
Как расширить возможности стандартного Enum
Простой
5 мин

А может всё-таки есть способ сделать такой Enum, используя стандартную библиотеку Python?!
Под катом будем разбираться в существующих вариантах решения.
А может всё-таки есть способ сделать такой Enum, используя стандартную библиотеку Python?!
Под катом будем разбираться в существующих вариантах решения.

Привет, Хабр!
Мульти-тенант (multi-tenancy) — это подход, который позволяет одному экземпляру приложения обслуживать множество клиентов или арендаторов (тенатов). Каждый арендатор изолирован от других, имея возможность кастомизации под свои нужды, при этом основной кодовой базой и инфраструктурой делится между всеми.
Когда применять эту замечательную концепцию? Если говорить простыми словами, то мульти-тенант подход наиболее ценен для SaaS-продуктов, когда одно и то же приложение предоставляется разным клиентам, и каждый клиент работает со своим набором данных. Все это серьезно экономит ресурсы на обслуживание инфраструктуры, тк все изменения вносятся централизованно и мгновенно становятся доступны всем клиентам.
В Django мульти-тенант реализовывается довольно часто и для этого есть библиотека django-multitenant.

Иногда возникают проблемы с развертыванием среды разработки в облаке, ведь бесплатных сервисов с большими облачными вычислительными мощностями почти нет. Тот же Google Collab имеет свои лимиты по использованию GPU, после израсходования всей памяти необходимо ждать сутки. А цена платной версии порой не совсем оправдана... Если у вас есть своя неплохая видеокарта, всегда можно отказаться от облачной разработки и перейти к домашнему варианту.
Напоминаем, что GPU выполняет вычислительную работу быстрее из-за возможности параллельного выполнения процессов. Если вы хотите использовать много видеокарт? то следует подключить ее к одной системе, сформировав своеобразную ферму.
Итак, как же контейнизировать собственную виртуальную среду и развернуть ее с использованием своего GPU?

Как запустить локально LLM 70B параметров на 1 видеокарте с 24gb? Нужно квантование!
Квантование - это процесс уменьшения битности вычислений в нейронной сети, используемых для представления весов, смещений и активаций. Путем снижения точности мы можем значительно сократить требования к памяти и вычислительной сложности модели.

Данная статья входит в цикл, освещающий задачи на моделирование физических процессов на факультете МФТИ ВШПИ. В этой части речь пойдёт про задачу моделирования поведения маятника: коротко разберём теорию, которая лежит в основе модели, немного подумаем над архитектурой и напишем небольшое приложение на связке Python + Tkinter. Реализация будет поддерживать исследование различных маятников с помощью самописных динамических графиков, в которые пользователь может ввести собственные формулы.
 Привет, Хаброжители!
Привет, Хаброжители!
В этом материале мы поговорим об устройстве компонента‑декодера в системах машинного обучения, построенных по архитектуре «трансформер», уделив особое внимание отличию декодера от энкодера. Уникальной особенностью декодеров является то, что они похожи на циклы. Они, по своей природе, итеративны, что контрастирует с линейными принципами обработки данных, на которых основаны энкодеры. В центре декодера находятся две модифицированные формы механизма внимания: механизм множественного внимания с маскировкой (masked multi‑head attention) и механизм множественного внимания энкодера‑декодера (encoder‑decoder multi‑head attention).
Слой множественного внимания с маскировкой в декодере обеспечивает последовательную обработку токенов. Благодаря такому подходу предотвращается воздействие последующих токенов на сгенерированные токены. Маскировка важна для поддержки порядка следования и согласованности сгенерированных данных. Взаимодействие между выходом декодера (из слоя множественного внимания с маскировкой) и выходом энкодера организовано с помощью механизма множественного внимания энкодера‑декодера. Этот последний шаг даёт декодеру доступ к входным данным.
Мы, кроме того, продемонстрируем реализацию этих концепций с использованием Python и NumPy. Мы создали простой пример перевода предложения с английского языка на португальский. Практическая демонстрация обсуждаемых здесь идей поможет проиллюстрировать работу внутренних механизмов декодера в трансформерах и позволит лучше понять роль декодеров в больших языковых моделях (Large Language Model, LLM).

