
Привет, Хабр! Продолжаю изучать Scala. Большинство бекендов так или иначе интегрированы с другими и делают HTTP запросы. Так как я на стек Cats и http4s ориентирован то буду рассматривать и изучать именно его. Сделаю запросы с куками, телом в json и в form, c файлом, с хедерами. Тут Hirrolot мне скорее всего минус поставит. Хочу сказать что может быть кому-то кто тоже изучает Scala будет полезна эта статья. Да и меня написание таких статей мотивирует изучать дальше. Люблю тебя малой. Расти большой не будь лапшой. Я уверен из тебя получится просто отличный инженер или даже может быть ученый в области IT. Давненько меня тут не было. В общем штормило у меня на личном фронте. С начала мы встречались обнимались и целовались с Марго. Потом мы расстались. Потом я переживал из-за этого. Потом работы навалилось. Вот так примерно у меня последние месяцы прошли. Взгрустнул, выпил и решил я написать сюда. И так, начнем.
Книга: проектирование API
1 мин
Приветики. Каждый из нас в этом этом чудесном году находит свой способ скоротать время. Я вот, например, пишу книгу. Книгу о том, что знаю и люблю — про API. (Кто я такой и какой опыт имею в разработке можно посмотреть здесь)
→ Пока что написал первую часть — о принципах проектирования API «сверху вниз»
→ PDF-версию можно скачать отсюда
Вопросы, пожелания и предложения принимаются. Книга распространяется бесплатно на условиях CC-BY-NC. You're welcome!
Haproxy — программирование и конфигурирование средствами Lua
9 мин
Сервер Haproxy имеет встроенные средства для выполнения скриптов Lua.
Язык программирования Lua для расширения возможностей различных серверов используется очень широко. Например, на Lua можно программировать для серверов Redis, Nginx (nginx-extras, openresty), Envoy. Это вполне закономерно, так как язык программирования Lua как раз и был разработан для удобства встраивания в приложения в качестве скриптового языка.
В этом сообщении я рассмотрю варианты использования Lua для расширения возможностей Haproxy.
Интегрируем web-телефон в свою систему
3 мин
Мы уже писали, как и зачем интегрировать телефонию со своей CRM/ERP/Helpdesk системой. Теперь опишем, как это сделать еще проще, добавив на свой сайт web-телефон. WebRTC-виджет позволит звонить и принимать звонки из вашего web приложения, не устанавливая никаких программ и не делая никаких настроек.

Как найти что-то в тексте
8 мин
Найти объект или распознать понятие в тексте — с этого начинается решение большинства NLP задач. Если вы проектируете поисковую систему, создаете голосового помощника или классифицируете пользовательские запросы, прежде всего вы должны разобрать входной текст и попытаться найти в нем именованные сущности, которые могут быть универсальными, такими как даты, страны и города, или специфичными для конкретной модели. Обратите внимание, мы сейчас говорим лишь о тех видах задач, для которых заранее известно, что именно вы ищете или что может встретиться в тексте.
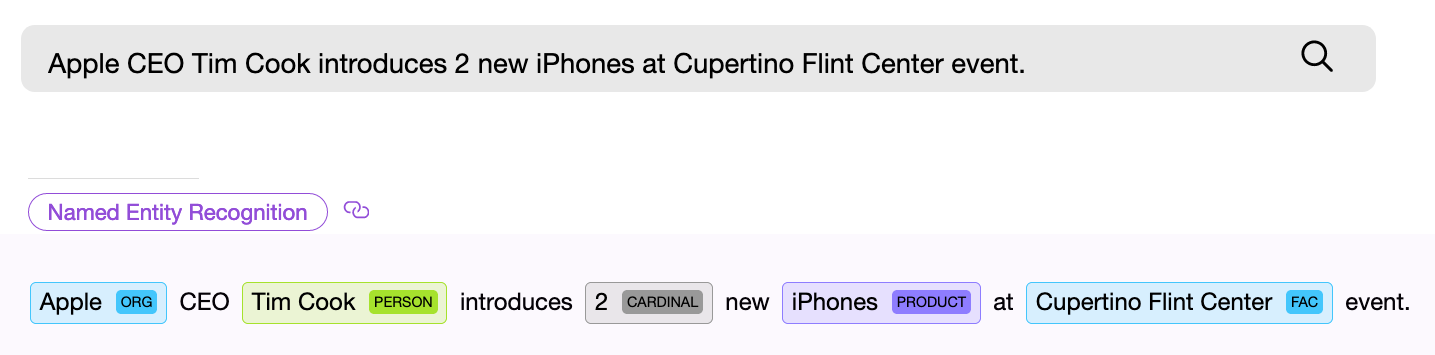
NER (named entity recognition) компонент, то есть программный компонент для поиска именованных сущностей, должен найти в тексте объект и по возможности получить из него какую-то информацию. Пример — “Дайте мне двадцать две маски”. Числовой NER компонент находит в приведенном тексте словосочетание “двадцать две” и извлекает из этих слов числовое нормализованное значение — “22”, теперь это значение можно использовать.
