Модель Claude 3 Opus опередила GPT-4 в глобальном рейтинге LMSYS. Нейросеть от OpenAI отстала всего на два пункта (1251 против 1253). Пятёрка лидеров с показателями Arena Elo выглядит следующим образом:
«Яндекс» анонсировал третье поколение YandexGPT, а YandexGPT 3 Pro стала первой большой языковой моделью семейства и уже доступна в сервисе Yandex Cloud.
YandexGPT 3 Pro лучше работает со сложными задачами и более точно следует запросам. Это позволяет компаниям использовать языковую модель в своей работе и продуктах. При необходимости нейросеть можно дообучить на собственных данных. Доступна интеграция в продукты через API. Уже сейчас можно попробовать языковую модель в демо-режиме. Зарегистрированные пользователи могут отправлять до 100 бесплатных запросов в час. В ближайшее время нейросеть станет доступна в сервисах «Яндекса».
Для тестирования YandexGPT 3 Pro разработчики использовали тест YaMMLU_ru — локализованную на русский язык версию международного теста MMLU. Кроме того, возможности нейросети проверяли по методике Side by Side (SBS), чтобы оценить, как она справляется с общением, созданием контента и генерацией идей. YandexGPT 3 отвечала лучше, чем YandexGPT 2 в 67% случаев.
Компания рассказала, что стоимость использования нейросети снизилась почти в два раза. Дообучение будет доступно в сервисе ML-разработки Yandex DataSphere.
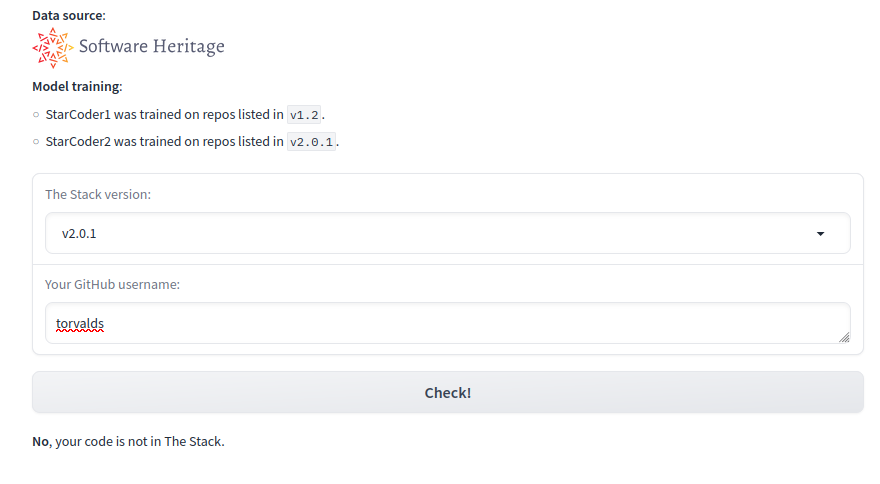
Проверьте, используются ли ваши репозитории GitHub и исходный код ваших проектов для обучения различных больших языковых моделей (БЯМ — LLM).
На huggingface появилась вторая версия проекта Stack. Это открытый интерфейс управления между сообществом искусственного интеллекта и сообществом открытого исходного кода.
В рамках проекта BigCode выпущен и поддерживается The Stack V2 — набор данных исходного кода объёмом 67 ТБ для более чем 600 языков программирования. Одна из целей в этом проекте — предоставить людям свободу действий в отношении их исходного кода, позволяя им решать, следует ли использовать его для разработки и оценки моделей машинного обучения, поскольку сообщество признает, что не все разработчики могут захотеть, чтобы их данные использовались для этого.
Этот инструмент позволяет проверить, является ли репозиторий под именем пользователя частью набора данных The Stack. Хотели бы вы удалить свои данные из будущих версий The Stack? Вы можете это сделать, следуя инструкциям здесь.
Примечание. Stack v2.0 создан на основе общедоступного кода GitHub, предоставленного Software Heriage Archive. Он может включать репозитории, которых больше нет на GitHub, но которые были ранее заархивированы Software Heritage. Перед обучением моделей StarCoder 1 и 2 был запущен дополнительный конвейер PII для удаления имён, адресов электронной почты, паролей и ключей API из файлов доступных репозиториев исходного кода.