Привет, Хабр!
Аналитики данных часто сталкиваются с грязными данными, которые могут существенно замедлить процесс анализа. Грязны данные – это пропущенные значения, дубликаты, неконсистентные данные. Пропущенные значения заставляют нас гадать, что же было замыслено нашим коллегой; дубликаты вводят в заблуждение, умножая одно и то же на количество их копий, а неконсистентные данные заставляют нас сомневаться в каждой цифре.
Очищать грязные данные можно c Pandas. Рассмотрим основные методы.

Привет, Хабр!
Celery – это асинхронная распределенная очередь задач, написанная на Python, она предназначена для обработки сообщений в реальном времени при помощи многозадачности. Используя Celery, можно организовать выполнение задач в фоновом режиме, не загружая основной поток приложения.
Используя Celery можно легко организовать выполнение фоновых задач.

«Зачем мне SQL и python?» — задают резонный вопрос маркетологи или менеджеры по продукту, особенно в сфере недвижимости, оптовой торговли, услуг для бизнеса: «У нас нет миллионов строк данных, нет логов, мы успешно работаем с несколькими таблицами в excel».
Да действительно, у вас может не быть корпоративного хранилища данных в компании, и основой автоматизации работы с данными является Power query (что сейчас в РФ делать все труднее и труднее). Но у вас точно есть данные, которые вы получаете от смежных отделов, из CRM/CDP, MES, АСУ ТП. Эти данные приходят регулярно в виде файлов, и вы сопоставляете эти данные друг с другом с помощью ВПР, фильтруете воронкой, чистите с помощью «Найти или заменить», делайте сводники с помощью функции Pivot table.
AI-сервис Phind - ассистент по программированию для не программистов. Или как я автоматизировал свою рабочую задачу, не написав самостоятельно ни строчки кода.

Одно из самых прикладных применений языковых моделей (LLM) - это ответы на вопросы по документу/тексту/договорам. Языковая модель имеет сильную общую логику, а релевантные знания получаются из word, pdf, txt и других источников.
Обычно релевантные тексты раскиданы в разных местах, их много и они плохо структурированы. Одна из проблем на пути построения хорошего RAG - нахождение релевантных частей текста под заданный пользователем вопрос.
Еще В. Маяковский писал: "Изводишь единого слова ради, тысячи тонн словесной руды." Примерно это же самое делают би-энкодеры и кросс-энкодеры в рамках RAG, ищут самые важные и полезные слова в бесконечных тоннах текста.
В статье мы посмотрим на способы нахождения релевантных текстов, увидим проблемы, которые в связи с этим возникают. Попытаемся их решить.
Главное - мы натренируем свой кросс-энкодер на русском языке, что служит важным шагом на пути улучшения качества Retrieval Augmented Generation (RAG). Тренировка будет проходит новейшим передовым способом. Схематично он изображен на меме справа)

При запуске сервера часто необходимо предоставить доступ к части функционала другим пользователям, при этом сами пользователи могут не иметь достаточных компетенций для полноценного использования софта и/или мы хотим ограничить доступный набор команд.
Одним из вариантов решения является Telegram-бот, который является прослойкой между пользователем и софтом. С таким решением я встречался на реальном опыте уже как минимум два раза, и на основе одного из них я постараюсь объяснить, как это можно сделать.