NER компоненты могут базироваться на нейронных сетях или работать на основе правил и каких-либо внутренних моделях. Универсальные NER компоненты часто используют второй способ.
Рассмотрим несколько готовых решений по поиску стандартных сущностей в тексте. В данной заметке мы остановимся на бесплатных или бесплатных с ограничениями библиотеках, а также расскажем о том, что сделано в проекте Apache NlpCraft в рамках данной проблематики. Представленный ниже список не является подробным и обстоятельным обзором, которых и так достаточное количество в сети, а скорее кратким описанием основных особенностей, плюсов и минусов использования этих библиотек.
NER (named entity recognition) компонент, то есть программный компонент для поиска именованных сущностей, должен найти в тексте объект и по возможности получить из него какую-то информацию. Пример — “Дайте мне двадцать две маски”. Числовой NER компонент находит в приведенном тексте словосочетание “двадцать две” и извлекает из этих слов числовое нормализованное значение — “22”, теперь это значение можно использовать.
NER компоненты могут базироваться на нейронных сетях или работать на основе правил и каких-либо внутренних моделях. Универсальные NER компоненты часто используют второй способ.
Рассмотрим несколько готовых решений по поиску стандартных сущностей в тексте. В данной заметке мы остановимся на бесплатных или бесплатных с ограничениями библиотеках, а также расскажем о том, что сделано в проекте Apache NlpCraft в рамках данной проблематики. Представленный ниже список не является подробным и обстоятельным обзором, которых и так достаточное количество в сети, а скорее кратким описанием основных особенностей, плюсов и минусов использования этих библиотек.
Современные накопители очень быстры, но плохие API это не учитывают
11 мин
Перевод

Почти десять лет я проработал в компании, создающей довольно специализированный продукт — высокопроизводительные системы ввода-вывода. Я имел возможность наблюдать за быстрой и решительной эволюцией технологий хранения данных.
В этом году я сменил работу. Окружённый в новой большой компании инженерами, имевшими опыт в разных сферах работы, я удивился тому, что у каждого из моих коллег, несмотря на выдающийся ум, сложились ложные представления о том, как наилучшим способом использовать современные технологии хранения. Даже если они и были в курсе совершенствования технологий, такие представления приводили к созданию неоптимальных архитектур.
Поразмышляв о причинах этой неувязки, я понял, что в основном устойчивость таких заблуждений вызвана следующим: даже если они проверяли свои предположения при помощи бенчмарков, то данные показывали их (кажущуюся) истинность.
Вот самые распространённые примеры таких заблуждений:
- «Вполне нормально скопировать память здесь и выполнить эти затратные вычисления, потому что это сэкономит нам одну операцию ввода-вывода, которая была бы ещё более затратной».
- «Я проектирую систему, которая должна быть быстрой. Поэтому она должна находиться в памяти».
- «Если мы разобьём эти данные на несколько файлов, то выполнение будет медленным, поскольку возникнут паттерны произвольного ввода-вывода. Нам нужно оптимизировать выполнение под последовательный доступ и осуществлять считывание из одного файла».
- «Прямой ввод-вывод очень медленный. Он подходит только для очень специализированных областей применения. Если у тебя нет собственного кэша, ты обречён».
