Уважаемые читатели, доброго дня!
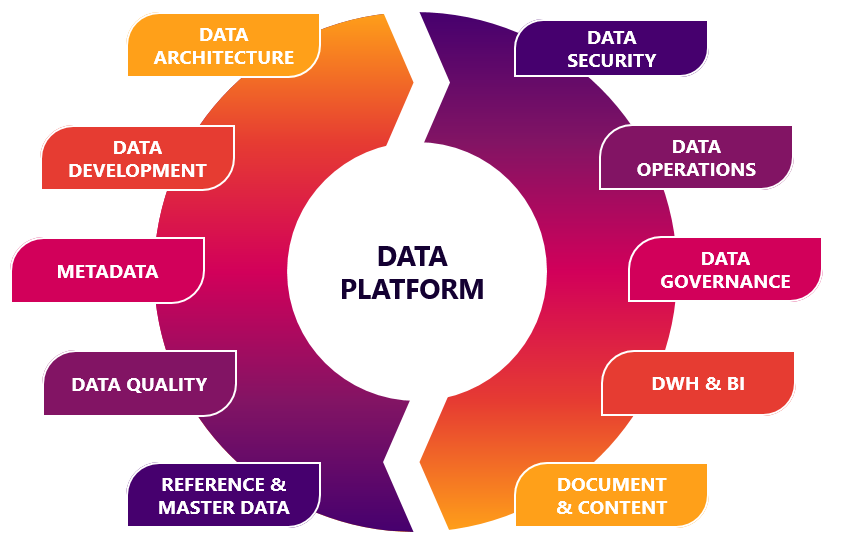
Задача построения ИТ-платформ для накопления и анализа данных рано или поздно возникает у любой компании, в основе бизнеса которой лежат интеллектуально нагруженная модель оказания услуг или создание технически сложных продуктов. Построение аналитических платформ — сложная и трудозатратная задача. Однако любую задачу можно упростить. В этой статье я хочу поделиться опытом применения low-code-инструментов, помогающих в создании аналитических решений. Данный опыт был приобретён при реализации ряда проектов направления Big Data Solutions компании «Неофлекс». Направление Big Data Solutions компании «Неофлекс» с 2005 года занимается вопросами построения хранилищ и озёр данных, решает задачи оптимизации скорости обработки информации и работает над методологией управления качеством данных.
Избежать осознанного накопления слабо и/или сильно структурированных данных не удастся никому. Пожалуй, даже если речь будет идти о малом бизнесе. Ведь при масштабировании бизнеса перспективный предприниматель столкнётся с вопросами разработки программы лояльности, захочет провести анализ эффективности точек продаж, подумает о таргетированной рекламе, озадачится спросом на сопроводительную продукцию. В первом приближении задача может быть решена «на коленке». Но при росте бизнеса приход к аналитической платформе все же неизбежен.
Однако в каком случае задачи аналитики данных могут перерасти в задачи класса «Rocket Science»? Пожалуй, в тот момент, когда речь идёт о действительно больших данных.
Чтобы упростить задачу «Rocket Science», можно есть слона по частям.
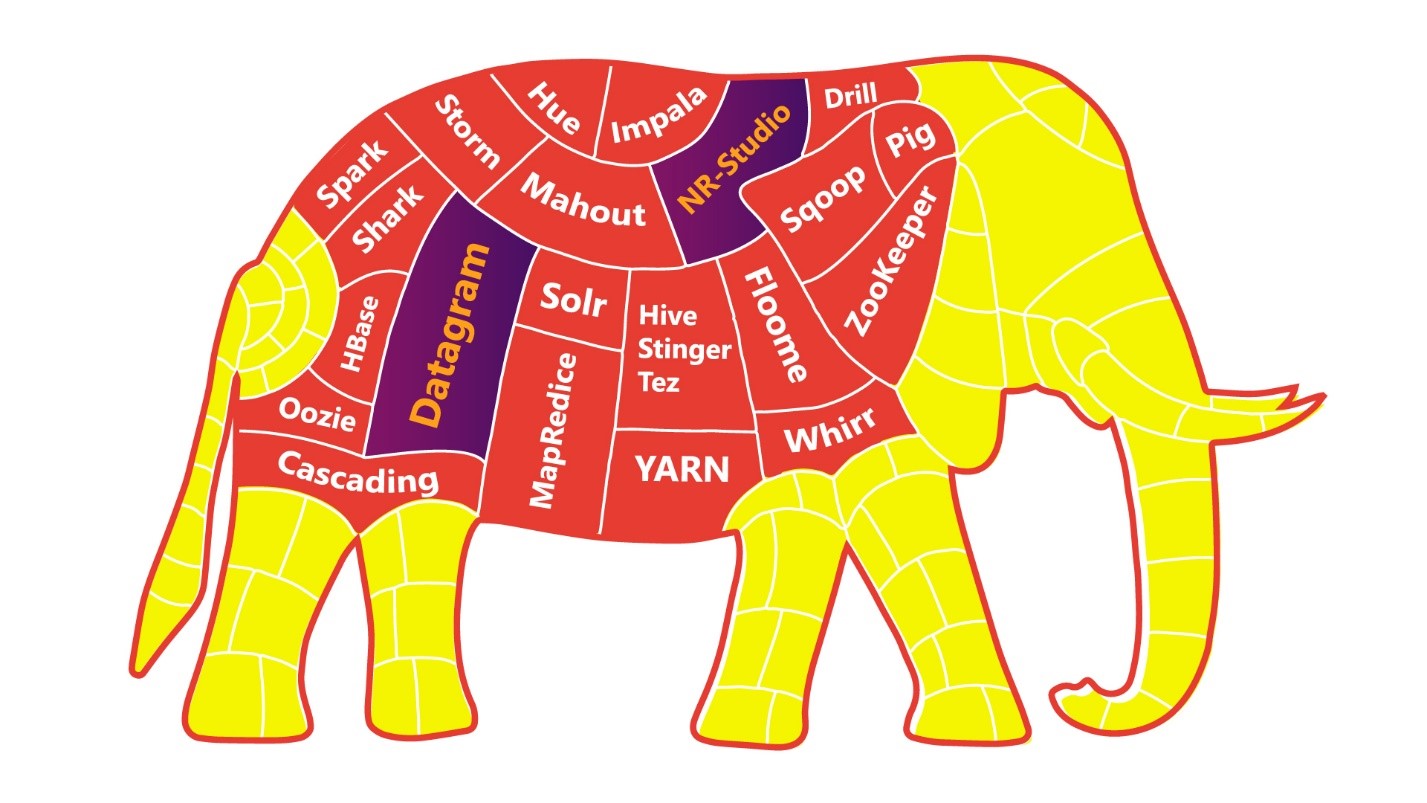
Чем большая дискретность и автономность будет у ваших приложений/сервисов/микросервисов, тем проще вам, вашим коллегам и всему бизнесу будет переваривать слона.
К этому постулату пришли практически все наши клиенты, перестроив ландшафт, основываясь на инженерных практиках DevOps-команд.
