Время течет и скоро от этой разработки почти ничего не останется, а у меня все никак не находилось времени ее описать.
Речь пойдет о компании федерального уровня с большим числом филиалов и подфилиалов. Но, как обычно, все началось давным-давно с одного маленького магазина. С течением лет шло достаточно быстрое и стихийное развитие, появлялись филиалы, подразделения и прочие офисы, а ИТ-инфраструктуре не уделялось в те времена должного внимания, и это тоже частое явление. Конечно же, везде использовалась 1С77, без задела на какие-либо репликации и масштабирование, поэтому, сами понимаете, в конце пришли к тому, что был порожден спрут-франкенштейн с примотанными изолентой щупальцами — в каждом филиале автономный мутант, который с центральной базой обменивался в «наколеночном» режиме лишь несколькими справочниками, без которых ну вообще никак было нельзя, а остальное автономно. Какое-то время довольствовались копиями (десятки их!) филиальных баз в центральном офисе, но данные в них отставали на несколько дней.
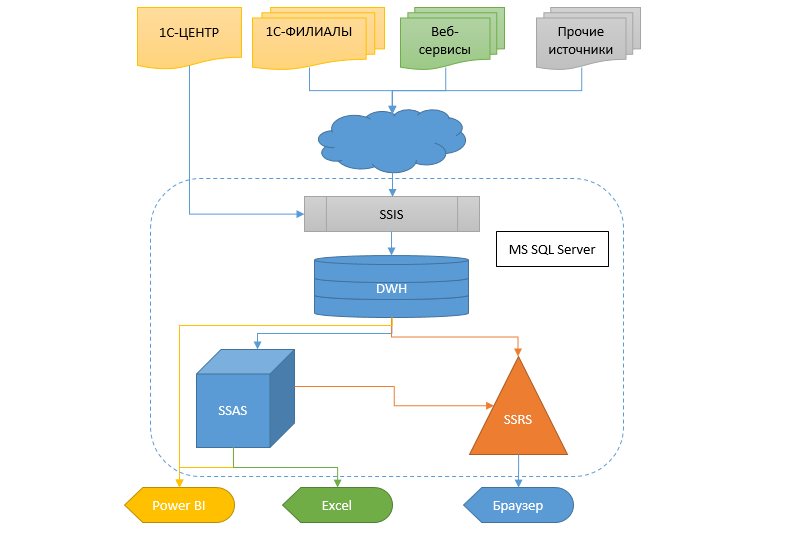
Реальность же требует получать информацию более оперативно и гибко, а еще надо что-то с этим делать. Пересесть с одной учетной системы на другую при таких масштабах — то еще болото. Поэтому было решено сделать хранилище данных (ДХ), в которое стекалась бы информация из разных баз, чтобы впоследствии из этого ХД могли получать данные другие сервисы и аналитическая система в виде кубов, SSRS отчетов и протча.
Забегая вперед скажу, что переход на новую учетную систему почти уже случился и бОльшая часть проекта, описываемого здесь, будет выпилена в ближайшее время за ненадобностью. Жаль, конечно, но ничего не поделаешь.
Далее следует длинная статья, но прежде чем начнете читать, позвольте заметить, что ни в коем случае не выдаю это решение за эталон, однако может кто-то найдет для себя в ней что-то полезное.