

Сразу покажу, о чем идет речь, чтобы вы решили, нужно вам это или нет. На текст процедуры мы отображаем данные о числе выполнений, cpu, duration, о числе чтений и записей и числе обработанных записей.
Сразу покажу, о чем идет речь, чтобы вы решили, нужно вам это или нет. На текст процедуры мы отображаем данные о числе выполнений, cpu, duration, о числе чтений и записей и числе обработанных записей.

Привет, Хабр!
Сегодня я хочу поговорить о том, без чего не обходится практически ни один серьёзный проект с большими данными (да и с не слишком большими тоже) — о промежуточных витринах (или более привычно – staging, core, data mart).
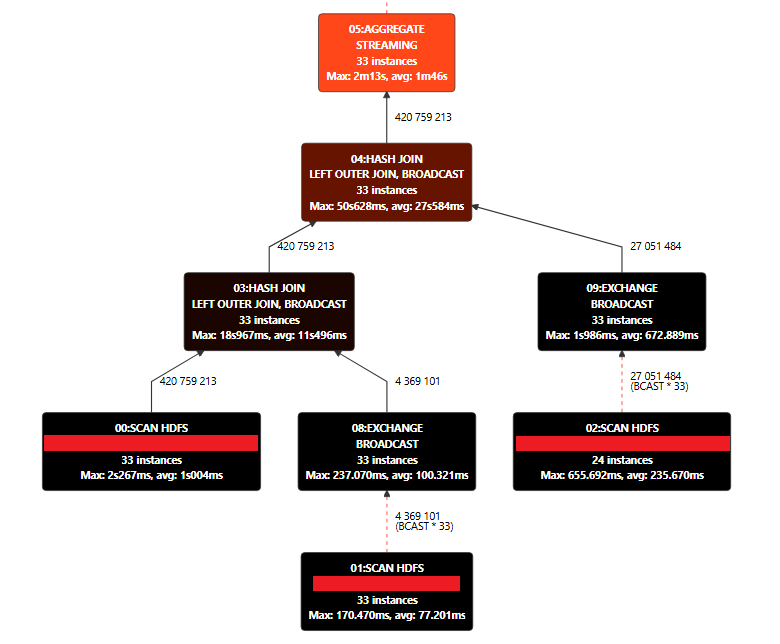
В 2022 году я присоединился к команде Газпромбанка в должности дата-инженера. В мои обязанности входила поддержка витрин данных для машинного обучения. Главной проблемой, с которой мне пришлось столкнуться, оказалось непомерно долгое время обработки данных при использовании устаревших скриптов. Например, расчет среза одной из витрин занимал более суток! Причина крылась в неоптимизированных скриптах, которые изначально разрабатывались для гораздо меньших объемов данных. Со временем объем обрабатываемой информации значительно увеличился, что закономерно привело к драматическому ухудшению производительности. В этой статье поделюсь своим опытом решения проблемы и расскажу о подходах, которые помогли сократить время выполнения с суток до нескольких часов.

Данная статья является продолжением этой статьи: Инструкция: как перейти в сферу it, но с перечнем курсов, которые я закончил (это тоже часто спрашивают). Можете считать это рекламой пройденных мною курсов, а можете и не считать.

Если столкнулись с кредитом и задавали вопросы как считается график платежей по нему (не в общем и целом, а почему конкретно тут такая циферка, а не другая), то, надеюсь, большую их часть сможете закрыть, после ознакомления.
Плюс в статье делюсь своей технической реализацией в ознакомительных целях.

Привет, Хабр! Меня зовут Кирилл Салихов, и я занимаюсь разработкой бизнес-приложений на платформе .NET в компании КРОК. При оптимизации процессов развертывания приложений возник вопрос о том, как эффективно хранить SQL-код, предназначенный для применения к базе данных, чтобы избежать необходимости в ручном труде и перемещении файлов.
В короткой статье дам пошаговую инструкцию автоматического применения миграций к базе данных и управлению представлениями и процедурами, без всяких сиай/сиди…

