
Читать далее

User

Статья о том, как внедрить и как продуктивно использовать систему статусов в персональных проектах.
Гайд предназначен для пользователей Obsidian. Однако, если вы к таковым не причисляетесь, то можете ознакомиться только с описанием системы статусов. Возможно, что вам сам подход понравится и у вас впоследствии получится адаптировать его в своих инструментах.

Как известно, генерация в нейросети Stable Diffusion осуществляется по текстовому описанию с использованием различных обученных моделей. Кроме того, в качестве первичного источника можно использовать произвольное изображение (генерация по скетчу). Подробно об установке и подробностях работы можно ознакомиться в многочисленных статьях и видеообзорах в интернете. Отмечу только, что в работе нейросети при генерации используется цветовой шум – это стало отправной точкой моего небольшого исследования, которым я хочу с вами поделиться.
В процессе работы с нейросетью мною были использованы как текстовые описания (промты), так и скетчи – примитивные наброски, описывающей некую общую концепцию будущего изображения. При генерации по скетчу в настройках нейросети можно задавать значение параметра «Denoising strength» (принимает значения от 0 до 1). Параметр указывает силу влияния наброска на первичную генерацию изображения. Чем ближе значение к единице, тем меньше влияние. Как показала практика, при значениях ниже 0.5 практически на всех моделях и при любых прочих параметрах генерации, финальное изображение максимально упрощалось и стремилось к наброску. При значениях в диапазоне от 0.5 до 0.6 чаще получались картинки в мультяшном стиле, при этом негативные промты на результат влияния почти не оказывали. Реалистичные модели, как правило, при низких значениях дают результаты с большим количеством искажений, при больших – сценарий финального изображения очень быстро уходит от того, что изображено на наброске.
Я проанализировал по 500 статей ? из топов VC, Пикабу и Хабра за последний год и сделал выводы для своих материалов. Все выводы можно применять сейчас — я уже их применяю и мои статьи попадают в Популярное и Горячее, уходят в рассылку VC, паблики ВК VC, Хабра и Пикабу.
Представьте себе, что в мире есть волшебное средство, которое в 7 раз повышает эффективность обучения — быстрее выучить английский, быстрее освоить программирование, быстрее понять что угодно в мире.
Удивительно, но такое средство было найдено в 1990 году американским социологом Майклом Хоу. Он провел серию тестов среди студентов и определил, что пользователи «волшебного средства» в 7 раз лучше запоминали материал, легко вспоминали факты и легко применяли знания на практике.
Тот, кто использовал «волшебное средство» был наголову выше обычных студентов. «Обычные» хуже помнили материал и хуже его понимали, более того, даже одаренные отличники были слабее тех, кто использовал это «волшебное средство».
Это удивительное средство...


Меня зовут Михаил Кириченко. Я разрабатываю клиентскую часть в компании Bimeister.
В этой статье хочу поделиться своим опытом и практиками, которые мне приходилось применять в своей работе, а главное, ответить на вопрос: как лучше подходить к построению интерфейсов, чтобы не проиграть с производительностью при скроллинге.
Серверы в опасности!
Вы знали, что каждый включенный и подключенный к сети сервер постоянно подвергается атакам? Это могут быть разные атаки и с разной целью.
Это может быть перебор портов с целью найти открытые от какой-то компании, которая позиционирует себя борцом за безопасность, но которая собирает статистику открытых портов на будущее по всем доступным IP (например Censys).
Может быть Shodan, который тоже собирает базу о том, где какие порты открыты, и отдаёт эту информацию любому заплатившему. И могут быть менее известные компании, которые работают в тени. Представьте, кто-то ходит по всем домам и переписывает модели замков входных дверей, дергает за дверь и выкладывает это в публичный доступ. Дичь! Но тоже самое происходит в интернете тысячи раз в секунду.
Кроме компаний могут быть бот-сети, перебирающие порты для поиска чего-то конкретного или для подготовки к целевым атакам.
Ну и собственно целевые атаки, во время которых ваши серверы в первую очередь тестируются на наличие открытых портов, а затем производятся атаки на найденные сервисы. Это может быть подбор эксплоитов для использования известных дыр или пока неизвестных 0-day, как и обычный DDoS.
Во всех этих сценариях используется предварительный перебор открытых портов. Скорее всего применение nmap или подобных утилит в каких-то скриптах.
Как защитить сервер от сканирования портов без CloudFlare и подобных прослоек?

