
Давайте будем честными.
Простые промпты наподобие "Напиши статью из 1500 слов под заголовком: Топ-10 продуктов, которые разрушают вашу печень» не дадут вам и 1% тех результатов, которые способен дать Chat GPT.

Java разработчик
Давайте будем честными.
Простые промпты наподобие "Напиши статью из 1500 слов под заголовком: Топ-10 продуктов, которые разрушают вашу печень» не дадут вам и 1% тех результатов, которые способен дать Chat GPT.

Сегодня я расскажу о 20 практических вариантах использования GPT-4o, в которых возможности визуального ИИ используются так, как вы, возможно, никогда не думали — и нет, это не типичные промпты «напишите письмо».
Хотя нейронные сети стали использоваться для синтеза речи не так давно (например), они уже успели обогнать классические подходы и с каждым годам испытывают на себе всё новые и новый задачи.
Например, пару месяцев назад появилась реализация синтеза речи с голосовым клонированием Real-Time-Voice-Cloning. Давайте попробуем разобраться из чего она состоит и реализуем свою многоязычную (русско-английскую) фонемную модель.
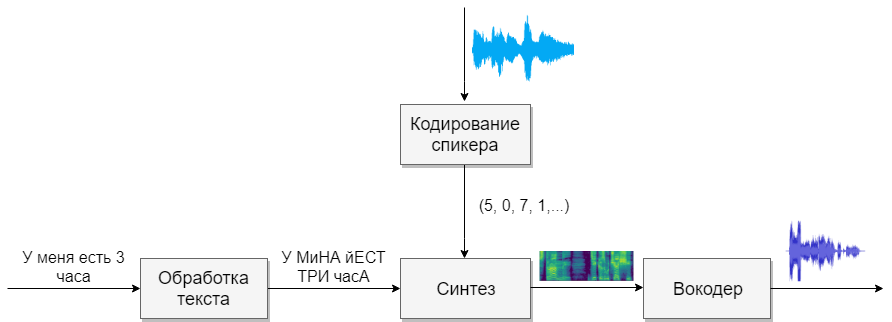
Наша модель будет состоять из четырёх нейронных сетей. Первая будет преобразовывать текст в фонемы (g2p), вторая — преобразовывать речь, которую мы хотим клонировать, в вектор признаков (чисел). Третья — будет на основе выходов первых двух синтезировать Mel спектрограммы. И, наконец, четвертая будет из спектрограмм получать звук.

1. Масштабируемость / Scalability
2. Балансировка нагрузки / Load Balancing

Есть ряд платных решений по переводу речи в текст (Automatic Speech Recognition). Сравнительно малыми усилиями можно сделать свое решение, — обучить на целевых данных end2end модель (например, из фреймворка NeMo от NVIDIA) или гибридную модель типа kaldi. Сверху понадобится добавить расстановку пунктуации и денормализацию для улучшения читаемости ("где мои семнадцать лет" → "Где мои 17 лет?").
Модель заслуживает внимания так как умеет делать очень много "из коробки". Давайте разберемся подробнее как она устроена и научимся ей пользоваться.
Недавно в открытый доступ была выложена мультиязычная модель whisper от OpenAI. Попробовал ее large вариант на нескольких языках и расшифровал 30 выпусков "Своей игры". Результат понравился, но есть нюансы. Модель транскрибирует тексты вместе с пунктуацией и капитализацией, расставляет временные метки, умеет генерировать субтитры и определять язык. Языков в обучающем датасете порядка ста. Чтобы прикинуть по качеству, нужно посмотреть на их распределение — данных на 100 часов и более было лишь для 30 языков, более 1000 ч. — для 16, ~10 000 часов — у 5 языков, включая русский.

Привет, Хабр! Это Миша Степнов, руководитель центра R&D Big Data в МТС Диджитал. Машинное обучение и технологии искусственного интеллекта постоянно развиваются — так что специалистам этой сферы приходится за ними поспевать. Держать руку на пульсе помогают в том числе книги. Сегодня поделюсь подборкой из шести книг по машинному обучению, которые будут интересны начинающим (и не только) специалистам.

Опенсорсные модели становятся всё объёмнее, поэтому потребность в надёжной инфраструктуре для выполнения крупномасштабного обучения ИИ сегодня как никогда высока. Недавно наша компания выполнила fine-tuning модели LLaMA 3.1 405B на GPU AMD, доказав их способность эффективно справляться с крупномасштабными задачами ИИ. Наш опыт был крайне положительным, и мы с радостью выложили всю свою работу на GitHub в опенсорс.
GPU AMD, и в особенности серия MI300X — это серьёзная альтернатива ИИ-оборудованию NVIDIA, обеспечивающая больше производительности на вложенный доллар. Наша система состояла из одного узла с 8 GPU AMD MI300x, а для fine-tuning мы использовали JAX. В этой статье мы расскажем всю историю fine-tuning LLaMA 405B, в том числе и подробности шардинга параметров и реализации LoRA.

