К написанию статьи подтолкнул вот
этот комментарий. А точнее, одна фраза из него.
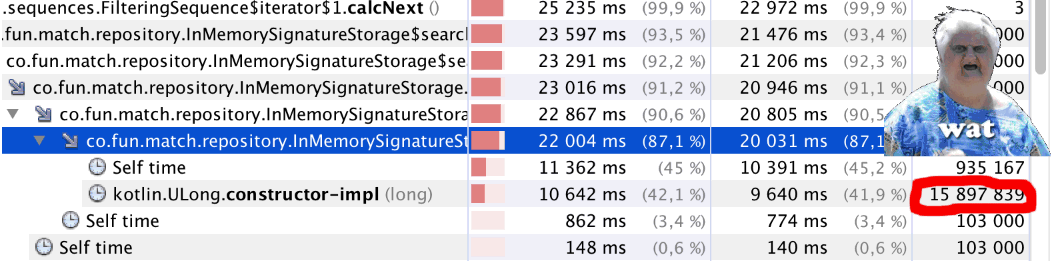
… расходовать память или такты процессора на элементы в миллиардных объёмах — это нехорошо…
Так сложилось, что в последнее время мне именно этим и пришлось заниматься. И, хотя, случай, который я рассмотрю в статье, довольно частный — выводы и применённые решения могут быть кому-нибудь полезны.
Немного контекста
Приложение iFunny имеет дело с колоссальным объёмом графического и видеоконтента, а нечёткий поиск дубликатов является одной из очень важных задач. Сама по себе это большая тема, заслуживающая отдельной статьи, но сегодня я просто немного расскажу о некоторых подходах к обсчёту очень больших массивов чисел, применительно к этому поиску. Конечно же, у всех разное понимание «очень больших массивов», и тягаться с Адронным коллайдером было бы глупо, но всё же. :)
Если совсем коротко про алгоритм, то для каждого изображения создаётся его цифровая подпись (сигнатура) из 968 целых чисел, а сравнение производится путем нахождения «расстояния» между двумя сигнатурами. Учитывая, что объём контента только за два последних месяца составил порядка 10 миллионов изображений, то, как легко прикинет в уме внимательный читатель, — это как раз те самые «элементы в миллиардных объёмах». Кому интересно — добро пожаловать под кат.




























