

Последние лет восемь я активно занимаюсь задачами, связанными с распознаванием образов, компьютерным зрением, машинным обучением. Получилось накопить достаточно большой багаж опыта и проектов (что-то своё, что-то в ранге штатного программиста, что-то под заказ). К тому же, с тех пор, как я написал пару статей на Хабре, со мной часто связываются читатели, просят помочь с их задачей, посоветовать что-то. Так что достаточно часто натыкаюсь на совершенно непредсказуемые применения CV алгоритмов.
Но, чёрт подери, в 90% случаев я вижу одну и ту же системную ошибку. Раз за разом. За последние лет 5 я её объяснял уже десяткам людей. Да что там, периодически и сам её совершаю…
В 99% задач компьютерного зрения то представление о задаче, которое вы сформулировали у себя в голове, а тем более тот путь решения, который вы наметили, не имеет с реальностью ничего общего. Всегда будут возникать ситуации, про которые вы даже не могли подумать. Единственный способ сформулировать задачу — набрать базу примеров и работать с ней, учитывая как идеальные, так и самые плохие ситуации. Чем шире база-тем точнее поставлена задача. Без базы говорить о задаче нельзя.
Тривиальная мысль. Но все ошибаются. Абсолютно все. В статье я приведу несколько примеров таких ситуаций. Когда задача поставлена плохо, когда хорошо. И какие подводные камни вас ждут в формировании ТЗ для систем компьютерного зрения.





 Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.
Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.
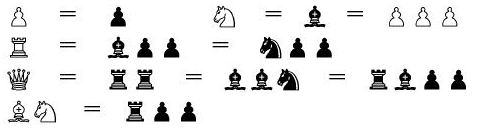 Здравствуй, Хабр!
Здравствуй, Хабр!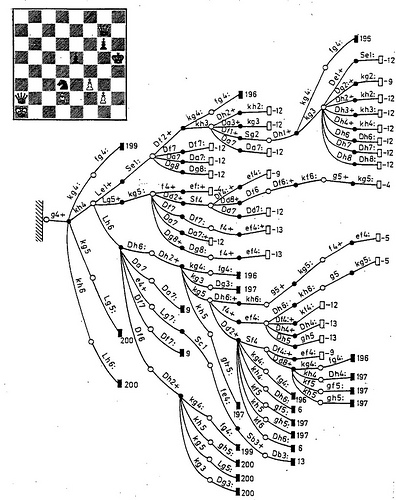

 Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как
Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как 













{kind=link}