PostgreSQL: PostgreSQL 17 Beta 1 Released!
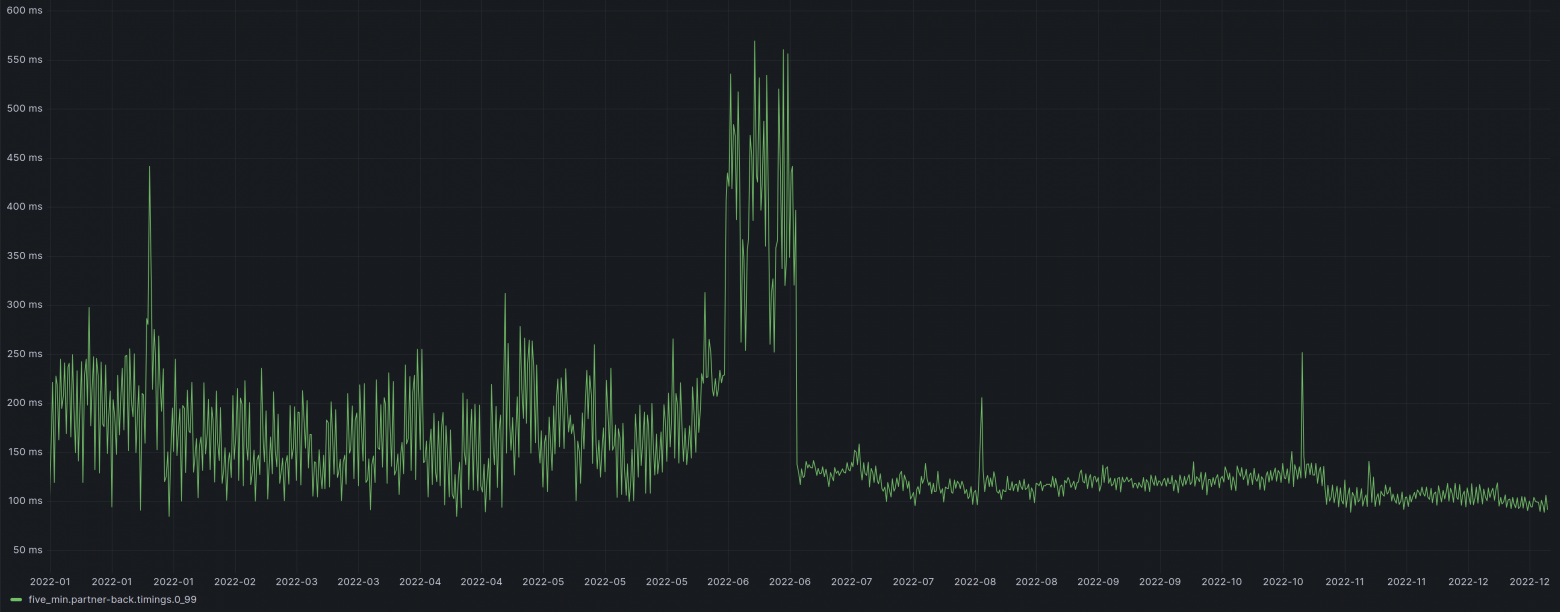
Вышла бета с 188 новшествами. Напомним, что Брюс Момджан недавно подчёркивал важность этого релиза из-за его некоторого уклона в оптимизацию, мол, большое число улучшений в оптимизации, это приятный сюрприз для меня.
В пояснительной записке к релизу тоже начинают с оптимизации. Первым делом рассказывают об изменениях в Vacuum. Там новая внутренняя структура, благодаря которой удалось сэкономить 20% памяти, а также сократить время самой очистки. Последний пункт касается редкой темы: в PostgreSQL 17 улучшена поддержка SIMD-инструкций.
Интересный, важный пункт - управление переключением при логической репликации (failover control for logical replication), важное для отказоустойчивых конфигураций.
В SQL/JSON появилась важнейшая вещь - JSON TABLE, это новый уровень работы с этим форматом. Также появились новые конструкторы и другие функции.