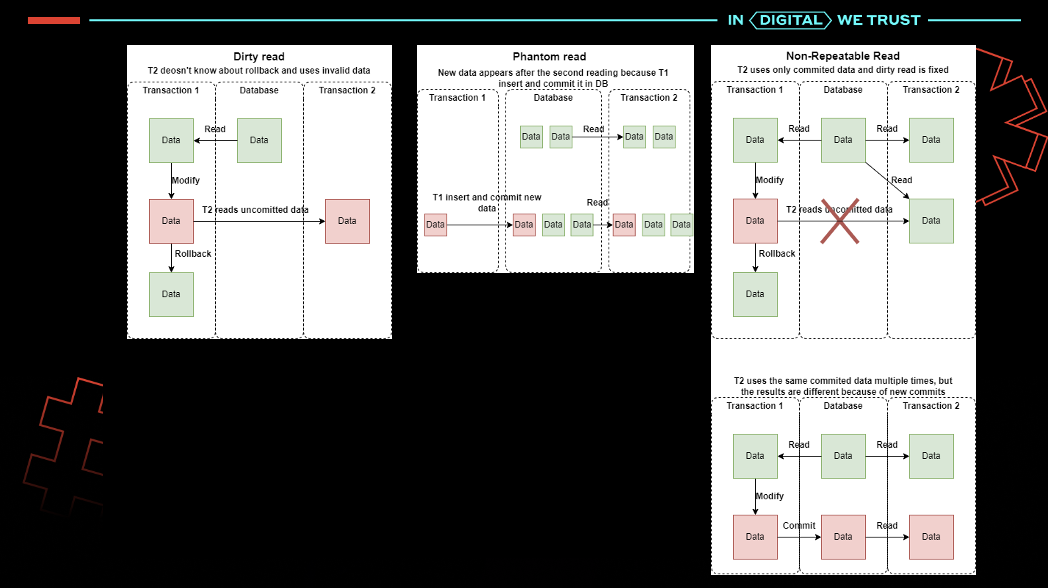
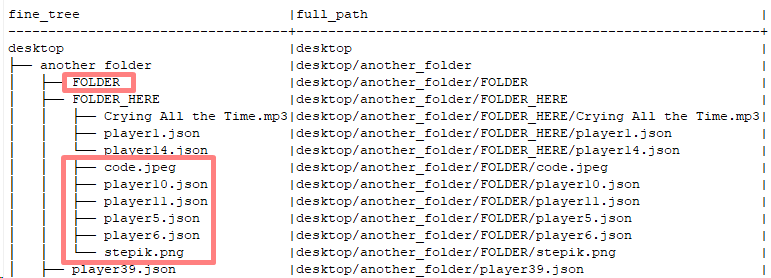
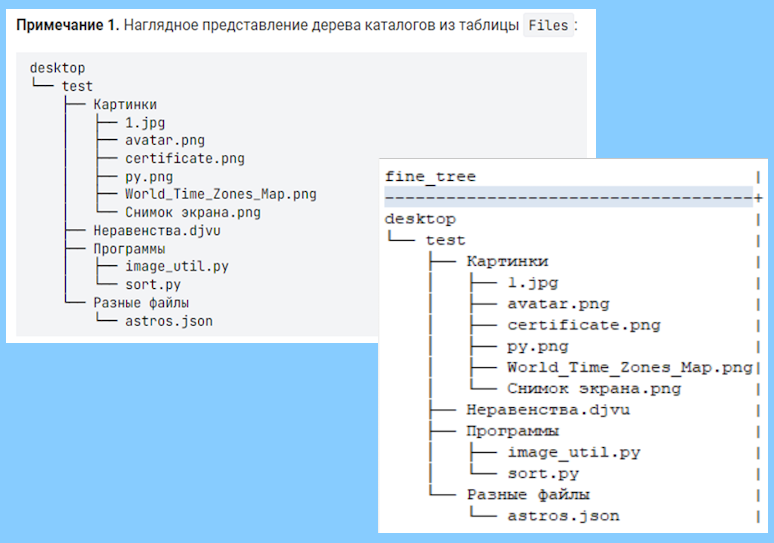
Хотя я живу в Копенгагене и в основном перемещаюсь по городу на велосипеде, у меня есть и машина, чтобы добираться до других частей страны. В Дании автомобили через каждые два года проходят обязательный официальный осмотр; я проходил его за свою жизнь несколько раз. Несколько лет назад механик, выполнявший осмотр, сообщил мне о том, что у машины неправильный номер кузова.
Я немного занервничал, потому что покупал машину с рук, и внезапно задался вопросом, действительно ли всё так, как я думал. Неужели я непреднамеренно купил краденную машину?
Но механик просто подошёл к своему компьютеру, чтобы исправить ошибку. И тогда у меня возникло совершенно другое опасение. Когда программируешь больше десятка лет, то учишься предвидеть разные типичные режимы отказа. Так как номер кузова — очевидный кандидат на должность естественного ключа, я заранее предвидел, что изменение этого номера будет или невозможно, или приведёт ко всевозможным каскадным эффектам, и в конечном итоге к уничтожению официальных записей, больше не признающих, что машина принадлежит мне.