Привет, меня зовут Дмитрий Дружков, я тимлид фронтенд команды в Утконос Онлайн. В этой статье я расскажу, чем полезен Angular Universal в e-commerce проектах, как выбрать вид рендеринга, как выглядит первоначальная настройка технологии на примере нашего сайта и шаги по ускорению, а также раскрою плюсы и минусы Universal. Статья будет интересна тем, кто:
Требования к качеству, несмотря на свой небольшой размер, очень сильно влияют на реализуемость всей совокупности требований, на трудоёмкость, длительность и стоимость реализации, а следовательно окупаемость инвестиций в разработку и в целом возможную успешность проекта.
Это та причина, по которой многие подрядчики стараются избегать таких требований, как огня, что перекладывает риски во времени на более поздние этапы и на заказчика.
Но в мире честных, открытых отношений выгоднее заранее обсудить эти аспекты, чем потом с удивлением спорить при сдаче, что система тормозит, в ТЗ про это ничего не сказано, «вы же профессионалы» и всё такое.
Стандарты по программной и системной инженерии предлагают десятки видов атрибутов качества системы, а заказчики требуют, чтобы система была удобной, быстрой, надёжной и безопасной.
При этом остаётся прагматический вопрос — а что именно писать в требования, чтобы они были полезными, измеримыми, реализуемыми?
С точки зрения системной инженерии, требования к качеству программной системы являются разновидностью системных ограничений (constraints) и в этом они отличаются от требований к способностям (capabilities) системы, в мире ИТ обычно называемых «функциональными».
Пока что умение специалистов и команд выявлять и формулировать такие ограничения представляет собой скорее искусство, а не ремесло, и не инженерию.
Давайте попробуем сделать это хотя бы ремеслом.

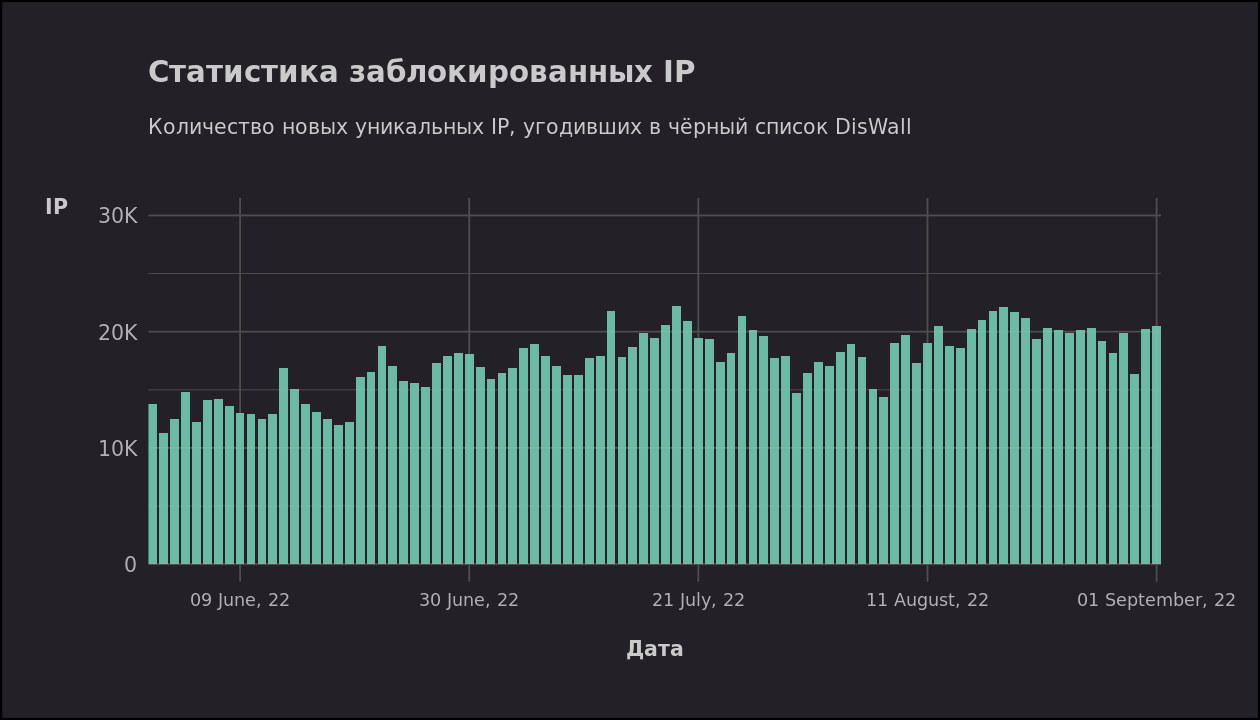
Помогая пользователям NGINX с разрешением проблемных ситуаций, мы поняли, что большинство из них часто совершает одни и те же ошибки конфигурации. Более того, подобные ситуации вполне могут возникнуть даже у самих инженеров NGINX! В этой статье рассмотрим 10 наиболее распространенных ошибок и объясним как их исправить.