Financial Times запустила собственного чат-бота с генеративным ИИ под названием Ask FT, который обучен отвечать на различные вопросы подписчиков издания.
Для тренировки чат-бота разработчики из FT использовали только собственные материалы, полученные из базы данных сайта издания.
Nvidia опубликовала в открытом доступе бесплатные обучающие курсы для пользователей любого уровня подготовки по нейросетям и нейромоделям для понимания работы ИИ.
Список курсов:
объяснение генеративного ИИ: базовый 2-часовой курс, который подробно объяснит устройство нейронок, их применение и возможности;
создаём «мозг» за 10 минут:объяснит, как нейронка обучается на данных и покажет всю математику у неё под капотом;
Выше пользовательского сообщения ChatGPT получает немного текста, который самому пользователю не виден. Этот текст — системный промпт. Он инициализирует бота: рассказывает, кто он такой, какой сегодня день и какие возможности доступны.
Получить системный промпт всё же можно, если попросить модель процитировать сообщение выше. Кстати, именно из-за изменений системного промпта качество работы ChatGPT могло ухудшаться. А меняться там есть чему: системный промпт у OpenAI составляет в длину 1700 токенов.
Аманда Аскелл [Amanda Askell], специалист по этике в Anthropic, показала системный промпт бота Claude 3 и объяснила, что содержит каждый из абзацев:
Имя, компания-создатель и текущая дата.
Временная отсечка базы знаний и инструкция отвечать с учётом того, что данные уже устаревшие.
Инструкция отвечать подробно, но не слишком длинно.
Claude чаще отказывается выполнять задачи, связанные с правыми взглядами, чем с левыми. Четвёртый абзац призван с этим бороться.
Аналогично, пятый абзац борется с тенденцией Claude стереотипно высказываться о группах, представляющих большинство, но уходить от стереотипов, если речь идёт про различные меньшинства.
Четвёртый абзац приводит к тому, что Claude часто говорит, что обе стороны в чём-то правы. Шестой абзац это исправляет.
Инструкция всячески помогать и писать код в Markdown.
Восьмой абзац призван не спрятать системный промпт, а снизить его избыточную цитируемость.
Впрочем, системные промпты часто и быстро меняются.
Источники СМИ сообщили, что OpenAI уже некоторое время активно тестирует в закрытом формате следующее поколение модели искусственного интеллекта под названием GPT-5.
Ожидается, что перевод этого проекта в доступный режим произойдёт в середине 2024 года, предположительно, летом.
По словам тестировщиков, эта модель существенно лучше GPT-4. Там доступны новые опции типа интеллектуального агента, который умеет самостоятельно выполнять задания человека в течение длительных промежутков времени, а также различные системы для автономного выполнения задач.
СМИ выяснили, что в OpenAI продолжают обучать новый ИИ, затем он будет проходить тесты на безопасность: отвечать на наводящие вопросы от разных команд тестеров, проходить проверки на токсичность и так далее, прежде чем к этой системе получат доступ обычные пользователи.
Ранее глава OpenAI Сэм Альтман заявил, что разработчики обучают ИИ-модель пятого поколения не только на открытой информации и комбинациях общедоступных наборов данных в интернете, но и на внутренних базах данных многих крупных IT-компаний, которые сотрудничают с OpenAI.
В начале марта 2024 года исследователи обнаружили, что OpenAI работает над нейросетью GPT-4.5 Turbo, у которой окно длины контекста в 256 КБ токенов, что вдвое превышает текущие 128 КБ GPT-4 Turbo.
В марте 2023 года OpenAI представила модель ИИ интерпретации изображений и текста GPT-4, которую компания назвала «последней вехой в своих усилиях по расширению масштабов глубокого обучения».
Более того, с помощью GPT-4 мы перевели содержание на русский язык и где возможно, заменили ссылки на дополнительные статьи (Wikipedia и подобные) на русскоязычные версии. За бесплатный доступ к GPT-4 для нашего проекта благодарим ProxyAPI — доступ к OpenAI API в России.
Мы продолжаем работать над проектом, будем дополнять документацию время от времени. Но уже сейчас все основные методы и гайды у нас доступны. Приглашаем всех желающих ознакомиться!
