Есть множество подходов к созданию кода приложений, направленных на то, чтобы сложность проекта не росла со временем. Например, объектно-ориентированный подход и множество прилагаемых паттернов, позволяют если не удерживать сложность проекта на одном уровне, то хотя бы держать ее под контролем в ходе разработки, и делать код доступным для нового программиста в команде.
Как можно управлять сложностью проекта по разработке ETL-трансформаций на Spark?
Тут все не так просто.
Как это выглядит в жизни? Заказчик предлагает создать приложение, собирающее витрину. Вроде бы надо выполнить через Spark SQL код и сохранить результат. В ходе разработки выясняется, что для сборки этой витрины требуется 20 источников данных, из которых 15 похожи, остальные нет. Эти источники надо объединить. Далее выясняется, что для половины из них надо писать собственные процедуры сборки, очистки, нормализации.
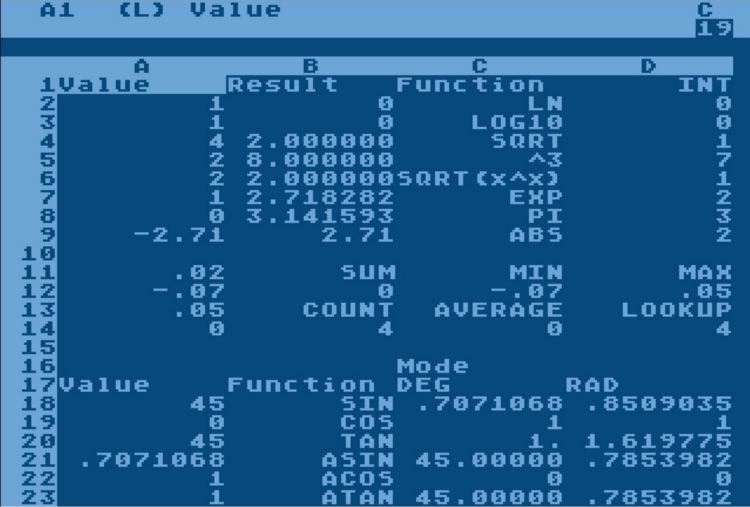
И простая витрина после детального описания начинает выглядеть примерно так:
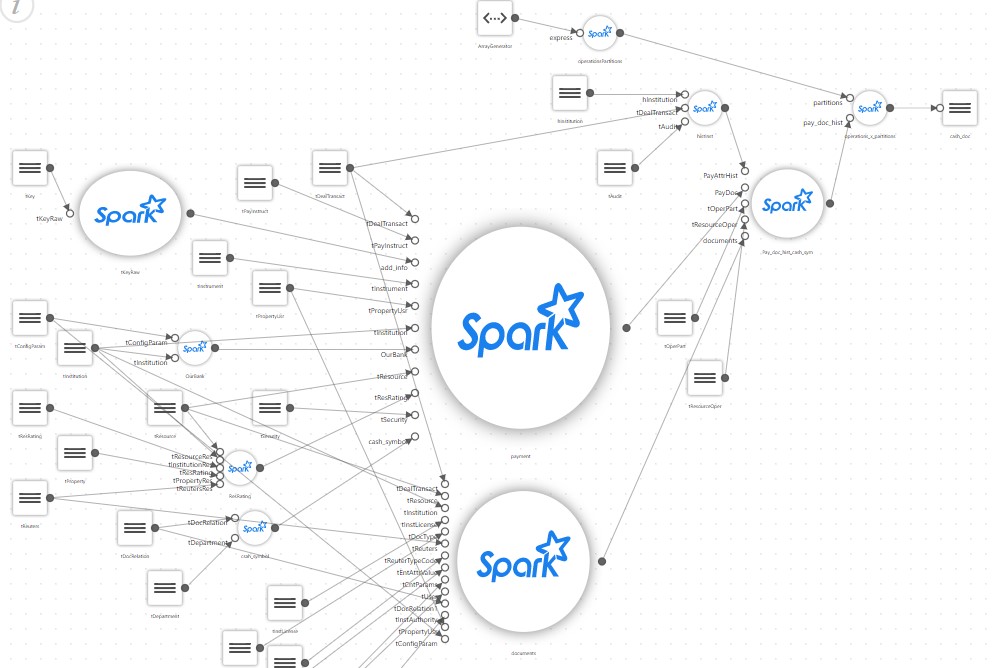
В результате простой проект, который должен был всего лишь запустить на Spark скрипт SQL собирающий витрину, обрастает собственным конфигуратором, блоком чтения большого числа настроечных файлов, собственным ответвлением маппинга, трансляторами каких-нибудь специальных правил и т.д.