Во времена пика интереса к NoSQL базам данных простоватые K-V хранилища были несколько обойдены вниманием - отчасти это понятно, вещь не очень "инновационная", можно даже сказать старинная. В то же время своя "ниша" у них находится до сих пор (не считая того что они используются в более сложных БД в качестве индексов).
В то же время в обычной SQL-ной базе проекта порой "не хватает" такого общего K-V хранилища для разнородных (семантически) записей. В своих проектах я такую обычно завожу. Среди коллег этот подход порой вызывает негатив :)
Поясню ситуацию на примерах и попробую выписать "за и против" - а уважаемых знатоков приглашаю поделиться мнениями - особенно если у кого-то в схеме похожие таблички встречаются. Не для поиска несуществующей "истины", а ради дележа опытом и идеями.
На виртуалке кончилось место ? Не беда, у нас виртуалка - увеличим диск. Не хотим размещать файлы на основном диске ? Не беда у нас виртуалка - добавим новый диск.
Всё бы ни чего, но виртуалка сама железо не настроит, в том смысле что конечно виртуальная машина предоставляет доступ к железу, но ресурсы этого железа программам предоставляет не виртуалка, ресурсы предоставляет операционная система. И пока вы не настроите операционную систему, ваши программы не получат ресурсы этого железа (в нашем случае свободное место на диске для размещения файлов)
Эта инструкция будет о том как настроить операционную систему Ubunta, для управления новым железом (в нашем случае дисковым пространством).
Будет три части:
Как расширить раздел (увеличить диск)
Как добавить новый диск
Как создать базу данных на новом диске

Привет, Хабр и его читатели!
Меня зовут Дарья Четыркина, я программист SQL в IT-компании «Автомакон». Предлагаю обсудить проблему, которая может «съедать» производительность вашего SQL Server — фрагментация индексов, в конце статьи будут решения этой ситуации. Если вам важно, чтобы SQL Server всегда работал на полную мощность, эта статья — для вас.
Когда дело касается SQL Server, индексы — это ваши верные помощники: они организуют данные так, что сервер может находить нужные записи быстрее, чем обычный поиск. При этом со временем индексы начинают «разваливаться» и создают массу проблем. Фрагментация индексов — невидимый враг, который замедляет запросы, увеличивает нагрузку на сервер и лишает ваш SQL Server той оптимальной скорости, ради которой и создаются индексы. Разберемся, почему возникает фрагментация индекса, как она вредит производительности и что можно с этим сделать.

Привет, Хабр! Одной из важных задач в аналитических запросах является расчет долей, который позволяет узнать, какая часть записей из общего количества по всей таблице соответствует какому-либо критерию. Также нередко полезными оказываются коэффициенты проникновения (в общем-то тоже являющиеся долями). Они позволяют оценить продажи, найти взаимосвязи признаков и сделать много еще чего полезного. Чтобы проводить такого рода расчеты идеально подходит язык DAX. Если Вам интересно, насколько это удобно и как именно сделать это в DAX — добро пожаловать под кат :)
Здравствуйте, дорогие друзья! Сегодня мы окунёмся в мир SQL запросов и рассмотрим различные подходы, которые разработчики используют для работы с данными в БД. В современном мире разработки, где информация становитесь все больше и больше, и скорость получения данных имеет большое значение, умение эффективно извлекать и обрабатывать данные становится неотъемлемой частью работы многих SQL специалистов (особенно тех кто работает с нагруженными системами и DWH). Мы поговорим о таких методах, как Common Table Expressions (CTE), подзапросы, представления и материализованные представления.

Enums VS Tables для создания типов моделей...
Зачем использовать вообще одно из этих решений?
Существуют модели, у которых необходимо выделить разновидности и сделать это именно с помощью типов, а не категорий... Разберёмся...

Существуют базы данных различного вида, и для колоночных баз данных, таких как, например, ClickHouse, характерны особые инструменты для вычислений аггрегированных значений.
Из документации ClickHouse не всегда легко сразу понять ценность функций для имплементации бизнес-логики, в частности, ценность функции runningAccumulate. Например, несмотря на богатые возможности runningAccumulate, неотформатированный код и имена вида k и sum_k из документации могут немного ввести в заблуждение.
Если Вам интересно рассмотреть state функции ClickHouse на паре примеров с более понятной логикой, то добро пожаловать :)

В статье рассмотрены примеры использования длинных (sapscript) текстов для построения шаблонов с использованием вложенности шаблонов, переменных и условных конструкций. Статья будет полезна для разработок рассылок на основе SAP NetWeaver, формирование печатных форм, рекомендательной/пояснительной документации.

