Началось всё с того, что однажды мы увидели гигантскую хреновину (иначе не скажешь), которая выглядела один в один, как гидравлический пресс какого-нибудь завода. Она скрипела, шипела и давила книгу. Вокруг бегали специально обученные операторы и шарахались от каждого её движения.
Выяснилось, что разные архивы, библиотеки, суды и другие структуры закупают сканеры, или, скажем так, классические решения, которые по уровню начинки очень напоминают 90-е годы. Потому что тогда были разработаны первые сканеры для библиотек, и их с тех пор не особо модифицировали.
Задачей сканера было механически выровнять сканируемый материал на плоскости, а потом отсканировать.
С тех пор поменялись две вещи:
— Подходы к конструированию электроники.
— Подходы к машинному зрению.



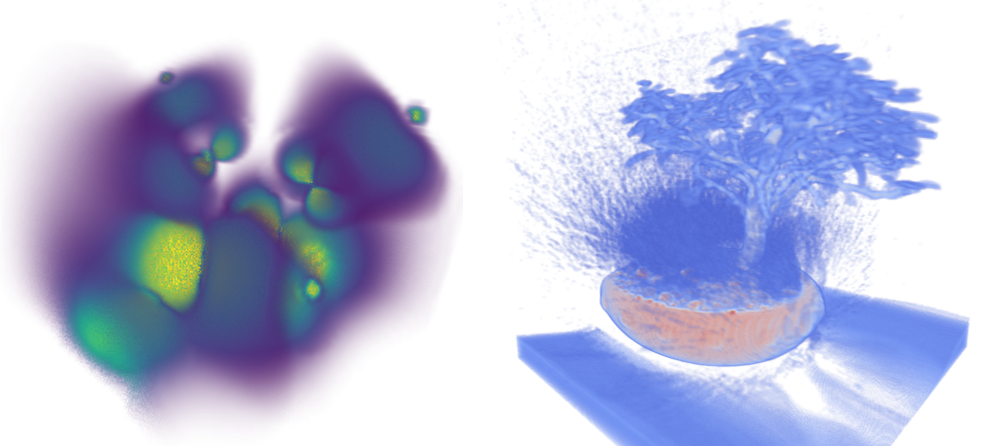
 Я уже делал на Хабре
Я уже делал на Хабре