Небольшой обзор стандартных средств запуска бэкграунд-задач в аспнет приложениях — что есть, чем отличается, как пользоваться. Встроенный механизм запуска таких задач строится вокруг интерфейса IHostedService и метода-расширения для IServiceCollection — AddHostedService. Но есть несколько способов реализовать фоновые задачи через этот механизм (и ещё несколько неочевидных моментов поведения этого механизма).
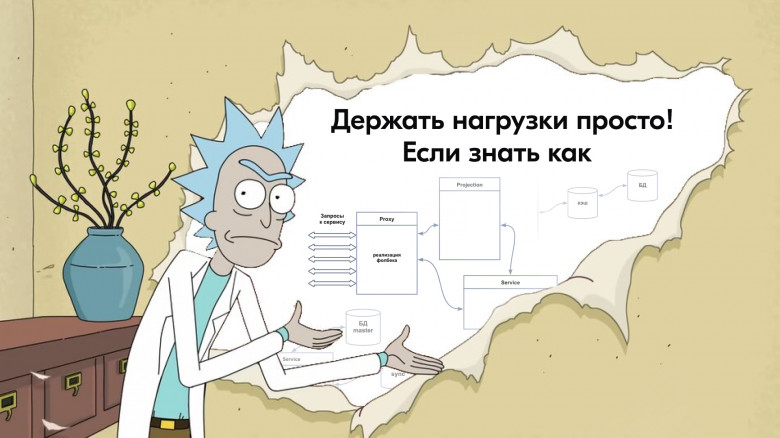
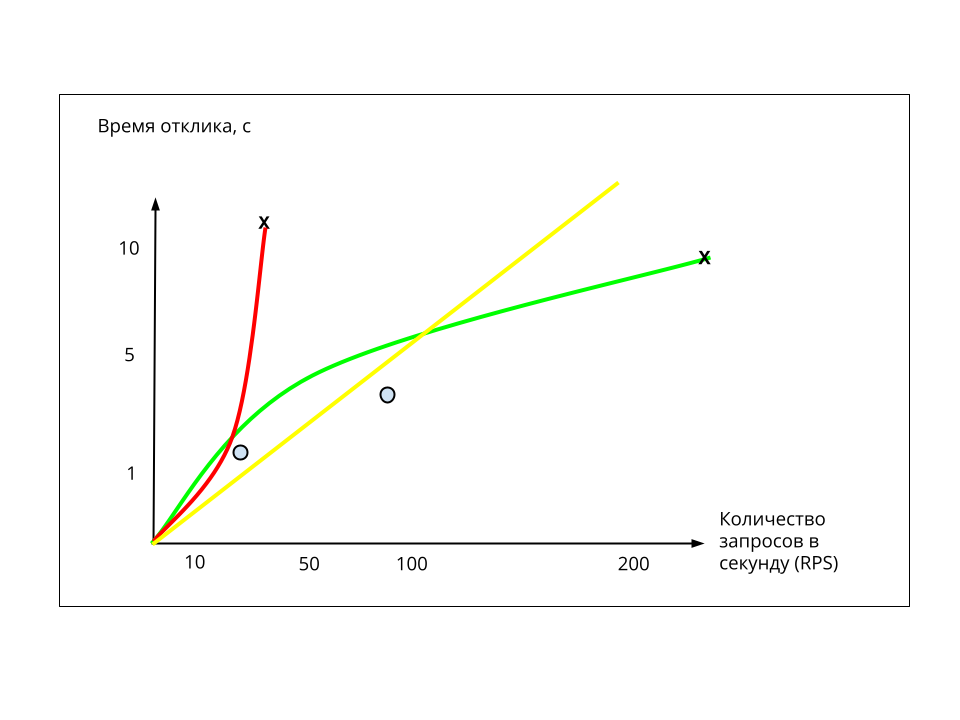
Одни из важнейших характеристик качественного IT-продукта — отказоустойчивость и работоспособность под нагрузками. Когда речь идёт о пользовательских финансовых операциях, это важно вдвойне, а если к уравнению добавить хайлоад — втройне.
Я разрабатываю сервисы в команде платежей Ozon. Мы много времени уделяем тому, чтобы все транзакции были обработаны корректно, даже если речь идёт о нагрузке в 2к платежей в минуту (именно столько у нас было в пике в период ноябрьских распродаж). Кстати, сейчас, по результатам нагрузочного тестирования, мы выдерживаем 13к платежей в минуту.
Для этого мы готовимся заранее: пересматриваем архитектуру, дорабатываем сервисы, рефакторим код, кэшируем и оптимизируем базы данных. Серебряной пули тут нет, но могу поделиться техниками, которые помогли нам избежать возможных проблем, — будет полезно всем, кто готовит свои сервисы с прицелом на работоспособность под нагрузками.

