Работа с квалифицированными сертификатами в свете новой редакции Приказа №795 ФСБ РФ от 29 января 2021 года
10 мин
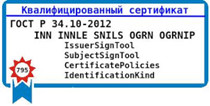 7 сентября 2021 года мне пришло электронное письмо:
7 сентября 2021 года мне пришло электронное письмо:fsb795Было понятно, что речь идет о пакете fsb795, написанном на Python для разбора квалифицированных сертификатов. Требования к составу и форме квалифицированного сертификата установлены Приказом ФСБ России от 27.12.2011 №795. Но 29 января 2021 года в этот приказ были внесены изменения. Именно об этих изменениях мне и напомнил автор письма. Письмо я получил 7 сентября, а изменения вступили в силу 1-го сентября 2021 года. В этот период времени я был увлечён написанием статьи, связанной с пятидесятилетием окончания Казанского суворовского военного училища и выбора мною стези программиста:
Добрый день.
не планируете библиотеку подправить под свежие изменения в приказе 795 ?