В последние десятилетия угроза загрязнения водных ресурсов стала одной из наиболее беспокоящих экологических проблем. С ростом мирового потребления фармацевтических препаратов в 2020 году оно достигло 4 миллиардов доз, и как следствие, водные системы сталкиваются с увеличением количества и разнообразия микроэлементов, попадающих в очистные сооружения. Эти вещества, часто неизвестные и трудно поддающиеся анализу, могут оказать вредное воздействие на окружающую среду и здоровье человека, включая канцерогенез и эндокринные нарушения.
В условиях, где традиционные методы анализа требуют дорогостоящего оборудования, опытных специалистов и затрат времени, наука стремится к эффективным и инновационным подходам. В этом контексте исследовательская команда Корейского Института Науки и Технологии (KIST), под руководством Хон Сок-Вона, главы Центра исследования водных ресурсов и цикла, и старшего исследователя Сон Муна, представляет новаторскую методологию, основанную на искусственном интеллекте, для борьбы с вызовами загрязнения воды.
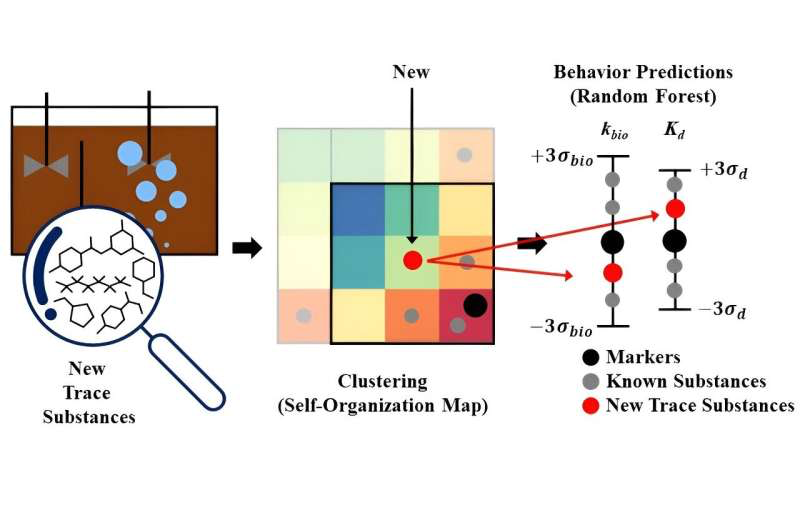
В данной статье мы рассмотрим уникальный подход команды KIST, объединяющий в себе методы самоорганизующихся карт (SOM) для кластеризации и случайных лесов (RFC) в машинном обучении для прогнозирования свойств и поведения микроэлементов. Результаты этого исследования проливают свет на возможности применения искусственного интеллекта в экологии, предоставляя быстрый и точный инструмент для анализа и прогнозирования воздействия микроэлементов в водных системах.
Приятного прочтения (: