Проблема
Когда мы разрабатываем приложение, которое разделено на независимые автономные компоненты, мы говорим о микросервисной архитектуре. Для взаимодействия компонентов используется API. Самый популярным API является REST. Это обусловлено его гибкостью, эффективностью (в большинстве сценариев) и тем, что он легко масштабируется.
Большая часть реализаций REST использует стандарт JSON для обмена сообщениями. Обычно это удобно - сама по себе такая структура легко читается людьми и предоставляет независимость от языка программирования. Недостатками такого решения является избыточность данных и сущностей из которых состоит запрос. В большинстве случаев это некритично. Проблемы начинаются в сценариях, когда нужно передавать много данных с низкой задержкой.
Зачем нужен gRPC
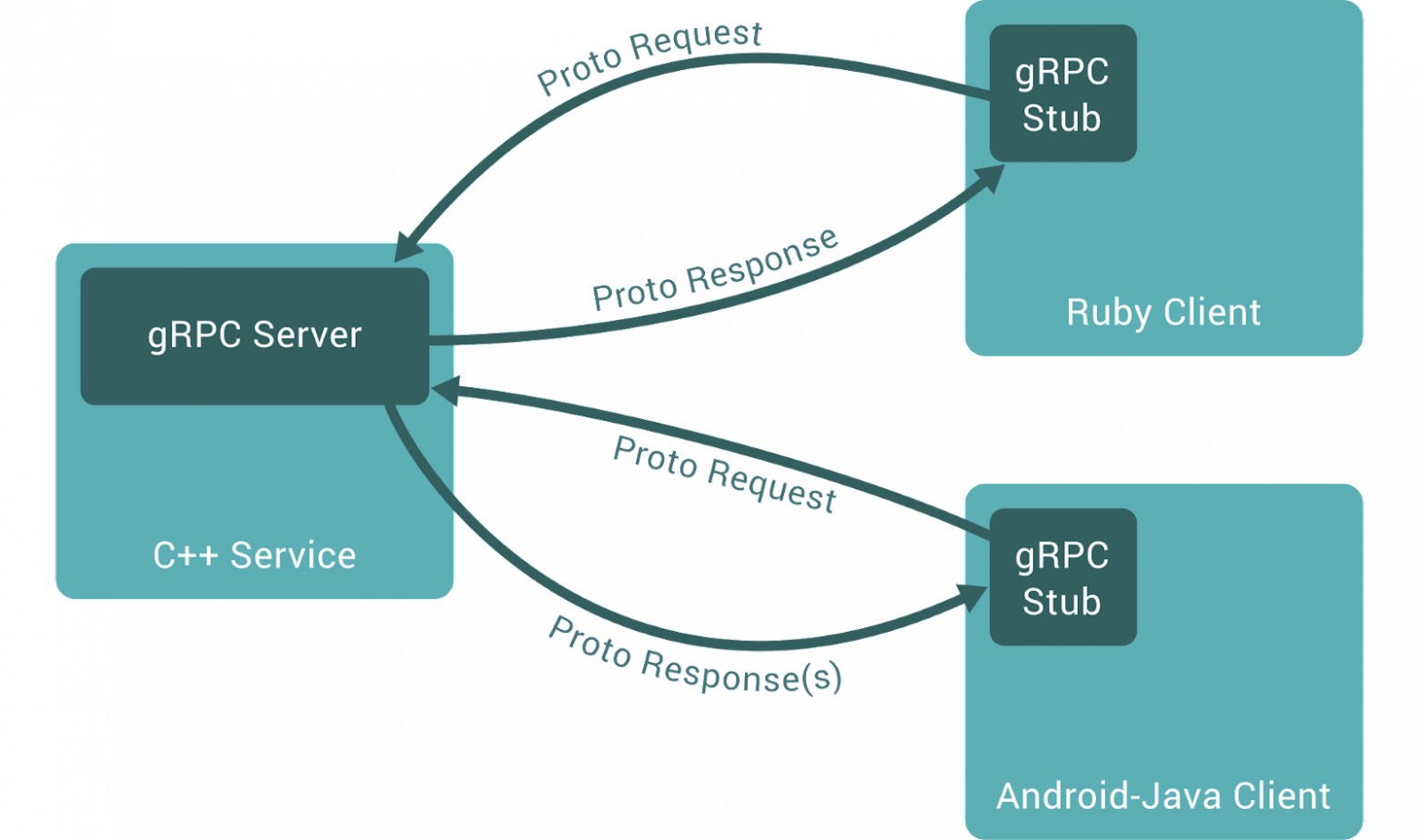
gRPC (Remote Procedure Calls) — это система удалённого вызова процедур (RPC) с открытым исходным кодом, первоначально разработанная в Google. В качестве основного протокола передачи применяется HTTP/2, для описания процедур применяется “Protocol Buffers”. Это в свою очередь приносит дополнительные преимущества: сжатие HTTP-заголовков и мультиплексирование запросов.
gRPC предполагает возможность аутентификации, потоковой передачи данных в любую сторону, управление потоками, отмену и time-out запросов, при этом выделяется кроссплатформенностью за счет генерации исходного кода классов для всех популярных языков программирования.