В этой статье мы поговорим о Биткоин утилитах которые многочисленны и разнообразны. Его децентрализованный характер и отсутствие посредников делают его мощным инструментом для самых разных случаев использования. Поскольку технология продолжает развиваться и развиваться, мы можем ожидать увидеть еще более инновационные применения Биткоина в будущем.
Биткоин — первая в мире децентрализованная цифровая валюта, которая произвела революцию в нашем представлении о деньгах. Одним из наиболее интересных аспектов Биткоина является широкий спектр утилит, разработанных для его поддержки. Эти утилиты призваны помочь пользователям безопасно и надежно взаимодействовать с сетью Биткоин и играют решающую роль в экосистеме.
Одной из самых популярных биткоин-утилит является биткоин-кошелек. Кошелек — это программное приложение, которое позволяет пользователям хранить, отправлять и получать биткоины. Доступно множество различных типов кошельков, включая настольные, мобильные и аппаратные кошельки. Каждый тип кошелька имеет свои преимущества и недостатки, поэтому важно выбрать тот, который лучше всего соответствует вашим потребностям.
Еще одна важная утилита Биткоин — это обмен биткоинов. Биржа — это платформа, которая позволяет пользователям покупать и продавать биткоины за другие валюты, такие как доллары США или евро. Доступно множество различных бирж, каждая со своим набором комиссий, функциями безопасности и пользовательскими интерфейсами. Важно выбрать биржу с хорошей репутацией, имеющую хорошую репутацию в области безопасности и надежности.
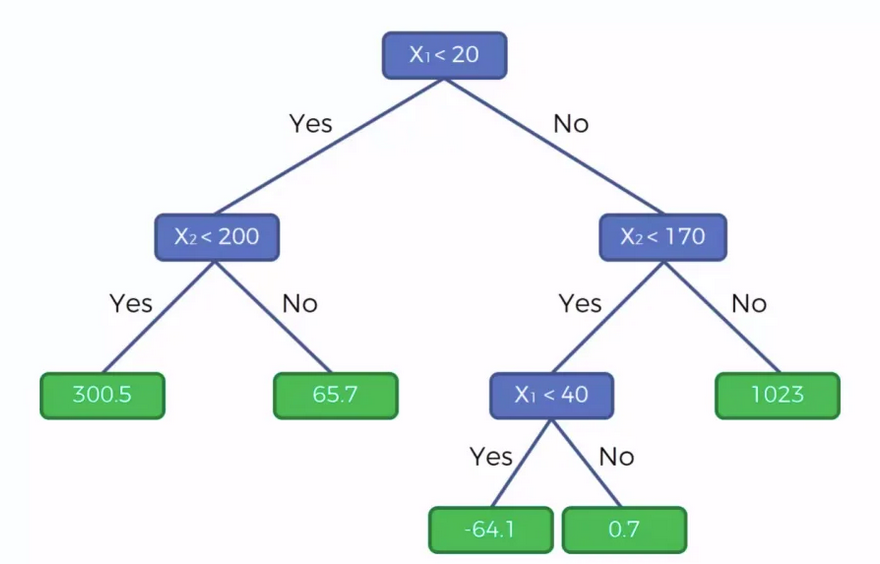
Объяснение «на пальцах» и реализация решающего дерева, случайного леса и бустинга.
Дерево принятия решений (также называют деревом классификации или регрессионным деревом) — средство поддержки принятия решений, использующееся в машинном обучении, анализе данных и статистике. Структура дерева представляет собой «листья» и «ветки». На рёбрах («ветках») дерева решения записаны признаки, от которых зависит целевая функция, в «листьях» записаны значения целевой функции, а в остальных узлах — признаки, по которым различаются случаи. Чтобы классифицировать новый случай, надо спуститься по дереву до листа и выдать соответствующее значение.

В предыдущей (вводной) статье мы дали определения и математическое описание базовым понятиям связанным с Uplift моделированием. Рассмотрели принцип работы популярных Uplift моделей и их недостатки, а так же установили, как мы рассчитываем итоговый инкремент  , дали определения контрольной
, дали определения контрольной  и тестовой
и тестовой  группам. А так же условились, что же такое воздействие
группам. А так же условились, что же такое воздействие на пользователя
на пользователя  .
.
Среди проблем с которыми сталкиваются современные Uplif модели, пожалуй, самая серьезная - counterfactual sample pairs problem, рассмотренная так же в предыдущей статье.
Данная статься посвящена как раз нивелированию данной проблемы. Так как мы используем архитектуру KDSM Uplift modeling, то первые две буквы аббревиатуры (KD - Knowledge Distillation) представляют собой название модели, задача которой является создание подмножеств генерального множества, таким образом чтобы минимизировать или же по крайней мери свести к минимуму влияния counterfactual sample pairs problem на результат и точность итоговой модели. Само по себе слово Distillation намекает, что мы будем стремиться стратифицировать множество таким образом, чтобы можно было найти “похожих” друг на друга пользователей  и
и  из
из  и
и  соответственно, объединить их в одно подмножество, чтобы в дальнейшем можно было сделать допущение, что
соответственно, объединить их в одно подмножество, чтобы в дальнейшем можно было сделать допущение, что  и
и  представляют из себя уже единого синтетического пользователя
представляют из себя уже единого синтетического пользователя  . Где пользователь
. Где пользователь  вместе с его параметрами
вместе с его параметрами  выполняет роль пользователя
выполняет роль пользователя , с которым мы не взаимодействовали
, с которым мы не взаимодействовали  , а пользователь
, а пользователь  вместе с его параметрами
вместе с его параметрами  выполняет роль пользователя
выполняет роль пользователя  , с которым мы провзаимодействовали
, с которым мы провзаимодействовали  .
.
Жизнь — это бесконечное совершенствование. Считать себя совершенным — значит убить себя. (Георг Гегель)
Для кого статья:
• для начинающих специалистов - подглядеть пару конструкций
• для среднеопытных - порадовать свою самооценку

