

Доброго времени суток. Основываясь на своём опыте хочу представить некоторые рекомендации при разработке кодовой базы на SQL.
Данные рекомендации получены горьким опытом, так что надеюсь, они Вам помогут :)
Доброго времени суток. Основываясь на своём опыте хочу представить некоторые рекомендации при разработке кодовой базы на SQL.
Данные рекомендации получены горьким опытом, так что надеюсь, они Вам помогут :)

«Зачем мне SQL и python?» — задают резонный вопрос маркетологи или менеджеры по продукту, особенно в сфере недвижимости, оптовой торговли, услуг для бизнеса: «У нас нет миллионов строк данных, нет логов, мы успешно работаем с несколькими таблицами в excel».
Да действительно, у вас может не быть корпоративного хранилища данных в компании, и основой автоматизации работы с данными является Power query (что сейчас в РФ делать все труднее и труднее). Но у вас точно есть данные, которые вы получаете от смежных отделов, из CRM/CDP, MES, АСУ ТП. Эти данные приходят регулярно в виде файлов, и вы сопоставляете эти данные друг с другом с помощью ВПР, фильтруете воронкой, чистите с помощью «Найти или заменить», делайте сводники с помощью функции Pivot table.
Как бы вы решали такую задачу? Предположим, есть таблица с купонами, и у купонов есть некая дата устаревания valid_until. Вам надо обеспечить такое ограничение (constraint) на уровне БД, чтобы у одного человека мог быть только один действующий купон.
Т.е., таблица изначально выглядит так:
CREATE TABLE coupons (
id bigint primary key generated by default as identity,
user_id bigint not null,
created_at timestamp not null,
valid_until timestamp not null
)
Всем привет! Я расскажу, с помощью каких алгоритмов и архитектуры можно разработать с нуля интерактивную диаграмму Ганта, способную без лагов отображать тысячи задач.
Статей о селектах хватает, попробуем про апдейты. "ТОП-100" вопросов не обещаю - тут бы с одним разобраться. Разработчиков OLTP-систем под MS SQL Server и кандидатов на подобные вакансии приглашаю под кат.
Код на T-SQL, и он идеален. Атомарности нет, целостность вернём ручными апдейтами, изоляция с дюрабилити только мешают. Программируем без оглядки на ACID, который жив лишь в статье википедии.

Всем привет! Искусственный интеллект уже научился писать простые запросы к базам данных, но можно ли совсем избавиться от кода в работе аналитиков? Мы расскажем про наши нейросетевые эксперименты, в которых мы научили BI-систему слушать, понимать и отрабатывать запросы аналитиков на естественном языке.
В команде R&D SberData мы ищем и разрабатываем технологии обработки, хранения и анализа данных Сбера. Мы исследуем все перспективные технологии, которые появляются на рынке, разрабатываем новые продукты, которые использует Сбер и его партнёры. Одно из приоритетных направлений для нас — это анализ данных. В Сбере более 100 тысяч пользователей BI (Business Intelligence). Естественно, что у такого количества аналитиков самые разные потребности и требования к сервису и продукту. И возможность сделать их работу проще и удобнее — это большой вызов и интересная задача для нашей команды. В этот раз мы пробовали научить LLM-модель написать правильный SQL-код по запросу на естественном языке.

С выходом PostgreSQL 15 мы застали появление долгожданной команды MERGE, которая позволяет реализовывать эффективные способы синхронизации обновлений.
Суть MERGE заключается в ее универсальности: она позволяет объединить операции INSERT, UPDATE и DELETE в одном запросе, автоматически выбирая нужное действие в зависимости от того, существует ли соответствующая запись в целевой таблице.
Вместо нескольких отдельных запросов INSERT, UPDATE, DELETE MERGE сокращает накладные расходы на сетевой трафик и уменьшает количество обращений к диску. MERGE облегчает реализацию шаблонов SCD и других сложных сценариев управления данными.
MERGE в PostgreSQL работает с соблюдением строгих стандартов SQL, обеспечивая совместимость и переносимость кода. Также PostgreSQL обрабатывает конфликты на уровне строк, позволяя тонко настраивать логику обработки данных с использованием условий WHEN MATCHED и WHEN NOT MATCHED.
Сравнивая с предшествующим подходом INSERT ON CONFLICT, MERGE предлагает больше возможностей для оптимизации и управления данными. INSERT ON CONFLICT был ориентирован преимущественно на обработку конфликтов при вставке, в то время как MERGE расширяет этот функционал.

SQL (Structured Query Language) – это язык программирования, используемый для управления реляционными базами данных. В этой статье я собрал вопросы по SQL, с которыми вы можете столкнуться на собеседовании. Их часто задают для проверки общих знаний и навыков.

Если проект использует реляционную СУБД обязательно возникнет вопрос - как организовать скрипты для сохранения гибкости и уменьшения трудозатрат.

В минувшем году все только и говорили об ИИ и о том, как он может всё за вас сделать.
Мне нравится, когда кто-то или что-то работает за меня. Поэтому решил: попрошу-ка ChatGPT написать за меня новогодний пост:
«Эй, ChatGPT. А ты можешь реализовать большую языковую модель на SQL?»
«Нет, SQL не подходит для реализации больших языковых моделей. Язык SQL предназначен для выполнения запросов к данным, хранящимся в РСУБД и для управления этими запросами. Для реализации большой языковой модели требуются сложные алгоритмы, обширные датасеты, а зачастую — и фреймворки для глубокого обучения. SQL всеми этими возможностями не обладает.»
Что ж, лишний раз убеждаешься, что, если хочешь что‑то сделать хорошо – сделай это сам.
Давайте же воодушевимся этим оптимистическим планом и реализуем большую языковую модель на языке SQL.
11 января 2024 года, выпущен Firebird 5.0 — восьмой основной выпуск СУБД Firebird, разработка которого началась в мае 2021 года. В Firebird 5.0 команда разработчиков сосредоточила свои усилия на повышении производительности СУБД: параллельное выполнение backup, restore, sweep, создания и перестроение индексов, улучшение масштабирования в многопользовательской среде, ускорение повторной подготовки запросов (кеш компилированных запросов), улучшение оптимизатора, улучшение алгоритма сжатия записей. Кроме того, появились и новые возможности в языке SQL и PSQL.
В версии Firebird 5 также появился встроенный инструмент для профилирования SQL и PSQL, что существенно облегчит поиск узких мест и отладку сложных SQL.
Базы данных, созданные в Firebird 5.0, имеют версию ODS (On-Disk Structure) 13.1. Firebird 5.0 позволяет работать и с базами данных с ODS 13.0 (созданные в Firebird 4.0), но при этом некоторые возможности будут недоступны.
Для того чтобы переход на Firebird 5.0 был проще, в утилиту командной строки gfix был добавлен новый переключатель -upgrade, который позволяет обновлять минорную версию ODS без длительных операций backup и restore.
Также хочется отметить тот факт, что новый релиз Firebird доступен сразу на 11 платформах, включая ARM для Linux и Android. Скачать готовые сборки и дистрибутивы можно по адресу https://firebirdsql.org/en/firebird-5-0/.
Далее я перечислю ключевые улучшения, сделанные в Firebird 5.0, и их краткое описание. Подробное описание всех изменений можно прочитать в Firebird 5.0 Release Notes. Кроме того подробный разбор новых функций Firebird 5.0 вы можете найти в серии статей на ресурсе ibase.ru.

Продолжаю публикацию расширенных транскриптов лекционного курса "PostgreSQL для начинающих", подготовленного мной в рамках "Школы backend-разработчика" в "Тензоре".
В этой лекции углубимся в расширенные возможности команды SELECT : как можно "сложить" и "вычесть" выборки (UNION/INTERSECT/EXCEPT), или запомнить и использовать в рекурсивных запросах (CTE), что дают оконные функции (WINDOW) и соединения (JOIN).
Как обычно, для предпочитающих смотреть и слушать, а не читать - доступна видеозапись и слайды.

Всем привет!
Примерно год назад мне захотелось проанализировать доходы и расходы со всех своих банковских карт, количество которых начало разрастаться. После ресерча существующих приложений я поняла, что они либо платные, либо нужно ручками вбивать всю информацию. Плюс вопрос сохранения конфиденциальности данных. В этой статье я расскажу про свой мини-проект, как он мне помогает следить за личными финансами и как вы можете покрутить его сами.
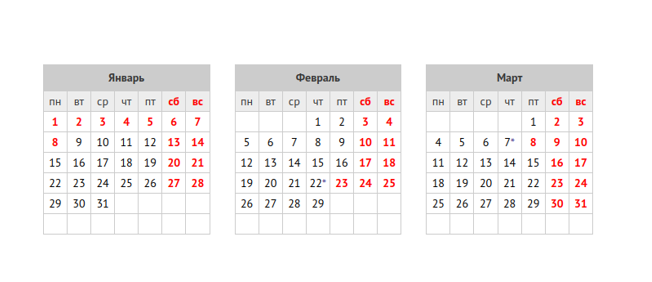
Новый Год уже совсем на носу, а значит нужен свежий производственный календарь в базе данных PostgreSQL. Но как совершенно обленившийся IT-шник, заводить его руками не хочется. Хочется, чтобы вызовом одной функции он сразу появился. Ну а уж из этой функции можно его сохранить в табличку и спокойно использовать до следующего Нового Года. А тогда опять просто вызвать вызвать функцию и с чистой совестью отрапортовать о выполненной работе. Цель статьи - показать возможности COPY ... FROM PROGRAM и простейшие приемы парсинга XML в PostgreSQL.
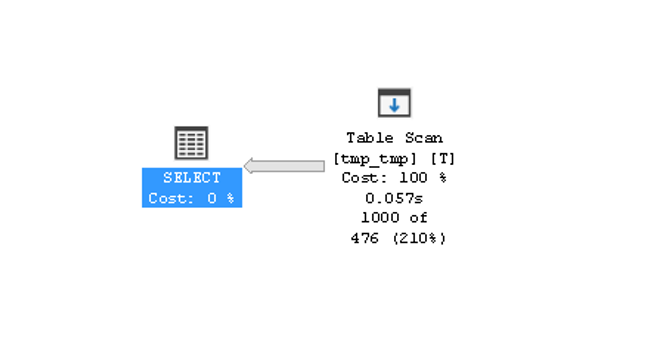
Несмотря на избитость темы и многочисленные рекомендации избегать OR в выражениях WHERE/ON SQL запросов, жизнь вносит свои коррективы. Иногда сама постановка задачи подразумевает необходимость использовать OR. Я не собираюсь здесь рассматривать простые случаи, а сразу возьму быка за рога и рассмотрю случай, когда OR должно привести к двум разным выборкам по разным индексам одной и той же таблицы.