Всем привет! Сегодня хочу поделиться нашими мыслями относительно того, как защититься от санкций палок в колёсах в современных условиях. Собственно, что мы имеем ввиду? Речь идёт о том, что в крупных проектах часто есть единые точки отказа в процессах CI/CD, это может быть как простой репозиторий кодом, так и различные конвеерные системы сборки кода и доставки его в рабочие окружения. Если мы говорим про системный софт, то его можно просто перестать обновлять, запретить ему ходить "наружу", но в данной статье мы поговорим про внешние репозитории с кодом.
Если вы сталкивались с CORS, то знаете всю ту боль, которую испытывает разработчик, когда нужно сходить к API на другом домене. Если конфигурация сервера не доступна для настройки, то использовали какое-нибудь решение на основе не менее популярного решения cors-anywhere.
Как простая обработка XML-файлов может стать дефектом безопасности? Каким образом блог, развёрнутый на вашей машине, может стать причиной утечки данных? Сегодня мы ответим на эти вопросы и разберём, что такое XXE и как эта уязвимость выглядит в теории и на практике.

В статье показана важность учёта будущего развития бизнеса при проектировании системы.
В первой части показано, что показатель стоимости будущих доработок системы может рассматриваться как ключевой при разработке ИТ-систем.
Во второй части, показано, как меняется фокус анализа в зависимости от модели поддержки будущих изменений в системе. Описаны изменения в процессе проектирования, которые появляются при ориентации на будущие изменения в бизнесе. Новый подход к проектированию даёт возможность моделировать систему в разных стилях, которые перечислены в статье.

Речь в статье пойдет не только о финансовом планировании, а скорее здесь будут описаны мои злоключения, в результате которых и родился мой будущий финансовый план на следующий год. А, ну еще и о том, как я смог заработать лишнюю 13 зарплату по факту ничего не делая.
Если вы читаете статью только ради финансовой модели, то она лежит здесь (см. таблицу).

MongoDB — одна из самых популярных баз данных с открытым исходным кодом. К сожалению, как следствие мы имеем огромное количество неправильно настроенных и незащищенных разверток MongoDB по всему миру. Только за последние пару лет мы стали свидетелями нескольких крупных взломов, обнаживших уязвимости тысяч баз данных MongoDB в сети, что сделало их легкой добычей для злоумышленников.
Однако все может быть по-другому. Есть множество мер, которые вы можете предпринять для обеспечения безопасности ваших данных в MongoDB — от защиты периметра сети до включения Strict-Transport-Security, чтобы использовать такие фичи, как расширенное управление пользователями в MongoDB и систему контроля доступа на основе ролей (Role-Based Access Control — RBAC).
В этой статье мы рассмотрим некоторые из наиболее популярных способов защиты кластера MongoDB.

Всем привет!
В этой статье я хотел бы рассказать о некоторых мерах, которые мы применяем (ну, или почти применяем) в ДомКлик для обеспечения надежности работы наших сервисов. Честно говоря, возможно, какие-то из этих процедур избыточны, но ежегодный аудит и постоянные проверки заставляют нас дуть на воду и готовиться к худшему.
Также я постараюсь подробно отразить свою субъективную оценку по каждому из перечисленных мероприятий, на предмет сложности реализации и эффективности.