Как я обошёл запрет на Messages API через документацию Вконтакте
5 мин
Привет всему Хабро-сообществу. Для меня эта первая статья и пишется она под определённой эйфорией, так что прошу не судить эту статью слишком строго за литературную часть. Но что же, меньше слов и переходим к делу.
Все мы знаем, что у ВК есть API, и я уверен, что большинство людей пыталось им воспользоваться в своих целях. Лично у меня полно проектов, связанных с ним: штук 5 мощных ботов, составление масштабных датасетов из постов групп и т.д. И не удивительно, что мои знакомые просили меня пару раз выкачать песни из вложений диалога, фотографии или же сохранить текст переписок с каким-нибудь человеком в отдельный файл.
Но однажды пришло «оно», и с того момента выполнение таких небольших просьб перестало быть тривиальной задачей:
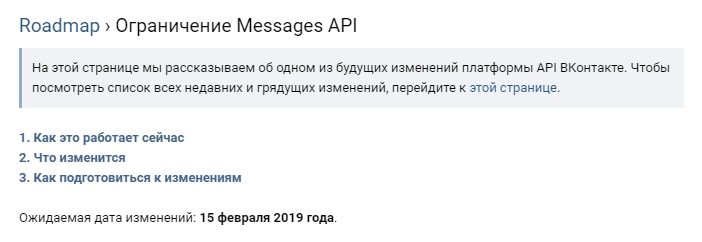
И вот, пару дней назад, чтобы раз и навсегда избавиться от этой проблемы, я решил написать свою обёртку через http запросы, притворяясь обычным пользователем, дабы иметь такой же мощный инструмент, как официальный API для раздела messages.
С чего всё началось
Все мы знаем, что у ВК есть API, и я уверен, что большинство людей пыталось им воспользоваться в своих целях. Лично у меня полно проектов, связанных с ним: штук 5 мощных ботов, составление масштабных датасетов из постов групп и т.д. И не удивительно, что мои знакомые просили меня пару раз выкачать песни из вложений диалога, фотографии или же сохранить текст переписок с каким-нибудь человеком в отдельный файл.
Но однажды пришло «оно», и с того момента выполнение таких небольших просьб перестало быть тривиальной задачей:
И вот, пару дней назад, чтобы раз и навсегда избавиться от этой проблемы, я решил написать свою обёртку через http запросы, притворяясь обычным пользователем, дабы иметь такой же мощный инструмент, как официальный API для раздела messages.


")