Любой более или менее серьезный продакшен, работающий с базой данных, подразумевает процесс миграции - обновление структуры базы данных от одной версии до другой (обычно более новой) [источник].
Миграции в БД можно делать вручную или использовать для этого специальные утилиты (фреймворки). В данной статье речь идет об утилите goose. Это инструмент миграции схемы, который обеспечивает управление миграциями схемы в проекте. Начиная с версии v3.16.0 goose поддерживает YDB - распределенную open-source СУБД. В данной статье мы будем разбирать кейс применения миграций конкретно в YDB.

В динамичной среде управления базами данных постоянно присутствует необходимость фиксировать и понимать изменения данных с течением времени. Начните управлять временем с использованием Postgres-триггеров, которые открывают легкий путь к сложному решению — историческим таблицам.
Представьте себе мир, в котором каждое изменение вашей базы данных оставляет след, фиксирующую эволюцию ваших данных. В этом заключаются перспективы исторических таблиц — концепции, которая выходит за рамки традиционных ограничений проектирования баз данных. В этом исследовании мы углубимся во временное измерение PostgreSQL, раскроем возможности Postgres-триггеров и их ключевую роль в создании и обслуживании исторических таблиц.
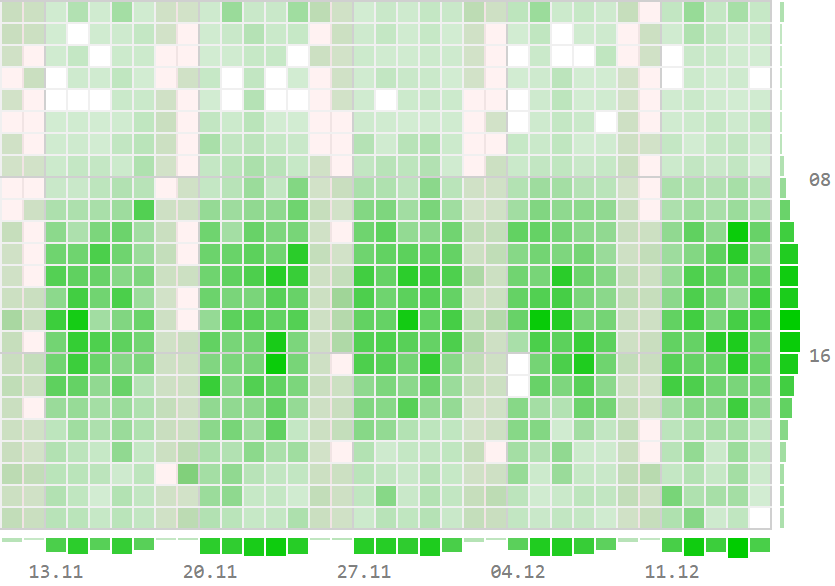
Немного отвлечемся от простых SELECT и посмотрим на реальной бизнес-задаче построения различных "тепловых карт" и "шахматок", как знание возможностей SQL может облегчить жизнь и разработчику, и его базе.

Продолжаю публикацию расширенных транскриптов лекционного курса "PostgreSQL для начинающих", подготовленного мной в рамках "Школы backend-разработчика" в "Тензоре".
Сегодня поговорим о самых простых, но важных, возможностях команды SELECT, наиболее часто используемой при работе с базами данных - формировании выборок (VALUES), их ограничении (LIMIT/OFFSET/FETCH), фильтрации (WHERE/HAVING), сортировке (ORDER BY), уникализации (DISTINCT) и группировке (GROUP BY).
Как обычно, для предпочитающих смотреть и слушать, а не читать - доступна видеозапись и слайды.
