Мы, студенты из МИФИ, Даниил и Александр, пришли на стажировку в Сбербанк в департамент SberData, который занимается развитием внутренней корпоративной аналитической платформы (КАП).Это современная платформа с удобными инструментами созданная для закрытия полного спектра потребностей Сбера в работе с данными, таких как хранение, интеграция, разнообразная аналитика, отчетность, моделирование и контроль качества данных. Все эти направления было бы трудно развивать без отдельного R&D подразделения, в составе которого мы и работаем. Сегодня мы хотим поделиться нашим исследованием в области проектирования алгоритмов в выявлении «токсичных» SQL‑запросов с помощью машинного обучения. Почему же запросы называются именно «токсичные»? Они затрачивают на своё выполнение слишком большое количество ресурсов, а именно времени. На самом деле не только время, но для упрощения мы будем считать только время, так как это ключевой параметр.
Статья посвящена исследованию существующих подходов и их апробации на открытых данных. В качестве общедоступных данных были выбраны данные из таких бенчмарков, как TPC‑H и BIRD. Помимо этого, в статье рассматриваются некоторые трудности, с которыми мы столкнулись при работе над задачей, например, генерация данных и SQL‑запросов, а также миграция между диалектами SQL. В конце статьи мы опишем оригинальный подход, к которому по итогу пришли. В следующей статье мы расскажем о применении полученного опыта для реальной промышленной системы.











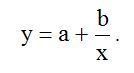 (1)
(1)




 По умолчанию конфигурация PostgreSQL не настроена для рабочей нагрузки. Значения по умолчанию установлены для обеспечения работоспособности PostgreSQL везде с наименьшим количеством ресурсов. Имеются настройки по умолчанию для всех параметров базы данных. Главной обязанностью администратора базы данных или разработчика является настройка PostgreSQL в соответствии с нагрузкой их системы. В этом блоге мы изложим основные рекомендации по настройке параметров базы данных PostgreSQL для повышения производительности базы данных в соответствии с рабочей нагрузкой.
По умолчанию конфигурация PostgreSQL не настроена для рабочей нагрузки. Значения по умолчанию установлены для обеспечения работоспособности PostgreSQL везде с наименьшим количеством ресурсов. Имеются настройки по умолчанию для всех параметров базы данных. Главной обязанностью администратора базы данных или разработчика является настройка PostgreSQL в соответствии с нагрузкой их системы. В этом блоге мы изложим основные рекомендации по настройке параметров базы данных PostgreSQL для повышения производительности базы данных в соответствии с рабочей нагрузкой.