Задача построения ИТ-платформ для накопления и анализа данных рано или поздно возникает у любой компании, в основе бизнеса которой лежат интеллектуально нагруженная модель оказания услуг или создание технически сложных продуктов. Построение аналитических платформ — сложная и трудозатратная задача. Однако любую задачу можно упростить. В этой статье я хочу поделиться опытом применения low-code-инструментов, помогающих в создании аналитических решений. Данный опыт был приобретён при реализации ряда проектов направления Big Data Solutions компании «Неофлекс». Направление Big Data Solutions компании «Неофлекс» с 2005 года занимается вопросами построения хранилищ и озёр данных, решает задачи оптимизации скорости обработки информации и работает над методологией управления качеством данных.
Избежать осознанного накопления слабо и/или сильно структурированных данных не удастся никому. Пожалуй, даже если речь будет идти о малом бизнесе. Ведь при масштабировании бизнеса перспективный предприниматель столкнётся с вопросами разработки программы лояльности, захочет провести анализ эффективности точек продаж, подумает о таргетированной рекламе, озадачится спросом на сопроводительную продукцию. В первом приближении задача может быть решена «на коленке». Но при росте бизнеса приход к аналитической платформе все же неизбежен.
Однако в каком случае задачи аналитики данных могут перерасти в задачи класса «Rocket Science»? Пожалуй, в тот момент, когда речь идёт о действительно больших данных.
Чтобы упростить задачу «Rocket Science», можно есть слона по частям.
Чем большая дискретность и автономность будет у ваших приложений/сервисов/микросервисов, тем проще вам, вашим коллегам и всему бизнесу будет переваривать слона.
К этому постулату пришли практически все наши клиенты, перестроив ландшафт, основываясь на инженерных практиках DevOps-команд.