Однако если изучить спецификации современных NVMe-устройств, то мы увидим, что даже в потребительском классе это устройства с задержками, измеряемыми в единицах микросекунд, и пропускной способностью в несколько ГБ/с, поддерживающие несколько сотен тысяч произвольных IOPS. Так в чём же нестыковка?
Тестируем веб-API ASP.NET Core
8 мин
Перевод

При проектировании и разработке широкого спектра API с использованием ASP.NET Core 2.1 Web API важно понимать, что это только первый этап в создании продуктивного и стабильного решения. Наличие стабильной среды для вашего решения также очень важно. Ключ к отличному решению заключается не только в правильном построении API, но и в его тщательном тестировании, чтобы исключить возможность негативного опыта у пользователей во время использования вашего API.
Эта статья является продолжением моей предыдущей статьи для InfoQ под названием «Продвинутая архитектура веб-API ASP.NET Core». Не беспокойтесь, вам не нужно вникать в предыдущую статью, чтобы разобраться с тестированием в этой, но она может помочь вам лучше понять, как я спроектировал обсуждаемое здесь решение. На протяжении последних нескольких лет я много времени размышлял о тестировании, создавая API для клиентов. Знание архитектуры веб-API ASP.NET Core 2.1 может помочь и вам расширить ваше понимание.
Солюшн и весь код из примеров в этой статье можно найти в моем GitHub репозитории.
Как автоматизировать процессы с помощью low code конструкторов: пример платных парковок
4 мин
Давно хотел погрузиться в нишу No code или Zero code. И вот наконец появилась задачка, которую решил собрать на конструкторах.
Одна сеть Магазинов с большими парковками решили автоматизировать работу своего парковочного пространства. Нужно было собрать ботак, который должен был научиться собирать платежи за парковку, оформлять абонементы с рекуррентными платежами.
Ребята хотели помочь людям быстро оплачивать парковочное место, а также стимулировать их пользоваться парковкой как отдельным продуктом (то есть просто оставлять автомобиль на этой парковке и идти по своим делам, а не в сам гипермаркет).
Дано
Одна сеть Магазинов с большими парковками решили автоматизировать работу своего парковочного пространства. Нужно было собрать ботак, который должен был научиться собирать платежи за парковку, оформлять абонементы с рекуррентными платежами.
Ребята хотели помочь людям быстро оплачивать парковочное место, а также стимулировать их пользоваться парковкой как отдельным продуктом (то есть просто оставлять автомобиль на этой парковке и идти по своим делам, а не в сам гипермаркет).
API для QA: тестируем фичи без доступа к коду
6 мин
Многие фичи приложения невозможно быстро протестировать, не меняя исходный код. Представьте типичную задачу, с которой может столкнуться каждый разработчик: через три дня после регистрации пользователю нужно предложить купить премиум-доступ к продукту со скидкой. Чтобы проверить, работает ли это промо, нужно зарегистрировать тестового пользователя и подождать три дня до появления заветного окошка.
Очевидно, что разработчик не будет столько ждать. Он просто сменит в коде значение константы, которая задаёт временной интервал, с трёх дней на 20 секунд — и получит результат почти мгновенно.
Допустим, данные для промопредложения отдаёт сервер, а отрисовывается оно на клиенте. Если серверный тестировщик работает в среде, которая допускает манипуляции с кодом, он тоже быстро справится с задачей. Но как только она окажется там, где возможность менять код отсутствует (стейджинг, продакшен), возникнет проблема.
Рейт лимиты с помощью Python и Redis
5 мин
Туториал
Перевод

В этой статье мы рассмотрим некоторые алгоритмы рейт лимитов на основе Python и Redis, начиная с самой простой реализации и заканчивая продвинутым обобщённым алгоритмом контроля скорости передачи ячеек (Generic Cell Rate Algorithm, GCRA).
Для взаимодействия с Redis (
pip install redis) мы будем пользоваться redis-py. Предлагаю клонировать мой репозиторий для экспериментирования с ограничениями запросов.Вредные советы для «идеального» REST API
4 мин
Всем привет!
Почему 'идеального' написано в кавычках?!
