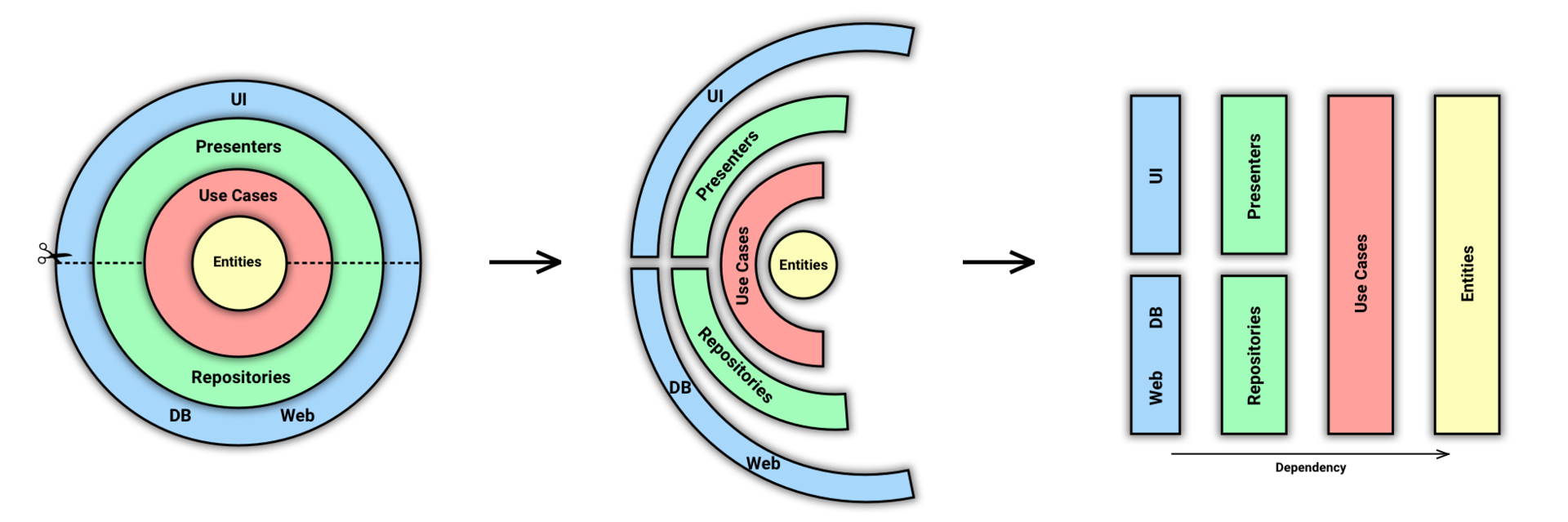
«Почему ж всё так плохо?» — каждый раз я задаюсь этим вопросом, когда приходится иметь дело с очередным кодом, продуктом или API, созданными для внутренних нужд в непрофильной организации.
В профильных дела обстоят получше, но далеко не всегда: в коробочных тиражируемых решениях чаще лучше, чем в проектной разработке. В продуктах одного заказчика, обычно, хуже всего.
И деньги ничего не решают: ужасный код и ужасные продукты пишут как маленькие бедные ВУЗы, у которых денег хватает только на рабский труд аспирантов, так и крупные и богатые компании, включая IT-компании, включая зарубежные: несколько раз сталкивался с кодом, который писали зарубежные подрядчики и каждый раз от него хотелось рыдать и биться головой об стену.
Организация может декларировать строгие стандарты, нанимать дорогостоящих разработчиков, вводить регламенты и методологии, надувать щеки на совещаниях и громогласно обличать «неправильное решение» в чужом продукте. И продолжать делать ужасные продукты с ужасным кодом, вопреки высокой квалификации своих разработчиков и очень правильными и нужными регламентами и стандартами.
Я занимался разработкой ПО в нескольких организациях и по разным причинам несколько раз перенабирал команду с нуля. В итоге пришел к выводу, что качество продукта зависит только от культуры разработки. Всё остальное, включая методологии и стандарты — это инструменты: они необходимы, но одних их не достаточно.
Культуру разработки можно сравнить с экосистемой: как сад или аквариум. Крепкая, здоровая культура обладает запасом прочности, чтобы оздоравливать обитателей экосистемы, избавляться от вредителей, прощать небольшие ошибки ухода, сглаживать стрессы и на выходе все-равно получать отличный результат. А больная культура сводит на нет все усилия, заражает и губит даже самые здоровые и крепкие саженцы.
В профильных дела обстоят получше, но далеко не всегда: в коробочных тиражируемых решениях чаще лучше, чем в проектной разработке. В продуктах одного заказчика, обычно, хуже всего.
И деньги ничего не решают: ужасный код и ужасные продукты пишут как маленькие бедные ВУЗы, у которых денег хватает только на рабский труд аспирантов, так и крупные и богатые компании, включая IT-компании, включая зарубежные: несколько раз сталкивался с кодом, который писали зарубежные подрядчики и каждый раз от него хотелось рыдать и биться головой об стену.
Организация может декларировать строгие стандарты, нанимать дорогостоящих разработчиков, вводить регламенты и методологии, надувать щеки на совещаниях и громогласно обличать «неправильное решение» в чужом продукте. И продолжать делать ужасные продукты с ужасным кодом, вопреки высокой квалификации своих разработчиков и очень правильными и нужными регламентами и стандартами.
Я занимался разработкой ПО в нескольких организациях и по разным причинам несколько раз перенабирал команду с нуля. В итоге пришел к выводу, что качество продукта зависит только от культуры разработки. Всё остальное, включая методологии и стандарты — это инструменты: они необходимы, но одних их не достаточно.
Культуру разработки можно сравнить с экосистемой: как сад или аквариум. Крепкая, здоровая культура обладает запасом прочности, чтобы оздоравливать обитателей экосистемы, избавляться от вредителей, прощать небольшие ошибки ухода, сглаживать стрессы и на выходе все-равно получать отличный результат. А больная культура сводит на нет все усилия, заражает и губит даже самые здоровые и крепкие саженцы.




 Юнит тесты помогают нам удостовериться, что код работает так, как мы этого хотим. Одной из метрик тестов является процент покрытия строк кода (Line Code Coverage).
Юнит тесты помогают нам удостовериться, что код работает так, как мы этого хотим. Одной из метрик тестов является процент покрытия строк кода (Line Code Coverage).