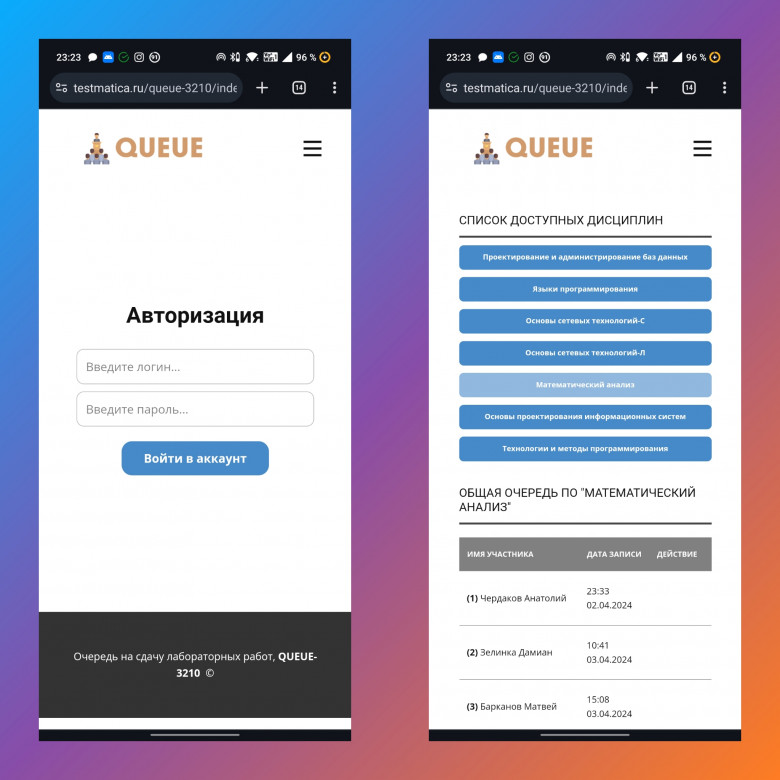
Учеба в политехе заключается в сдаче лабораторных работ. Буквально. Очень редко бывает такое, что на парах мы чему-то учимся, зачастую все завязано на самообучении. Грубо говоря, вот вам методичка, разбирайтесь сами, через неделю дедлайн.
В связи с этим мы столкнулись с очередями на сдачу этих лабораторных. Сначала просто писали в общий чат, кто каким будет в очереди (например, "я первый", "я вторая", "я третий" и т.д.). Далее решили создать расшаренную таблицу в гугле для формирования очередей. Однако долго она тоже не прожила, так как со временем появились "умники", которые стали ставить себя первыми в очереди, сдвигая остальных вниз. Потом общий доступ для таблицы закрыли, и было принято решение для записи на сдачу писать старосте, он, в свою очередь, будет добавлять студентов в список. Но староста группы не может быть постоянно на связи, иными словами, оперативно добавиться в очередь было просто невозможно.
В связи с этим я задумался над созданием автоматизированной очереди. В качестве стека основных технологий выбрал HTML5+CSS3 для фронтенда, PHP для бэкенда. В качестве СУБД был выбран phpMyAdmin (SQL-DB). В первую очередь, конечно, необходимо было продумать структуру базы данных. Предметная область информационной системы уже была сформулирована: "Очередь на сдачу лабораторных работ с возможностью записи по отдельным дисциплинам, удаления своей записи. Учет истории создания записи, удаления записей, включая время записи. Возможность смены пароля, просмотра профиля." Даталогическая модель БД была построена в MySQL Workbench 8.0 CE в нотации IDEF1X.

 Привет, Хаброжители!
Привет, Хаброжители!