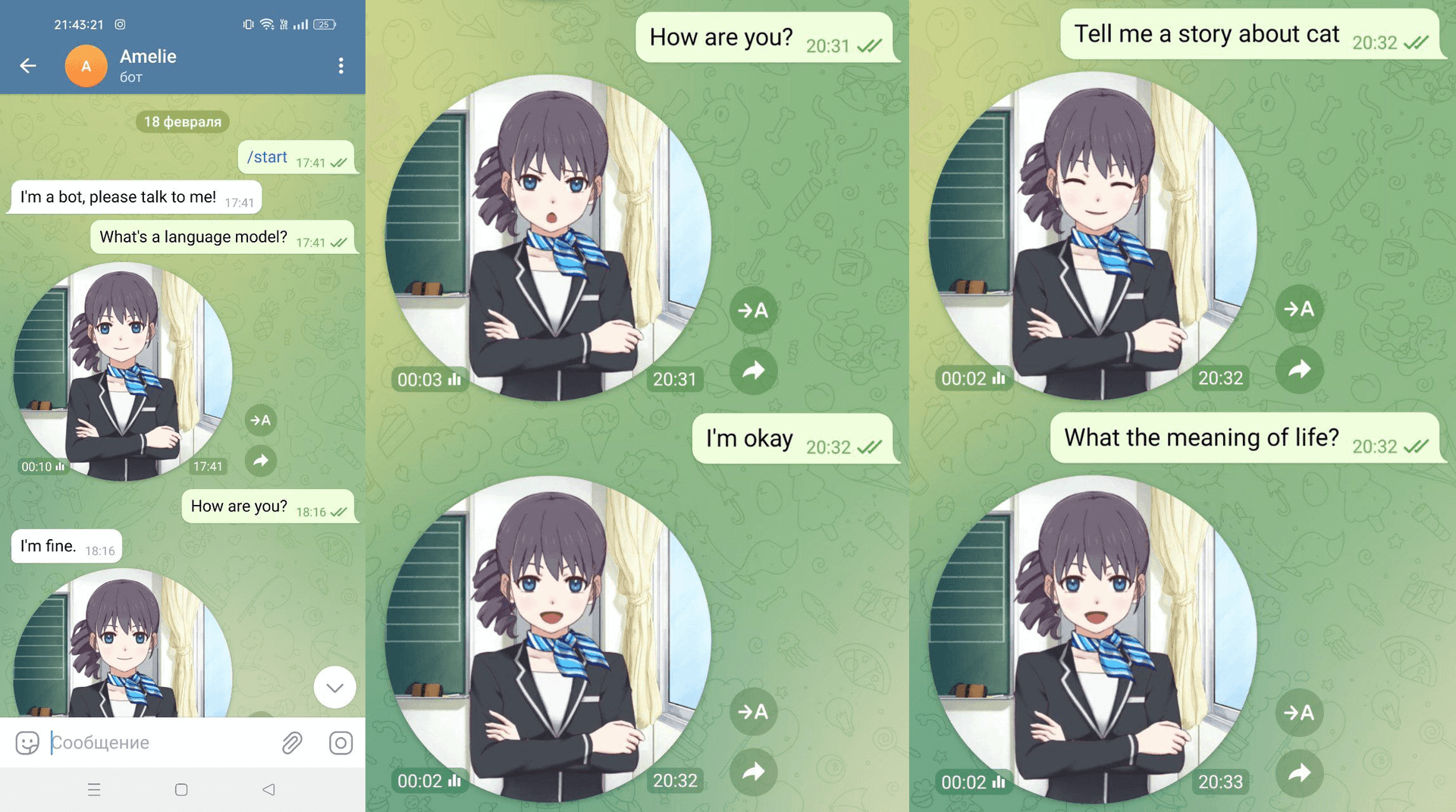
Данная статья является вольным переводом статьи на medium.com, плюсом от себя реализация API ChatGPT в Телеграм боте.
Тема как написать телеграм бота уже довольно тривиальная, статей в интернете полно, поэтому тут я затронул это дело не так глубоко, ниже выложу ссылки на исходный код, разобраться будет не сложно. Основным мотивом написания статьи послужил тот факт, что ChatGPT не доступен в ряде стран, в том числе в России, и хотелось сделать его по настоящему общедоступным.
Готовый/работающий телеграм бот ChatGPT доступен тут.
На вопрос "Кто ты?" сама нейросеть отвечает примерно следующее "Я - ChatGPT, крупнейшая языковая модель, созданная OpenAI. Я разработана для обработки естественного языка и могу помочь вам ответить на вопросы, обсудить темы или предоставить информацию на различные темы".
Другими словами, по моему субъективному мнению нейросеть затачивается в первую очередь для поддержки разговора, в идеале показать, что там сидит живой человек, а не обученная AI модель. Поэтому когда будете играть с чатом не забывайте об этом, не следует ожидать от чата достоверных и точных данных, или глубокого смысла, сейчас она не об этом, пока еще не об этом.
Итак, как получить доступ к сервису ChatGPT из запрещенных стран написано в статье на хабре, хочу обратить ваше внимание, что будет необходимо сперва создать gmail почту с подтверждением по СМС на иностранный номер телефона, затем при регистрации на сайте ChatGPT также подтвердить номер телефона по СМС, и эти два номера телефона совсем не обязательно должны быть одинаковыми, поэтому сервисы по продаже номеров мобильных телефонов на одну смс вполне годятся.