
Почему на собеседованиях так часто спрашивают про связные списки
3 мин
Перевод
Примечание переводчика: оригинальная статья опубликована в серии твитов
Вероятно, вы уже читали кучу объяснений, почему обработка связных списков — плохой вопрос для собеседования. Я же в первую очередь хочу объяснить, откуда он вообще взялся. Всем пристегнуться, погружаемся втеорию игр ИСТОРИЮ!
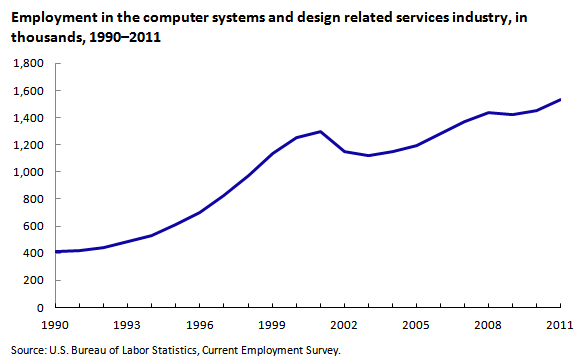
Хотя индустрия программного обеспечения процветала в 80-е годы, но действительно взлетела в 90-е. В это десятилетие число работников отрасли в США утроилось и превысило миллион человек. Со взрывным ростом пришла необходимость нанимать массу сотрудников и оценивать их.
Что нужно оценить? Ну, в первую очередь, знание языков. Согласно TIOBE, в 1986−2006 годы самым популярным языком в мире был C, далее следовал C++. К 2006 году Java вышла на первое место, но C остался рядом.
C работал близко к железу без лишних абстракций. Пустой словарь Python расходует аж 288 байт, то есть 5% всего объёма памяти первого поколения Apple II. Абстракции слишком дороги, слишком много накладных расходов. Если вам нужна сложная структура данных, вы должны построить её самостоятельно с помощью массивов, структур и указателей.
Вероятно, вы уже читали кучу объяснений, почему обработка связных списков — плохой вопрос для собеседования. Я же в первую очередь хочу объяснить, откуда он вообще взялся. Всем пристегнуться, погружаемся в
Хотя индустрия программного обеспечения процветала в 80-е годы, но действительно взлетела в 90-е. В это десятилетие число работников отрасли в США утроилось и превысило миллион человек. Со взрывным ростом пришла необходимость нанимать массу сотрудников и оценивать их.
Что нужно оценить? Ну, в первую очередь, знание языков. Согласно TIOBE, в 1986−2006 годы самым популярным языком в мире был C, далее следовал C++. К 2006 году Java вышла на первое место, но C остался рядом.
C работал близко к железу без лишних абстракций. Пустой словарь Python расходует аж 288 байт, то есть 5% всего объёма памяти первого поколения Apple II. Абстракции слишком дороги, слишком много накладных расходов. Если вам нужна сложная структура данных, вы должны построить её самостоятельно с помощью массивов, структур и указателей.















{kind=link}