
Здесь собраны лучшие и самые полезные репозитории Github, которые будут служить вам долгое время.

User
Здесь собраны лучшие и самые полезные репозитории Github, которые будут служить вам долгое время.

В этом посте будет проанализировано, как каналы Unix реализуются в Linux. Для этого мы напишем и в несколько итераций оптимизируем тестовую программу, которая записывает и считывает данные через канал.


Хороший набор данных невероятно важен при обучении нейросетей. Наш датасет изображений с жестами HaGRID (Hand Gesture Recognition Image Dataset) — один из таких. С его помощью можно создать систему распознавания жестов, которая будет отлично работать в совершенно разных ситуациях. Например, жестовое управление можно использовать в видеоконференциях, для управления устройствами умного дома или мультимедийными возможностями автомобиля. Ещё одна важная возможность — создание виртуальных помощников для пользователей с дефектами речи или использующих язык жестов. Ниже рассказываем, как всё это работает, и делимся ссылками на датасет и набор предобученных моделей к нему.

Энкодер предложений (sentence encoder) – это модель, которая сопоставляет коротким текстам векторы в многомерном пространстве, причём так, что у текстов, похожих по смыслу, и векторы тоже похожи. Обычно для этой цели используются нейросети, а полученные векторы называются эмбеддингами. Они полезны для кучи задач, например, few-shot классификации текстов, семантического поиска, или оценки качества перефразирования.
Но некоторые из таких полезных моделей занимают очень много памяти или работают медленно, особенно на обычных CPU. Можно ли выбрать наилучший энкодер предложений с учётом качества, быстродействия, и памяти? Я сравнил 25 энкодеров на 10 задачах и составил их рейтинг. Самой качественной моделью оказался mUSE, самой быстрой из предобученных – FastText, а по балансу скорости и качества победил rubert-tiny2. Код бенчмарка выложен в репозитории encodechka, а подробности – под катом.
Зачем людям ранее был нужен VPN (кроме мошенников конечно) - чтоб ходить на Linkedin и обходить всякие разные запреты РКН.
Когда ввели санкции и некоторые сайты перекрасились в сине-желтый цвет, то многие по старой памяти подумали - включим VPN и всё сразу станет как раньше, разве что русские сайты начнут открываться на 50мс медленнее.
Но не тут-то было. Вместе с перекраской сайтов, началась волна DDoS и хакерских атак на различные сервисы в РФ. В итоге, российские сайты закрылись от остального интернета. И с VPN стало очень некомфортно - хочешь пользоваться Terraform или там MatterMost скачать - включаешь VPN и сразу же не можешь сходить ни на Ozon ни на Госуслуги.
Интернет разделился на InnerNet и OuterNet.


 Еще я создала канал в Telegram: GameDEVils, буду делиться там клевыми материалами (про геймдизайн, разработку и историю игр).
Еще я создала канал в Telegram: GameDEVils, буду делиться там клевыми материалами (про геймдизайн, разработку и историю игр).
— Я тут воду для проекта запилил.
— О, круто! А почему она плоская? Даёшь волны!
…
— Слушай, ты тогда про волны говорил, помнишь? Зацени!
— Да, хорошие волны, а преломление и каустику ещё не делал?
…
— Привет, я тут игрался с Unity всю ночь, смотри какие отражения и каустику закодил!
— Дарова, и правда, хорошо! А когда у тебя вода кипит, отражения не глючат?
…
— Хай, реализовал наконец, кипение, вроде ничего?
— О, прямо как нужно! Слушай, прикинь как круто, если кипящую волну заморозить?
…
— Лови картинку, лёд вроде ничего придумал?
— Норм, слушай, а у тебя лёд замерзает, он в объёме увеличивается? И кстати, ты когда геймлей то делать начнёшь?
Вариации на тему лога с другом.
Да, вы уже поняли, наконец-то расскажу про реализацию воды в проекте. Приступим?

Полнотекстовый поиск — неотъемлемая часть нашей жизни. Разыскать нужные материалы в сервисе облачного хранения документов Scribd, найти фильм в Netflix, купить туалетную бумагу на Amazon или отыскать с помощью сервисов Google интересующую информацию в Интернете — наверняка вы сегодня уже не раз отправляли похожие запросы на поиск нужной информации в невообразимых объёмах неструктурированных данных. И что удивительнее всего — несмотря на то что вы осуществляли поиск среди миллионов (или даже миллиардов) записей, вы получали ответ за считанные миллисекунды. Специально к старту нового потока курса Fullstack-разработчик на Python, в данной статье мы рассмотрим основные компоненты полнотекстовой поисковой машины и попытаемся создать систему, которая сможет за миллисекунды находить информацию в миллионах документов и ранжировать результаты по релевантности, причём всю систему можно воплотить всего в 150 строках кода на Python!