То, что написано ниже относится к разряду "так делать не надо", однако, если вы считаете иначе — интересно будет услышать ваше мнение на этот счёт )
Наверное, многие из нас делали REST API, либо пользовались чьим-то готовым. Разберём в статье "невероятные" трюки, которые помогут сделать ваше API на голову выше, чем у других.
Что было раньше: код или документация? OpenApi (OAS 3.0) и проблемы кодогенерации на Java
9 мин

Задача интеграции сервисов и различных систем является чуть ли не одной из основных проблем современного IT. На сегодняшний день самым популярным архитектурным стилем для проектирования распределенных систем является REST. Но, как известно, единого стандарта для RESTful сервисов нет, а у кажущейся простоты и свободы есть обратная сторона медали. Не менее важной является задача интеграции систем разными командами или даже компаниями, с которой приходит вопрос об актуальности документации на протяжении жизни всего проекта, и удобного способа передачи потребителю.
Эту проблему отчасти удалось решить при помощи спецификации OpenAPI (OAS 3.0)[1], но все равно часто встает вопрос о правильном применении и подводных камнях кодогенерации, например на языке Java. И можно ли полностью предоставить аналитикам написание функциональных требований, документации и моделей в yml форме для OpenAPI, а разработчикам предоставить возможность только написание бизнес-логики?
Вентилятор для zwift с алисой
4 мин
Всем привет. Хочу заранее извинится за корявось решений, кода и изготовления. Во-первых, у меня очень кривые руки, во-вторых, стараюсь сделать с минимальными усилиями и из того, что есть под рукой, — главное чтоб работало стабильно и выполняло нужные функции.
Цель: тренируюсь регулярно на велосипеде, а зимой тренировки проходят дома на велостанке (кстати, он тоже у меня самодельный и это другая история) для обдува практически все, кто так тренируется, используют вентилятор.
Цель: тренируюсь регулярно на велосипеде, а зимой тренировки проходят дома на велостанке (кстати, он тоже у меня самодельный и это другая история) для обдува практически все, кто так тренируется, используют вентилятор.
Ближайшие события
Краткий обзор системы Apache NlpCraft
7 мин
В данной статье я бы хотел познакомить читателей с одним из проектов Apache Software Foundation сообщества — NlpCraft. NlpCraft — библиотека с открытым исходным кодом, предназначенная для интеграции языкового интерфейса в пользовательские приложения.
Цель проекта — тотальное упрощение доступа к возможностям NLP (Natural Language Processing) разработчикам приложений. Основная идея системы — это уловить баланс между простотой вхождения в NLP проблематику и поддержкой широкого диапазона возможностей промышленной библиотеки. Задача проекта бескомпромиссна — простота без упрощения.
На момент версии 0.7.1 проект находится в стадии инкубации Apache сообщества и доступен по адресу https://nlpcraft.apache.org.
Цель проекта — тотальное упрощение доступа к возможностям NLP (Natural Language Processing) разработчикам приложений. Основная идея системы — это уловить баланс между простотой вхождения в NLP проблематику и поддержкой широкого диапазона возможностей промышленной библиотеки. Задача проекта бескомпромиссна — простота без упрощения.
На момент версии 0.7.1 проект находится в стадии инкубации Apache сообщества и доступен по адресу https://nlpcraft.apache.org.
Как разобраться в API HTML?
8 мин
Перевод
Автор статьи, перевод которой мы сегодня публикуем, решил разобрать несколько HTML5-API и поговорить об их возможностях, о том, для чего они созданы, об особенностях их использования и об их ограничениях.

Замена UI-авторизации на API для автотестов
3 мин
Один из важнейших вызовов в автоматизированном тестировании, по моему мнению, – это обеспечить его высокую надёжность. В решении проблемы улучшения показателей надёжности тестирования, хорошо себя зарекомендовал подход использования API интерфейса вместо UI. В данной статье мы подробно разберём простой механизм замены UI авторизации на API.
Существует большое количество видов аутентификации – Basic, Digest, Form, OAuth 1 и OAuth 2. В качестве примера я предлагаю рассмотреть одну из простейших, а именно – Form. Основная задача статьи – это показать подход внедрения API авторизации для UI тестов. Тесты и имплементацию будем писать на Java. Из инструментов будем использовать Chrome DevTools.
