
SBER-MoVQGAN или новый эффективный Image Encoder для генеративных моделей

Вариационные автоэнкодеры в квантованном векторном пространстве стали довольно популярными в последние несколько лет и успешно применяются в широком спектре генеративных задач (Stable Diffusion, VQ Diffusion, VideoGPT и др.). VQVAE позволяет сжимать картинку в латентное пространство меньшей размерности, а затем восстанавливать это латентное представление изображения в RGB-состояние. Операции в латентном пространстве выполняются быстро, поэтому VQVAE получил широкое применение как в авторегрессионных мультимодальных архитектурах (DALLE, ruDALL-E, RUDOLPH), так и в диффузионных моделях (DALL-E 2, Kandinsky 2.1, Latent Diffusion). В первом случае вариационный автоэнкодер позволяет закодировать картинку в последовательность визуальных токенов, которые вместе с текстовыми токенами используются в обучении трансформера. Во втором случае VQVAE кодирует картинку в квантованное пространство малой размерности, позволяя выполнять диффузионный процесс в латентном пространстве (ввиду того, что диффузионный процесс является итеративным и скорость генерации напрямую зависит от числа шагов диффузии, вычислительная сложность каждого шага очень важна), который в сравнении с пиксельной диффузией выполняется быстрее и потребляет меньше памяти.
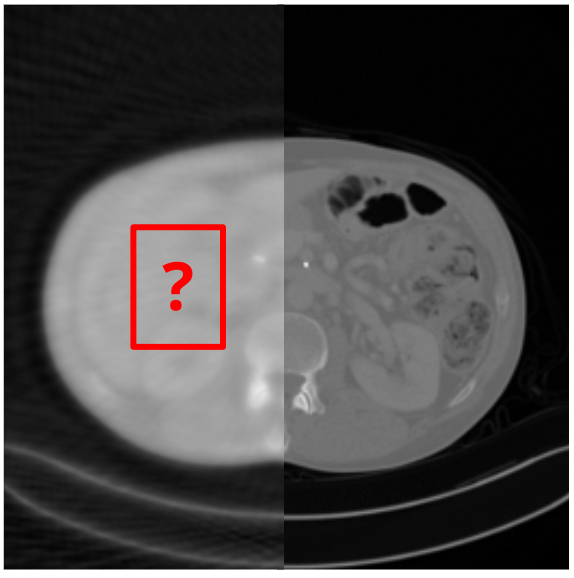
Во всех перечисленных задачах качество генерации напрямую зависит от качества восстановления исходных картинок с помощью VQVAE. Пару лет назад мы уже проводили эксперименты и обучали SBER-VQGAN, который на тот момент давал лучшие результаты в сравнении c dVAE и ванильным VQGAN. Подробнее об этих экспериментах можно прочитать в статье на Хабре. Однако по-прежнему нам не хватало качества восстановления в сложных доменах, таких как текст и лица, поэтому мы попытались модифицировать и улучшить SBER-VQGAN, в результате получив SoTA среди моделей по кодированию изображений.












{kind=link}