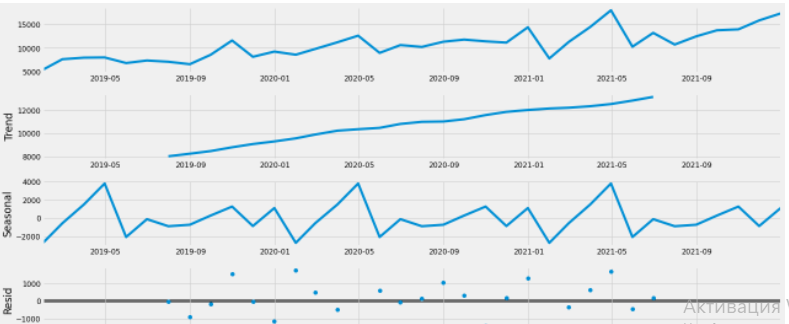
Любите ли вы задачи кластеризации? Лично я — да. Они хорошо поддаются визуализации, понятны людям, далеким от математики, и зачастую оказывают быстрое влияние на бизнес процессы. Однако, при решении задач кластеризации мы можем столкнуться с рядом проблем. Среди которых может быть:
• большая размерность вектора признаков,
• отсутствие данных на подмножестве фичей,
• зашумленность значений / выбросы и т.д.
В случае, если количество объектов небольшое (и увеличить их естественным образом невозможно), то при неблагоприятном стечении обстоятельств мы можем столкнуться с серьезными проблемами в качестве нашей кластеризации.
Но если количество объектов достаточно большое, возникают вычислительные проблемы, такие как: нехватка ресурсов, скорость выполнения и т.д.