
Вот интересная демонстрация возможностей afl; меня реально удивило, что она работает!
В сущности, я создал текстовый файл только со словом "hello" и попросил фаззер выдавать поток в программу, которая ожидает на входе изображение JPEG (djpeg это простая утилита, которая идёт вместе с распространённой графической библиотекой IJG jpeg; libjpeg-turbo тоже должна подойти). Конечно, мои входные данные не похожи на валидное изображение, так что утилита быстро отвергает их:
$ mkdir in_dir
$ echo 'hello' >in_dir/hello
$ ./afl-fuzz -i in_dir -o out_dir ./jpeg-9a/djpegВ сущности, я создал текстовый файл только со словом "hello" и попросил фаззер выдавать поток в программу, которая ожидает на входе изображение JPEG (djpeg это простая утилита, которая идёт вместе с распространённой графической библиотекой IJG jpeg; libjpeg-turbo тоже должна подойти). Конечно, мои входные данные не похожи на валидное изображение, так что утилита быстро отвергает их:
$ ./djpeg '../out_dir/queue/id:000000,orig:hello'
Not a JPEG file: starts with 0x68 0x65









 В блоге Intel мы уже неоднократно
В блоге Intel мы уже неоднократно 

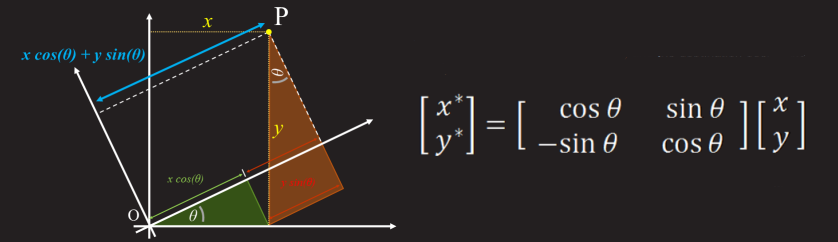

 Я люблю графические отладчики. Обычные я тоже люблю, но графические — больше. Они дают ощущение сродни заглядыванию за кулисы театра во время выступления: «ага, вот эта декорация крепится так, а этот луч света падает отсюда, а у этого шкафа нет задней стенки...». Графический отладчик пробрасывает мостик понимания между текстовым кодом приложения и полученной красивой картинкой.
Я люблю графические отладчики. Обычные я тоже люблю, но графические — больше. Они дают ощущение сродни заглядыванию за кулисы театра во время выступления: «ага, вот эта декорация крепится так, а этот луч света падает отсюда, а у этого шкафа нет задней стенки...». Графический отладчик пробрасывает мостик понимания между текстовым кодом приложения и полученной красивой картинкой.  Мы уже
Мы уже