
Вы, вероятно, представляли ее себе как целый орган — грандиозное сооружение длиной в пару метров с сотнями и тысячами клавиш. На самом деле, большинство китайцев используют обычную клавиатуру с латинской раскладкой QWERTY. Но как с помощью нее можно набрать такое несметное количество различных иероглифов? Мы попросили рассказать об этом нашу сотрудницу Юлию Дрейзис. Ее с Китаем связывают и давняя любовь, и работа.
За несколько тысяч лет хитроумные китайцы успели довести количество иероглифов до 50000 с хвостиком. И хотя число нужных в повседневной жизни знаков не измеряется десятками тысяч, все равно, как ни крути, стандартный набор старой типографии — 9000 литер.
Долгое время набор осуществлялся по принципу «на каждый иероглиф — отдельный печатный элемент». Поэтому работать приходилось с машинками-монстрами вроде такой:

Печатная машинка фирмы «Шуангэ», 1947 год (принцип действия придуман японцем Киота Сугимото в 1915 году).
История вопроса: печатные машинки
За несколько тысяч лет хитроумные китайцы успели довести количество иероглифов до 50000 с хвостиком. И хотя число нужных в повседневной жизни знаков не измеряется десятками тысяч, все равно, как ни крути, стандартный набор старой типографии — 9000 литер.
Долгое время набор осуществлялся по принципу «на каждый иероглиф — отдельный печатный элемент». Поэтому работать приходилось с машинками-монстрами вроде такой:
Печатная машинка фирмы «Шуангэ», 1947 год (принцип действия придуман японцем Киота Сугимото в 1915 году).


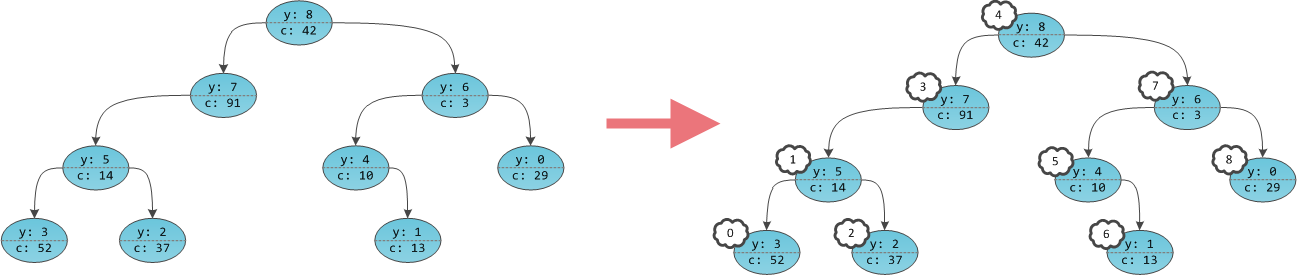
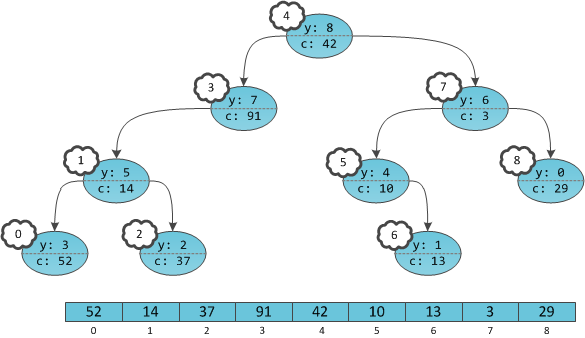

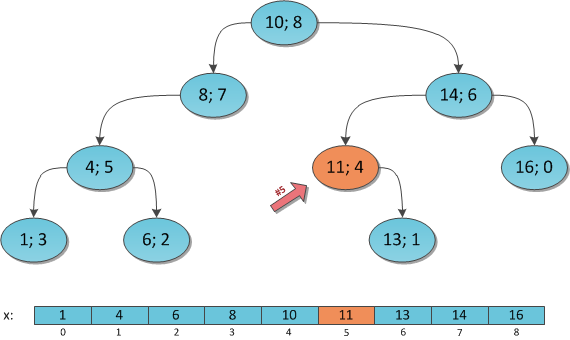
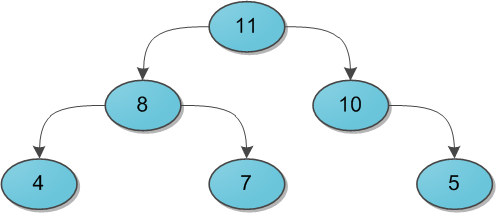
 .
.  .
.
 Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.
Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.