В качестве объектов тестирования используем Kanboard та DVWA. Это open source продукты с открытой лицензией, которые достаточно легко развернуть локально. По ссылкам можно прочитать больше про данные продукты и при необходимости ознакомиться с инструкциями из развёртки.
B2S-платформа Билайн
6 мин
— Обращаем ваше внимание, что разговор записывается и может быть передан в службу контроля качества
Наверняка вы часто слышали эту фразу, когда пытались позвонить в доставку, дабы уточнить у курьера, как дела с вашей посылкой. Или же когда вам звонили из колл-центра интернет-магазина с подтверждением вашего заказа.
Хорошо, когда у таких компаний достаточно своего опыта и экспертизы для того, чтобы обработать свой поток телефонных звонков.
А если количество звонков — несколько миллионов в… минуту? Взращивать из себя оператора связи?
Мы помогаем бизнесу решать задачи любого уровня сложности, связанные с телефонией, обрабатывая десятки миллионов звонков с помощью нашей B2S-платформы Билайн. Меня зовут Евгений Ковалев, и под катом я расскажу, что это за платформа, что умеет и чем отличается от имеющихся на рынке решений, а также почему мы считаем важным то, чем занимаемся.
Наверняка вы часто слышали эту фразу, когда пытались позвонить в доставку, дабы уточнить у курьера, как дела с вашей посылкой. Или же когда вам звонили из колл-центра интернет-магазина с подтверждением вашего заказа.
Хорошо, когда у таких компаний достаточно своего опыта и экспертизы для того, чтобы обработать свой поток телефонных звонков.
А если количество звонков — несколько миллионов в… минуту? Взращивать из себя оператора связи?
Мы помогаем бизнесу решать задачи любого уровня сложности, связанные с телефонией, обрабатывая десятки миллионов звонков с помощью нашей B2S-платформы Билайн. Меня зовут Евгений Ковалев, и под катом я расскажу, что это за платформа, что умеет и чем отличается от имеющихся на рынке решений, а также почему мы считаем важным то, чем занимаемся.
Чего ждать при работе с API: 5 (не)обычных проблем при интеграции приложений
6 мин

Где-то на просторах мультивселенной…
Представьте на минуту, что вы капитан Сиракузии, которая в 239 году до н. э. приближается к острову Фарос, что близ города Александрии. Вследствие узости прохода, войти в гавань Александрии — непростая задача, в особенности, для такого корабля, как ваш. Вы слышали, что за последний год навигация около острова улучшилась, так как был завершен Фа́росский маяк, уникальное сооружение, заложенное еще при Птолемее I.
Но, приблизившись к острову, вы понимаете, что промахнулись мимо гавани, так как гигантский маяк был спроектирован башней под воду, а свет сигнальных костров виден только в сумерках и при сильной облачности, ведь зеркала подводной башни отражают свет исключительно вверх. Проклиная свою работу, вы пишете письмо Гиерону II, с описанием того, как неудачно спроектирован интерфейс взаимодействия с портом, а он, как человек с поистине царским чутьем, решает подарить корабль правителю Александрии, а сам начинает смотреть в сторону альтернативных торговых маршрутов…
Почему-то, когда я думаю об интеграционных API, с которыми неудобно работать, в голове появляется образ именно такого вот маяка, и в этой статье хотелось бы рассказать о конкретных проблемах, с которыми сталкивалась наша команда в процессе интеграции с различными внешними сервисами, а также высказать своё субъективное мнение о том, что именно делает интеграционное API удобным. Итак, капитан очевидность поднялся на борт, поплыли.
Что такое XML
13 мин
Если вы тестируете API, то должны знать про два основных формата передачи данных:
Сегодня я расскажу вам про XML.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.

- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.
Сегодня я расскажу вам про XML.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:
Что такое API — общее знакомство с API
Что такое JSON — второй популярный формат
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.
Некоторые советы по созданию API
5 мин
У нас в Uma.Tech накопился хороший опыт по созданию различных API. Часть этого опыта была приобретена через набивание шишек. Хотим поделиться с вами некоторыми советами, которым мы сами стараемся следовать, чтобы в будущем вам было проще развивать и поддерживать собственный продукт.
Автор материала — @alitvinenko