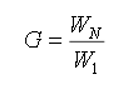Вредные заклинания в программировании
3 мин
Перевод
С тех пор, как я посмотрел легендарное видео Wat Гэри Бернхардта, меня завораживает странное поведение некоторых языков программирования. Некоторые из них таят больше сюрпризов, чем другие. Например, для Java написана целая книга с описанием пограничных ситуаций и странной специфики. Для C++ вы просто можете почитать сами спецификации всего за $200. 
Далее поделюсь с вами моей коллекцией самых неожиданных, забавных и всё-таки валидных «заклинаний» программирования. По сути, использование этих особенностей поведения ЯП считается пагубным, поскольку ваш код никоим образом не должен быть непредсказуемым. Хорошо, что многие линтеры уже осведомлены и готовы посмеяться над вами, если попробуете какое-то из перечисленных дурачеств. Но как говорится, знание — сила, так что начнём.
Далее поделюсь с вами моей коллекцией самых неожиданных, забавных и всё-таки валидных «заклинаний» программирования. По сути, использование этих особенностей поведения ЯП считается пагубным, поскольку ваш код никоим образом не должен быть непредсказуемым. Хорошо, что многие линтеры уже осведомлены и готовы посмеяться над вами, если попробуете какое-то из перечисленных дурачеств. Но как говорится, знание — сила, так что начнём.
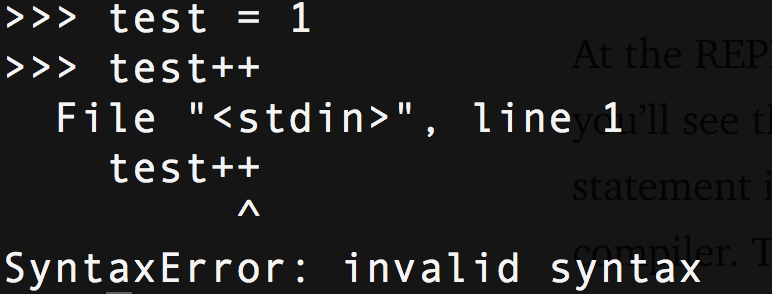
 .
.
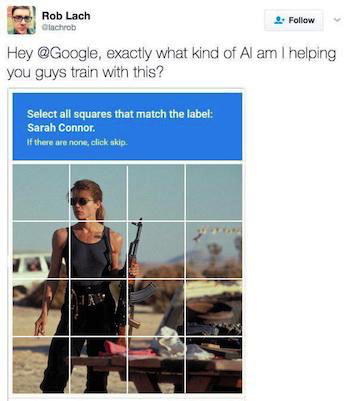
 Всем привет! Это уже двадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python.
Всем привет! Это уже двадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python. 










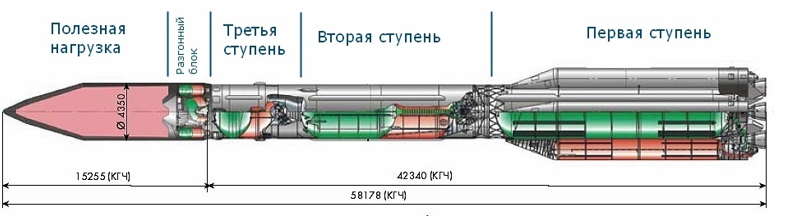
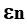 и скорость реактивной струи Cn постоянны на каждой ступени, однако на разных ступенях могут принимать различные значения. В обеих задачах в качестве целевой функции принят коэффициент полезной нагрузки ракеты G, который необходимо минимизировать.
и скорость реактивной струи Cn постоянны на каждой ступени, однако на разных ступенях могут принимать различные значения. В обеих задачах в качестве целевой функции принят коэффициент полезной нагрузки ракеты G, который необходимо минимизировать.