Сейчас расскажу как можно обойтись без платных консультаций менторов, коучей, тренеров и прочих уважаемых господ, которых на этой площадке не очень жалуют.
Я собрал почти два десятка популярных задач, которые вам предложат решить за деньги. Давайте попробуем сделать это бесплатно при помощи нейросетки. Открывайте окошко ChatGPT и тестируйте готовые промпты из списка.

Что если мы скажем вам, что отладчик может стать не просто инструментом для поиска ошибок, а настоящим «режимом бога» в мире кода?
В новом переводе от команды Spring АйО рассматривается, как можно исследовать память приложения и изменить его функциональность, при этом не затрагивая исходного кода, а используя только лишь отладчик IntelliJ IDEA.



Всем привет!
Flux.1 D — это мощная модель для генерации изображений по текстовому описанию. Меня зовут Вандер, я куратор клуба по нейросети Fooocus и нейро-энтузиаст, и сегодня мы разберемся, почему вам точно стоит обратить внимание на свежеиспеченную Flux.
Разработчики Flux - бывшие создатели Stable Diffusion и Stable Diffusion XL - Робин Ромбах и Андреас Блаттман. Оба выступали за идею, но компания преследовала только коммерческие интересы Как итог - произошел конфликт и ключевые фигуры покинули Stability AI. Недавно ими была создана новая компания The Black Forest Team, которая и представила нам Flux.
Flux основана на 12-миллиардном трансформере и использует инновационный подход, так что достигать высокой производительности и качества изображения возможно даже при запуске на бытовых видеокартах.
Модель очень хорошо следует промпту и распознает текст.
В статье мы посмотрим, как запустить Flux онлайн и локально, а так же на ее возможности.

Notion объявили, что уходят из России и 9 сентября блокируют аккаунты пользователей.
Пока не понятно до конца, касается ли это в том числе пользователей, которые используют бесплатный функционал.
Для любителей Ноушена это большая проблема, для любителей Обсидиана это возможность сказать: "Мы же вам говорили" и начать хвастаться своими кастомными обсидианами.
Я сам долгое время пользовался Ноушеном. Первое знакомство было умопомрачительно, захватывающе. Чего только стоят мои конспекты с футбольными тактиками, где я ковертировал видео с матчей и тренировок в гифки, а потом добавлял к конспектам.
Год назад перевёл все свои заметки в Обсидиан. Причина простая: Обсидиан может гораздо больше вещей, чем Notion.
О том, почему не стоит расстраиваться и даже наоборот, открыть большой, новый мир возможностей...

Насколько ваш английский хорош, чтобы комфортно общаться в профессиональной среде? Или просто воспринимать информацию по нужной вам теме из первоисточника?
Чтобы иметь обоснованное представление об этом, предлагаю воспользоваться гайдом из 100 слов наиболее часто встречающихся в теме IT. Этот список наработан мною за 2 года работы с видео и статьями из таких изданий, как MIT, TechLife News, Bloomberg, Science Today, Harvard Business Review.
Слова разделены по рубрикам и к каждому слову добавлены описание на английском, перевод и пример употребления. В отдельных случаях указана транскрипция, чтобы вы обратили внимание на правильное произношение.
Можно ли выучить английский по списку слов? Нет, конечно. Но по нему можно оценить в процентном соотношении, сколько из 100 вам уже известно.
Важно: не воспринимайте перевод слишком буквально и попробуйте предложить свой, исходя из описания на английском.

Всем привет, меня зовут Денис, я тимлид команды дизайна в DLS, а также ревьюер в Яндекс Практикуме на курсах «Дизайнер интерфейсов» и «Дизайнер мобильных приложений». В этой статье я хочу поделиться подборкой нейросетей для коммуникационных и графических дизайнеров, которые работают с векторной и растровой графикой. А в конце расскажу, какой шаблон помогает мне сделать хороший промт.

«Скажите, какие основные преимущества микросервисов и почему?». Вероятно, это самых популярный вопрос последних 6–10 лет на любом собеседовании для бэкенд разработчика. Каким-то чудом он даже обогнал: «Назовите три принципа ООП» и «Чем отличается класс от объекта».
Подборка для тех, кто пробовал использовать нейросети в своих задачах, но разочаровался в них: непонятно, как чат-бот вообще может помогать с чем-то серьёзным.


Привет, Хабр! Меня зовут Александр Бардаш, я главный архитектор интеграционных платформ в МТС. Сегодня расскажу, почему ИТ-архитекторам важно хотя бы иногда всегда читать книги, и поделюсь подборкой для начинающих. Жду вас под катом и в комментариях!

В моей базе знаний 4 000 заметок.
Да, у меня немного съехала крыша на этой теме. Но решение создать систему для ведения заметок три года назад — пока что лучшая из моих интеллектуальных инвестиций. В этом посте хочу поделиться, зачем я это делаю, в каком формате и какие полезные практические кейсы для себя нашел. Тема бездонная, на самом деле. Можете взять часть идей и развить у себя.