Тестирование производительности Python ORM методом, основанном на бенчмарке TPC-C
При написании приложений на Python, для работы с базами данных часто используются объектно-реляционные мапперы (ORM). Примерами ORM являются SQLALchemy, PonyORM и объектно-реляционный маппер, входящий в состав Django. При выборе ORM довольно важную роль играет её производительность.
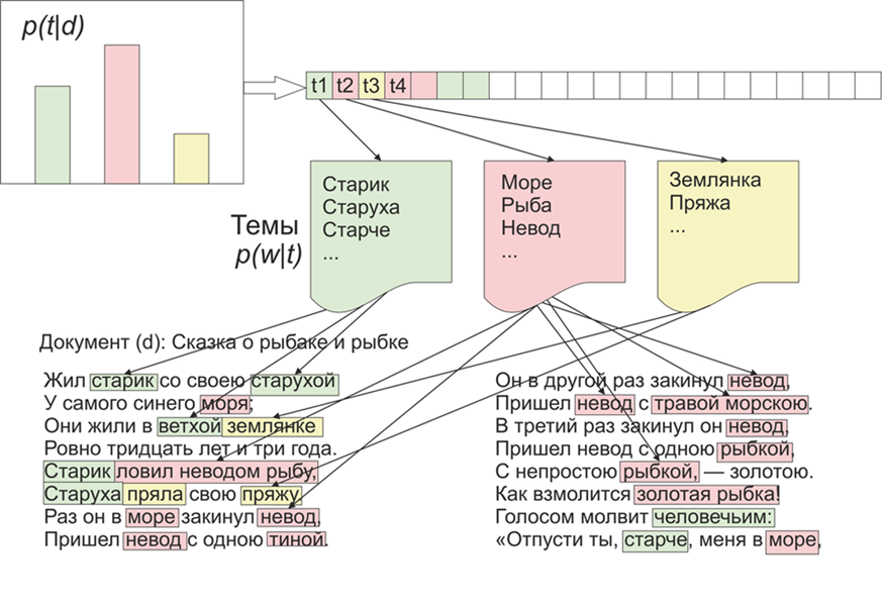
На Хабре, да и в интернете в целом, можно найти не один тест производительности. Как пример качественного бенчмарка python ORM можно привести бенчмарк от Tortoise ORM (ссылка на репозиторий). Данный бенчмарк анализирует скорость работы шести ORM для одиннадцати различных видов SQL-запросов.
В целом бенчмарк от tortoise хорошо позволяет оценить скорость выполнения запросов при использовании разных ORM, но у такого подхода к тестированию я вижу одну проблему. ORM зачастую используют в веб приложениях, где одновременно несколько пользователей могут посылать различные запросы, но я не нашел ни одного бенчмарка, оценивающего работу ORM при таких условиях. Вследствие этого я решил написать свой бенчмарк и сравнить с помощью него PonyORM и SQLAlchemy. За основу я взял бенчмарк TPC-C.