Эта короткая статья посвящена приблизительному описанию того, что происходит в моём инструменте для смешивания красок.
Инструмент предназначен для виртуального смешения красок, он содержит солвер, генерирующий рецепты для создания цвета из имеющихся красок. Инструмент поставляется с замеренными мной данными для красок Kimera. Он написан на Python 3; в репозитории есть все исходники, и если у вас есть дистрибутив Python, то его можно просто запустить. Также в репозитории есть исполняемый файл Windows, созданный при помощи PyInstaller (см. раздел Releases справа). Ещё я добавил версию для Mac; это файл .dmg и в нём что-то есть, а если нажать на него, инструмент запустится, так что, кажется, всё работает. Но, честно говоря, я редко пользуюсь Mac, поэтому мне сложно сказать, есть ли там всё нужное, или требуется что-то ещё...
Вы можете просто скачать инструмент и экспериментировать с ним. Развлекайтесь, надеюсь, он покажется вам хоть немного полезным.
Ниже представлено более-менее полное описание его работы (и условия, при которых он не работает).
«Мы всего лишь хотели пофиксить баги в своем продукте, а психанули и создали аналог одной из библиотек» — CV-инженеры CodeInside.
Итак, в созданной нами системе мониторинга транспортного потока Smart Traffic System доступен функционал по распознаванию номерных знаков автомобилей.
Для работы этой функции ранее мы использовали библиотеку автоматического определения и распознавания автомобильных номеров — opensource-решение Nomeroff-net.
Однако, во время пользования этой библиотекой, столкнулись с долгим запуском и inference + библиотека занимала большое количество оперативной памяти. Так как мы решали эти проблемы в коммерческом проекте, кода здесь не будет. И вместе с тем, в статье указали репозиторий, конкретные шаги решения, чтобы при возникновении аналогичных проблем, вы смогли адаптировать его под свой проект.

Итак, что же поменялось за чуточку больше чем полгода? Если мы будем говорить об актуальности - ничего. Django до сих пор, а скорее всего так будет и всегда, остается "на плаву". Большая часть вакансий для back-end разработчика на Python имеет в себе требования по знаниям Django. Говорить вечно о том, что он удобен, постоянно поддерживаем, дает довольно обширный функционал и так далее - бессмысленно. Все основные моменты я упомянул в первой части.
Ладно, вступление в сторону! Лучше обсудить то, что изменилось с Django за это время.
Самое грандиозное из этого - выход Django 5! По сути скачок на пятую версию не принес в фреймворк особо крупных изменений, но парочку моментов хочу подчеркнуть. Первое и самое важное, на мой взгляд, это то, что разработчики решили добавить больше асинхронности без подключения таск-менеджеров. Для этого они добавили несколько декораторов и методов. Хотя это немного, на мой взгляд, противоречит самому принципу работы Django (напоминаю: Django синхронный фреймворк и для того, чтобы сделать очередь задач, нужно подключать таск-менеджеры, например, Celery), но тем не менее, это все равно крутой шаг в эволюцию. Надеюсь, что разработчики и дальше будут двигаться в этом направлении.
Далее, не могу не упомянуть очень важный момент - совместимость с Python. Django 5 будет работать только с версиями Python 3.10 и выше. Django 4.2.x - последняя версия, которая работает с Python 3.8 и 3.9.
Остальное я могу отнести в одну кучу: добавление фасетных фильтров в админке, упрощение шаблонов для отрисовки полей формы, прикольная, на мой взгляд, функция для значений по умолчанию, вычисленных базой данных, и еще пару приколюх с БД. Все остальное и более подробно вы сможете почитать в официальной документации. Я же не буду все разжевывать, так как отойду от темы статьи.