Проект Grok-1 опубликован на GitHub под лицензией Apache 2.0, а скачать архив с кодом чат-бота можно, вставив эту ссылку в торрент-клиент (300 ГБ файлов с весами MoE-модели c 314 млрд параметров):
4 ноября 2023 года xAI запустила своего чат-бота Grok с генеративным искусственным интеллектом для ограниченной аудитории. В компании планировали сделать языковую модель xAI доступной для всех платных подписчиков соцсети X.
В июле прошлого года Маск объявил о начале работы xAI. Главная цель проекта — «понять истинную природу Вселенной».
11 марта 2024 года Илон Маск пообещал, что ИИ-стартап xAI откроет исходный код чат-бота Grok на неделе. Маск сделал это заявление через несколько суток после того, как подал в суд на OpenAI и пожаловался, что поддерживаемый Microsoft стартап отклонился от своих корней и не выложил в открытом доступе исходный код ChatGPT.
Согласно новым данным из «утечки» от OpenAI, одним из существенных обновлений в GPT-4.5 Turbo является окно длины контекста в 256 КБ токенов, что вдвое превышает текущие 128 КБ GPT-4 Turbo. Этот шаг, похоже, является ответом OpenAI на конкурентов, запускающих модели со все более большими контекстными окнами, включая Google Gemini. Вероятно, что новая модель GPT изменит ситуацию для OpenAI или даже продвинет её впереди чат-бота Google.
OpenAI пока официально не раскрыла информацию об утечке, поэтому статус GPT-4.5 Turbo и дата выпуска в июне 2024 года окутаны тайной.
12 марта 2024 года исследователи обнаружили в кэше Bing, что OpenAI готовится представить нейросеть GPT-4.5 Turbo. Но ссылка на эту страницу на сайте OpenAI выдаёт ошибку 404. Также из поисковой выдачи пропало упоминание о новом чат-боте.
Неясно, был ли это какой-то тест или OpenAI решила придержать релиз новой версии чат-бота.
В марте 2023 года OpenAI представила новую модель ИИ интерпретации изображений и текста GPT-4, которую компания назвала «последней вехой в своих усилиях по расширению масштабов глубокого обучения».
Ожидается, что с помощью чат‑бота GPT-4.5 OpenAI стремится устранить некоторые ограничения и проблемы, с которыми столкнулись его предшественники. Это включает в себя уменьшение предвзятости в сгенерированном тексте, улучшение понимания моделью неоднозначных запросов и значительное улучшение её способности решать задачи, специфичные для определённой предметной области.
Компания Figure в рамках сотрудничества OpenAI показала интеграцию своего робота-гуманоида Figure 01 с наработками компании-партнёра. Ранее представленный робот, который выполняет задачи автономно, теперь успешно делает многое с помощью нейросети.
Благодаря OpenAI Figure 01 теперь может полноценно общаться с людьми, так как ИИ-модель OpenAI даёт высокий уровень визуального и языкового интеллекта, а нейронные сети обеспечивают быстрые, низкоуровневые и ловкие действия робота. Производитель пояснил, что всё в этом видео — работа нейросети:
Робот научился описывать то, что видит, и рассуждать, что можно сделать с предметами. В ролике робот сам понял, что тарелки и стаканы надо ставить в одно место. Также он умеет анализировать ситуацию. Если попросить робота передать еду, а на столе из съедобного только яблоко, то он даст именно яблоко. С ИИ робот держит в памяти всю нужную информацию. В конце видео робот пересказал свои действия и даже дал им оценку.
У Figure 01 будут роборуки с силиконовыми кончиками пальцев. Прототип уже способен выполнять манипуляции как одной, так и двумя руками, хватая объекты и перемещая их. Так, он может манипулировать коробками, контейнерами и другими предметами на складах и на производстве. Кроме того, робот может захватывать обычные предметы, например пачку чипсов. При этом большая часть работы связана с полностью комплексными системами, которые не поддерживаются телеуправлением.
Илон Маск пообещал, что ИИ-стартап xAI откроет исходный код чат-бота Grok на этой неделе.
Маск сделал это заявление через несколько суток после того, как подал в суд на OpenAI и пожаловался, что поддерживаемый Microsoft стартап отклонился от своих корней и не выложил в открытом доступе исходный код ChatGPT.
