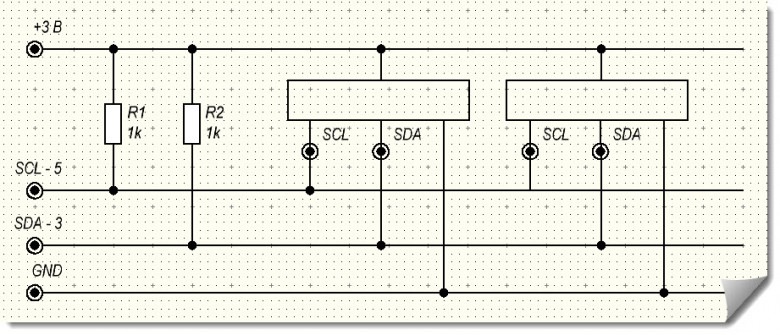
В предыдущих статьях нашей серии про сервоприводы мы рассказывали, как они устроены, как можно управлять сервоприводами с помощью широтно-импульсной модуляции ШИМ (Pulse Width Modulation, PWM) с помощью контроллеров Robointellect Controller 001, а также напрямую через GPIO через генератор ШИМ на плате микрокомпьютера Repka Pi.
В четвертой статье серии статей про сервоприводы мы расскажем, как управлять сервоприводами с помощью контроллеров Robointellect Controller 001 или PCA9685, подключенных к Repka Pi через шину I2C.
Как воспитать GPT модель в домашних условиях [LLaMA Update]
Medium
11 min
Review

Мы решили проверить технологию, на которой основан ChatGPT, посмотреть актуальное состояние open-source GPT-like моделей и ответить на вопрос — можно ли обучить GPT-like модель в домашних условиях?
Для эксперимента выбрали LLaMA и GPT-J и не самый мощный ПК с видеокартой Nvidia GTX 1080TI с 11 GB VRAM. Оказалось, что этого достаточно не только, чтобы загрузить модель, но и дообучить ее (fine-tune). Рассказываем — как мы это сделали.
GPT-4 добавляем новые знания: Git репозиторий
Easy
11 min
Tutorial

GPT-4 позволяет достаточно просто писать boilerplate код с использованием различных языков, технологий и библиотек. Но, есть небольшая проблема, данные GPT-4 не совсем актуальные и ограничены серединой 2021 года.
Проблема ясна, надо как то решать, потому что работать по-старому совсем не хочется. Уже привык, что можно достаточно просто попросить объяснить и сгенерировать код, пускай даже достаточно простого и можно сказать примитивного, но этого зачастую хватает, чтобы быстро понять как можно сделать задачу или найти нужную информацию.
Mixtral 8x7B – Sparse Mixture of Experts от Mistral AI
Medium
4 min

11 декабря 2023 года Mistral AI, парижский ai-стартап, основанный 7 месяцев назад, выпустил новую модель Mixtral 8x7B – high-quality sparse mixture of experts model (SMoE). Многие считают модели Mistral AI самыми крутыми из открытых llm-ок, я тоже так считаю, поэтому интерес к новой модели есть большой. В этой статье я хочу коротко пробежаться по тому, как устроена новая модель и какие у её архитектуры преимущества. На некоторых технических моментах я буду останавливаться более подробно, на некоторых – менее.