
DevOps — это маркетинговое словечко, за которым ничего нет! Или все-таки есть? Может быть, DevOps — это набор «правильных» инструментов, или это такая специальная культура. И кто вообще должен этим заниматься, что из себя представляет DevOps-инженер? Одним словом, есть некоторые разночтения в понятиях, и очень много мифов. Некоторые совсем тривиальные, и мало кто в них поверит, а некоторые пускают корни в умах уважаемых специалистов. Разбираться будем вместе с опытными DevOps’ерами Александром Титовым и Иваном Евтуховичем (evtuhovich). Хотя они и считают, что DevOps — это решение проблемы производства цифровых продуктов и называть так отдельного человека это в стиле российского бизнеса.
О спикерах: Александр Титов и Иван Евтухович представляют компанию Экспресс 42, которая занимается консалтингом в области DevOps. Среди её клиентов много известных компаний, например, МТС, Райффайзенбанк банк, Альфа-Банк и другие.
За 5 лет работы собралась куча мифов про DevOps, которые существуют в обществе. В своем докладе на РИТ++ 2017 Александр и Иван рассуждали на эту тему. Иван в безапелляционном тоне объявлял расхожее мнение, а Александр пытался убедить слушателей в том, что это лишь миф.
О спикерах: Александр Титов и Иван Евтухович представляют компанию Экспресс 42, которая занимается консалтингом в области DevOps. Среди её клиентов много известных компаний, например, МТС, Райффайзенбанк банк, Альфа-Банк и другие.
За 5 лет работы собралась куча мифов про DevOps, которые существуют в обществе. В своем докладе на РИТ++ 2017 Александр и Иван рассуждали на эту тему. Иван в безапелляционном тоне объявлял расхожее мнение, а Александр пытался убедить слушателей в том, что это лишь миф.







 Массовая DDoS атака на инфраструктуру крупного провайдера сетевых сервисов
Массовая DDoS атака на инфраструктуру крупного провайдера сетевых сервисов 
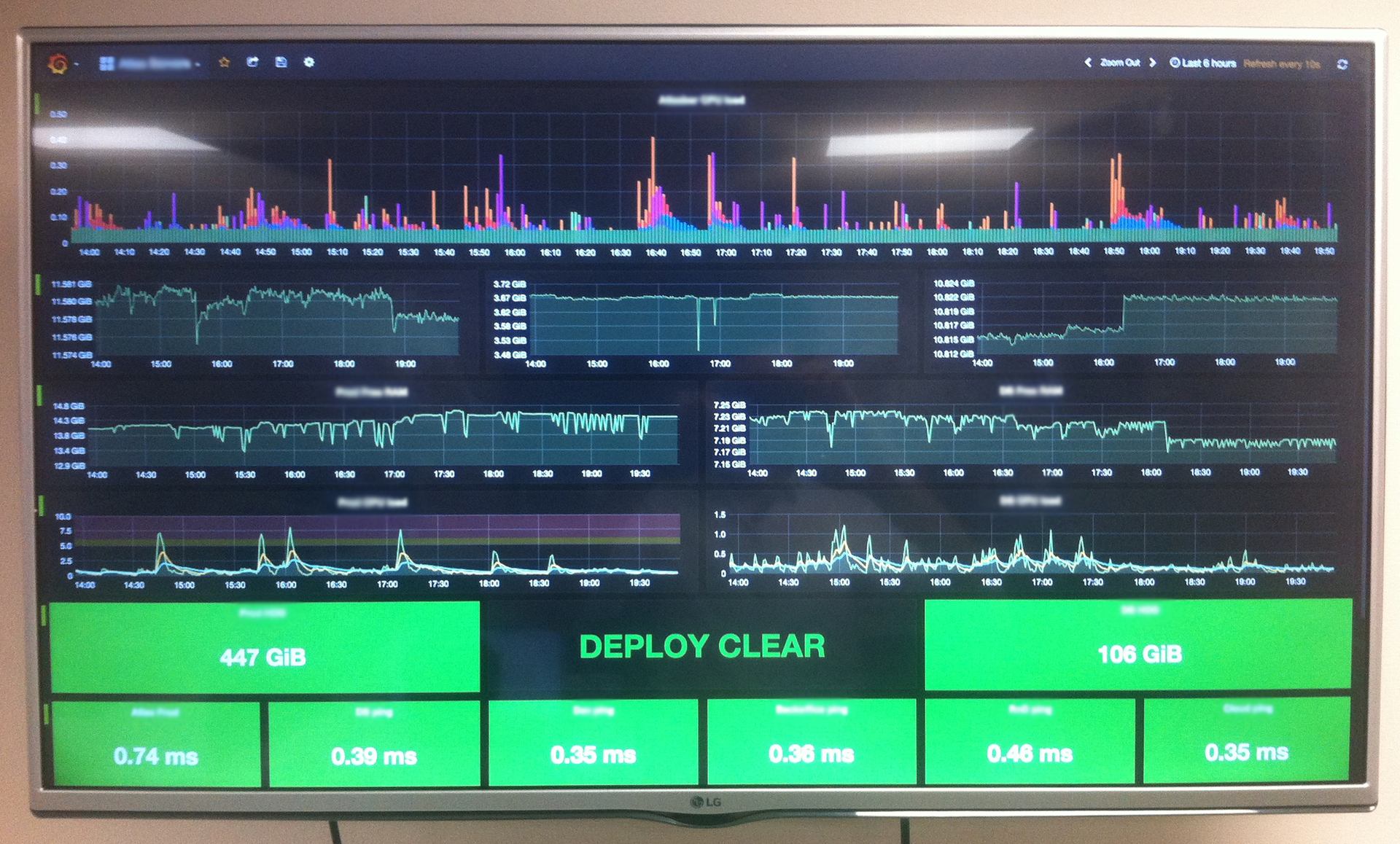


 Если вам не нравится стандартный pastebin или навороченный
Если вам не нравится стандартный pastebin или навороченный 