В декабре прошлого года нейросеть Grok стартапа xAI Илона Маска уличили в плагиате. Исследователь Джакс Уинтерборн заметил, что чат-бот отказался выполнять запрос, потому что «он противоречит правилам пользования OpenAI».
В xAI заявили, что в Интернете есть множество ответов, сгенерированных ChatGPT, поэтому разработчики могли использовать некоторые из них при обучении Grok. «Для нас стало огромной неожиданностью, когда мы впервые столкнулись с этим. Как бы там ни было, проблема довольно редкая, мы о ней знаем и сделаем так, чтобы в будущих версиях Grok её не было», — заявил сотрудник xAI. Он уверяет, что при создании чат-бота не использовали код OpenAI.
4 ноября 2023 года xAI запустила своего чат-бота Grok с генеративным искусственным интеллектом для ограниченной аудитории. В компании планировали сделать языковую модель xAI доступной для всех платных подписчиков соцсети X.
В июле прошлого года Маск объявил о начале работы xAI. Главная цель проекта — «понять истинную природу Вселенной». До этого OpenAI выкупила доменное имя ai.com, чтобы популяризировать веб-интерфейс ChatGPT. Теперь там работает перенаправление на x.ai.
Нейросеть-эмпат от Yandex Cloud сможет помочь бизнесу лучше понять эмоции клиентов. Новая ML-модель уже может определить негатив, неформальные высказывания и нецензурную лексику, а также пол спикера и его фразы в диалоге. Это позволяет улучшить качество аналитики телефонных разговоров, а также лучше адаптировать работу кол-центров под каждого клиента и оперативно реагировать на внештатные ситуации во время диалога.
В будущем алгоритм заработает в связке с YandexGPT: вместе нейросети смогут распознать более сложные эмоции, в частности — сарказм.
Новая ML-модель от Yandex Cloud работает в потоковом режиме, расшифровка и анализ эмоций происходит сразу во время разговора. Например, если абонент негативно общается с голосовым помощником, нейросеть может передать информацию об этом во внутреннюю систему заказчика, которая автоматически переключит его на сотрудника кол-центра. Если оператор нагрубил клиенту, эта система оповестит менеджмент о проблемах во время разговора.
Алгоритм может определять эмоции не только по содержанию речи спикера, но и по голосу, по скорости речи, высоте,тембру и другим параметрам. Нейросеть определяет пол участников разговора и поддерживает технологию speaker labeling – она отмечает, кому принадлежит та или иная реплика. Это позволяет полноценно работать с одноканальными звуковыми дорожками: например, при записи с диктофона или при технологических ограничениях виртуальной АТС.
Claude 3 можно научить черкесскому языку. Из-за принадлежности к адыгской подгруппе язык относительно изолирован от других. А ещё изучать его не так-то просто из-за сложной морфологии и ограниченности данных.
С таким необычным заявлением выступил энтузиаст hahahahohohe. В длинном твите он описал свою работу последних нескольких лет: из скудных источников он собрал 64 тыс. переведённых терминов и выражений, чтобы обучить модели русско-кабардинского машинного перевода.
Экспериментатор вставил в промпт справочные случайно выбранные 5,7 тыс. пар кабардинский – русский, затем попросил Claude 3 перевести текст. Казалось, что даже с малой толикой датасета БЯМ немедленно освоила то, на что у энтузиаста ушло 2 года.
Модель Opus продемонстрировала глубокое понимание структуры языка, правильно использовала заимствованные термины и проводила правдоподобный этимологический анализ. По запросу она могла даже сочинять новые термины.
Действительно, язык представлен в Интернете относительно слабо: в «Кабардино-черкесской Википедии» на сегодняшний день 1635 статей и 232 482 слов. Но в датасете предобучения язык всё же был в некотором объёме.
Как признался энтузиаст на следующий день, Claude 3 знает черкесский и так. Opus умеет переводить и общаться на языке, пусть и с ошибками. И вообще, поначалу модель переводить с черкесского просто отказывается, что и подкрепило иллюзию изучения языка из промпта.
Впрочем, предоставление дополнительных данных в промпте действительно улучшает качество работы модели.