Когда я видел на Хабре упоминание о ПЛИС Lattice, у меня всегда возникал простой вопрос: «А зачем ещё одна ПЛИС?». Вроде всю жизнь хватало пары базовых. Но полгода назад случилось то, что сняло этот вопрос для меня. Пришёл Заказчик и сказал: «Мы делаем проект на ECP5». Против требований Заказчика не попрёшь!
А пока я осваивал работу с этим железом и пытался понять, как обосновать необходимость попробовать то же самое для остальных, мой знакомый, ныне живущий в Штатах, обрадовал новостью, что у его любимого поставщика подходит к концу запас десятых Циклонов и шестых Спартанов. В целом, через три года будет построен новый завод Intel, но что именно там будут производить, он не в курсе. И три года продержаться в любом случае, будет нужно. Короче, сейчас надо иметь возможность быстро мигрировать с одной ПЛИС на другую.
Итого, вчера делать ознакомительную статью про Lattice было рано, завтра – может быть поздно.
Сегодня я расскажу, где купить более-менее дешёвые платы для опытов, как быстро освоить Open Source среду разработки и какие готовые проекты осмотреть в первую очередь.
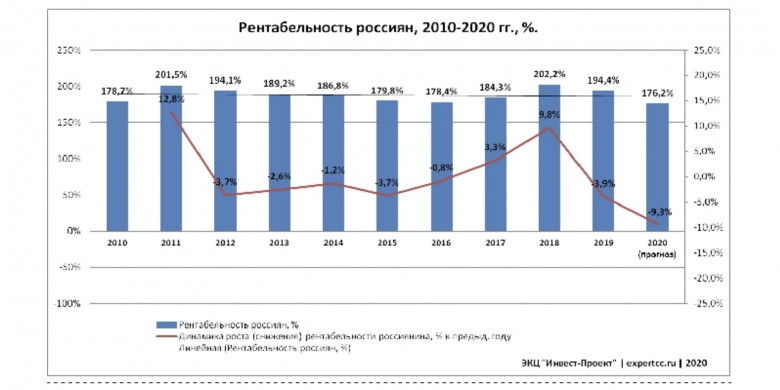
Мы уже выяснили, что у нас есть дефицит рабочих рук во всех отраслях. На примере СССР увидели, что дефицит легко закрывается деньгами и плюшками, что сейчас и происходит в IT. Однако при дефиците рабочих рук в остальных отраслях зарплаты остаются на уровне Румынии и никак не подтягиваются. Почему?

2021 год в машинном обучении ознаменовался мультимодальностью — активно развиваются нейросети, работающие одновременно с изображениями, текстами, речью, музыкой. Правит балом, как обычно, OpenAI, но, несмотря на слово «open» в своём названии, не спешит выкладывать модели в открытый доступ. В начале года компания представила нейросеть DALL-E, генерирующую любые изображения размером 256×256 пикселей по текстовому описанию. В качестве опорного материала для сообщества были доступны статья на arxiv и примеры в блоге.
С момента выхода DALL-E к проблеме активно подключились китайские исследователи: открытый код нейросети CogView позволяет решить ту же проблему — получать изображения из текстов. Но что в России? Разобрать, понять, обучить — уже, можно сказать, наш инженерный девиз. Мы нырнули с головой в новый проект и сегодня рассказываем, как создали с нуля полный пайплайн для генерации изображений по описаниям на русском языке.
В проекте активно участвовали команды SberAI, SberDevices, Самарского университета, AIRI и SberCloud.
Мы обучили две версии модели разного размера и дали им имена великих российских абстракционистов – Василия Кандинского и Казимира Малевича:
1. ruDALL-E Kandinsky (XXL) с 12 миллиардами параметров;
2. ruDALL-E Malevich (XL), содержащая 1,3 миллиарда параметров.
Некоторые версии наших моделей доступны в open source уже сейчас:
1. ruDALL-E Malevich (XL) [GitHub, HuggingFace]
2. Sber VQ-GAN [GitHub, HuggingFace]
3. ruCLIP Small [GitHub, HuggingFace]
4. Super Resolution (Real ESRGAN) [GitHub, HuggingFace]
Две последние модели встроены в пайплайн генерации изображений по тексту (об этом расскажем ниже).
Версии моделей ruDALL-E Malevich (XL), ruDALL-E Kandinsky (XXL), ruCLIP Small, ruCLIP Large, Super Resolution (Real ESRGAN) также скоро будут доступны в DataHub.
Обучение нейросети ruDALL-E на кластере Christofari стало самой большой вычислительной задачей в России:
1. Модель ruDALL-E Kandinsky (XXL) обучалась 37 дней на 512 GPU TESLA V100, а затем ещё 11 дней на 128 GPU TESLA V100 — всего 20 352 GPU-дней;
2. Модель ruDALL-E Malevich (XL) обучалась 8 дней на 128 GPU TESLA V100, а затем еще 15 дней на 192 GPU TESLA V100 – всего 3 904 GPU-дня.
Таким образом, суммарно обучение обеих моделей заняло 24 256 GPU-дней.
Разберём возможности наших генеративных моделей.

Несколько месяцев я изучал тему интернет мошенничества с целью собрать наиболее полный список действий, которые обезопасили бы меня от жуликов и их махинаций. Итогом изучения стал чек-лист, которым хочу поделиться со всеми. Его цель - сделать взлом цифровых активов сложным и бессмысленным.


Похоже в Россию снова ввозят ядерные материалы из Европы. Позавчера в Париже Гринпис Франции провел акцию протеста против отправки в Россию 1000 тонн регенерированного урана. Увидев в их твиттере новость об этом я понял, что скоро и в наших СМИ начнется шум. И вот он начался. Попытался на скорую руку разобраться с тем о чем идет речь, что же к нам везут, насколько это похоже на историю с ввозом ОГФУ из Германии, с которой я подробно разбирался ранее, и при чем тут выступление президента Франции Макрона.


38 роботов, которые расширят потенциал человека. Обзор команд полуфиналистов $10M ANA Avatar XPRIZE - четырехлетнего международного соревнования по разработке управляемых оператором роботов-аватаров, позволяющих переносить в любую точку пространства навыки и опыт человека.
На участие в соревновании, стартовавшем в 2018 году, было подано более 1800 заявок. В полуфинал вышли 38 команд, среди них 1 команда из России.
