GPU-вычисления в браузере на скорости нативного приложения: марширующие кубы на WebGPU

WebGPU — это мощный GPU-API для веба, поддерживает продвинутые рендеринговые конвейеры и вычислительные конвейеры GPU. WebGPU ключевым образом отличается от WebGL своей поддержкой вычислительных шейдеров и буферов хранения данных. В WebGL такие возможности отсутствуют, а WebGPU, в свою очередь, позволяет целиком выполнять в браузере мощные приложения, требующие вычислений на GPU. Речь может идти о самых разных приложениях, от GPGPU (напр., симуляции, обработка/анализ данных, машинное обучение, т.д.) до конвейеров рендеринга на основе GPU-вычислений — а также о многих других приложениях в этом спектре.
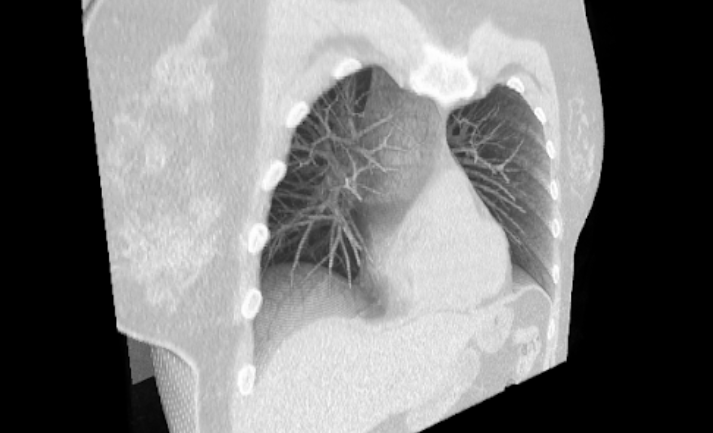
В этой статье мы оценим вычислительную мощность WebGPU, сравнив её с показателями Vulkan. Для этого мы реализуем классический алгоритм «марширующие кубы» (Marching Cubes) для WebGPU. Алгоритм марширующих кубов почти без оговорок относится к чрезвычайно параллельным, в составе этого алгоритма выполняется два глобальных шага редукции, необходимых для синхронизации местоположений рабочих элементов и вывода потоков. Поэтому данное решение — отличный вариант GPU-параллельного алгоритма, который стоит первым делом попробовать на новой платформе. Дело в том, что он достаточно сложен, чтобы API испытал давление сразу по нескольким направлениям сверх элементарных параллельных операций диспетчеризации в ядре. При этом он не столь сложен, чтобы на его реализацию требовалось существенное время, а также он не превращается в узкое место из-за ограничения производительности ЦП.