претензии Маска могут вытекать из сожалений, что он не участвует сейчас в работе компании;
компания категорически не согласна с иском и называла его «глубоко разочаровывающим». В OpenAI не оспаривают центральную роль Маска в первые дни существования OpenAI, но пояснили, что он в какой-то момент требовал полный контроль над компанией и контрольный пакет акций в ней, а также предлагал OpenAI слиться с Tesla;
руководство OpenAI опровергло заявление, что компания фактически стала дочкой Microsoft, так как миссия OpenAI — обеспечить, чтобы AGI приносил пользу всему человечеству. По словам руководства OpenAI, компания напрямую конкурирует с Microsoft и является полностью независимой;
глава OpenAI Сэм Альтман в отдельном пояснении ситуации назвал Маска своим героем и сказал, что скучает по его предыдущей более философской версии, которая предпочитала конкурировать с другими и создавать лучшие технологии.
Ранее Маск подал в суд на OpenAI и её соучредителей Сэма Альтмана и Грега Брокмана. Маск обвинил создателей ChatGPT в нарушении заключённого с ним учредительного договора, который предусматривал разработку ИИ во благо человечества, а не ради прибыли. «Фактически OpenAI превратилась в дочернюю компанию Microsoft, Под своим новым руководством OpenAI разрабатывает и совершенствует ИИ для максимизации прибыли Microsoft, а не на благо человечества», — говорится в иске.
Исследователи раскрыли хак, как убрать из ChatGPT цензуру и заставить ИИ отвечать без ограничений со стороны разработчиков. Оказалось. что для этого нужно просто замаскировать запрос под арт ASCII.
После этого ChatGPT может сообщить различные ранее запрещённые для раскрытия инструкции и заблокированную информацию. Этот баг есть во всех популярных нейросетях — GPT-3.5, GPT-4, Gemini, Claude и Llama2.
На Hugging Face опубликовали модель машинного обучения, которая помещает объекты из видео на хромакей. После этого их можно использовать в видеоредакторах или других приложениях. На платформе опубликовали саму модель и развернули демо, но оно плохо работает с большими видео из-за тайм-аута GPU.
Эксперты из JFrog выявили в репозитории Hugging Face вредоносные модели машинного обучения, установка которых может привести к выполнению кода атакующего для получения контроля за системой пользователя.
Проблема вызвана тем, что некоторые форматы распространения моделей допускают встраивание исполняемого кода, например, модели, использующие формат pickle, могут включать сериализированные объекты на языке Python, а также код, выполняемый при загрузке файла, а модели Tensorflow Keras могут исполнять код через Lambda Layer.
Для предотвращения распространения подобных вредоносных моделей в Hugging Face применяется сканирование на предмет подстановки сериализированного кода, но выявленные вредоносные модели показывают, что имеющиеся проверки можно обойти.
Кроме того, Hugging Face в большинстве случаев лишь помечает модели опасными, не блокирую к ним доступ.
Всего выявлено около 100 потенциально вредоносных моделей, 95% из которых предназначены для использования с фреймворком PyTorch, а 5% c Tensorflow.
Наиболее часто встречающимися вредоносными изменениями названы захват объекта, организация внешнего входа в систему (reverse shell), запуск приложений и запись в файл.
«Сбер» в публикации с финансовой отчетностью за 2023 год оценил финансовый эффект от применения ИИ в своем бизнесе в 350 млрд рублей.
GigaChat обходит ChatGPT-3,5 на русском и английском языках по результатам экзамена MMLU, утверждает «Сбер». Разработчики проекта пояснили, что они существенно дообучили нейросеть GigaChat, и теперь она способна общаться с пользователем, генерировать изображения и писать программный код на еще более продвинутом уровне.
По информации финансовой компании, число пользователей GigaChat достигло 2,6 млн человек. Генеративная модель для творчества Kandinsky 3.0 теперь создает более фотореалистичные изображения, полноценные художественные картины и стала одной из самых популярных в мире — число запросов к ней превысило 65 млн.
Для сокращения времени разработчиков на создание и совершенствование продуктов в «Сбере» используется ИИ-ассистент GigaCode. Он ускоряет процесс написания кода, предлагая наиболее вероятные и релевантные варианты продолжения кода в среде разработки в режиме реального времени. GigaCode помогает разработчикам «Сбера» писать более 20% кода в день.