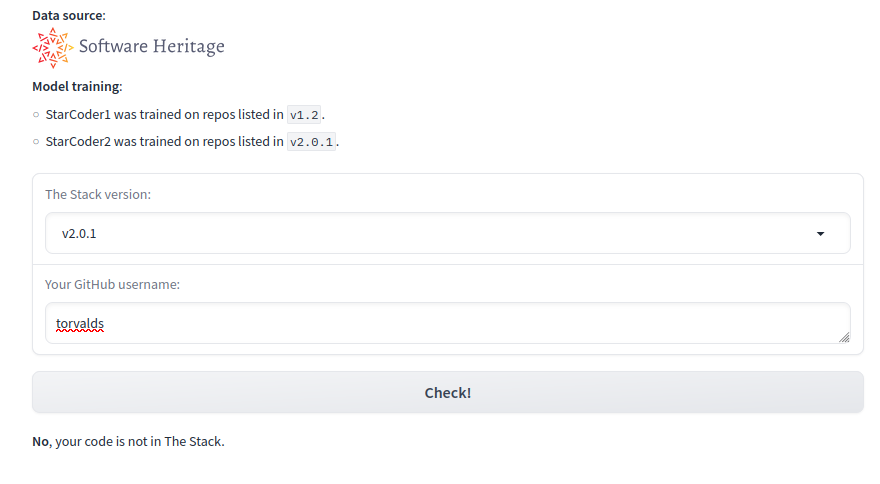
Проверьте, используются ли ваши репозитории GitHub и исходный код ваших проектов для обучения различных больших языковых моделей (БЯМ — LLM).
На huggingface появилась вторая версия проекта Stack. Это открытый интерфейс управления между сообществом искусственного интеллекта и сообществом открытого исходного кода.
В рамках проекта BigCode выпущен и поддерживается The Stack V2 — набор данных исходного кода объёмом 67 ТБ для более чем 600 языков программирования. Одна из целей в этом проекте — предоставить людям свободу действий в отношении их исходного кода, позволяя им решать, следует ли использовать его для разработки и оценки моделей машинного обучения, поскольку сообщество признает, что не все разработчики могут захотеть, чтобы их данные использовались для этого.
Этот инструмент позволяет проверить, является ли репозиторий под именем пользователя частью набора данных The Stack. Хотели бы вы удалить свои данные из будущих версий The Stack? Вы можете это сделать, следуя инструкциям здесь.
Примечание. Stack v2.0 создан на основе общедоступного кода GitHub, предоставленного Software Heriage Archive. Он может включать репозитории, которых больше нет на GitHub, но которые были ранее заархивированы Software Heritage. Перед обучением моделей StarCoder 1 и 2 был запущен дополнительный конвейер PII для удаления имён, адресов электронной почты, паролей и ключей API из файлов доступных репозиториев исходного кода.