Когда вы анализируете данные, базовых функций SQL часто недостаточно, особенно когда дело касается сложных запросов и обработки больших объемов информации. В таких случаях на помощь приходят функции для работы с массивами в ClickHouse. Однако, многие пользователи не знают о их существовании или не используют их в полной мере.
Эта статья — небольшой гид по функциям работы с массивами в ClickHouse. Мы рассмотрим самые полезные и мощные инструменты, такие как arrayJoin, arrayMap, arrayFilter, и другие. Разберём, как их использовать для решения повседневных задач аналитики данных, на конкретных примерах.
Почему это важно? Потому что умение грамотно работать с массивами позволяет сократить и упростить код, делая его более читаемым и поддерживаемым. Это ключевой навык для тех, кто хочет писать оптимальные запросы.
Вам могут пригодиться array функции, когда стандартные SQL-запросы становятся сложными и трудными для понимания. Например, вместо использования множества подзапросов и объединений для отслеживания последовательности действий пользователя, вы можете использовать функции работы с массивами. Кроме того, использование функций позволяет фильтровать элементы внутри массива, избавляя от необходимости написания сложных условий в подзапросах. Функции работы с массивами в ClickHouse помогут сократить количество кода и упростить запросы, заменяя многократные подзапросы на более элегантные и читабельные решения.

Недавно возникла потребность переместить данные из Bubble в Heroku, так как Bubble начал требовать много денег за хранение и доступ к большому кол-ву данных, поэтому было решено переместить данные проекта в Heroku.

Привет! В этой статье я расскажу, как создать телеграм-бота на aiogram 3.7 с личным профилем, админ-панелью и реферальной системой. Мы пройдем через регистрацию пользователей, работу с базой данных PostgreSQL и многое другое. Жмите на "читать далее"!

В 2024 году вопросы и тестовые задания на собеседованиях не потеряли своей актуальности и продолжают вызывать огромный интерес у соискателей. Если вы сейчас погружены в процесс прохождения интервью, то наверняка сталкиваетесь с множеством непростых, но захватывающих задач.
Давайте вместе рассмотрим некоторые из новых вопросов и задач, которые реально задаются на собеседованиях в различных командах. Эти примеры основаны на моем собственном опыте и актуальны на сегодняшний день. Новые вопросы и задачи будут публиковаться по мере их поступления и прохождения собеседований.

Различные СУБД предлагают широкий набор разновидностей операторов JOIN для таблиц. Если Вам встретилась проблема с производительностью CROSS JOIN, - например, декартово произведение таблицы с миллионом записей самой на себя, - добро пожаловать, в этой статье перечислены простейшие способы избавиться от CROSS JOIN.
Конечно, можно пересмотреть и упростить саму бизнес-логику или способы расчетов, в данной статье рассмотрены некоторые базовые случаи, про которые не стоит забывать и имеет смысл проверять первыми. Надеюсь, они окажутся релевантными или смогут помочь найти другие SQL оптимизации.
Примеры в статье рассматриваются на основе CROSS JOIN из ClickHouse. Текущая версия ClickHouse не оптимизирует CROSS JOIN автоматически. Также стоит отметить, что поскольку часто SQL запросы не пишутся вручную, а, например, собираются по частям программно, то перечисленные далее случаи вполне реальны.
Доброго времени суток.
Ты ж у нас один программист !!!
Небольшая вводная. Я для друзей, по их запросам, выгружаю данные из MS SQL Server'а. Друзья дают исходные данные, для которых надо сделать выгрузку в файлах .csv. Исходных данных (ИД) может быть от 1 до ... строк. Я загружал данные в sql таблицу с помощью задачи или Task в английской версии в SQL Server Management Studio (SSMS). Исторически сложилось, что все sql файлы со скриптами хранятся на моем ПК. Я файлы открывал в SSMS и запускал на выполнение. Результаты записывал в файл и отправлял сообщение, что обработка выполнена. Друзья забирали файлы с результатами.
Но в один творческий день пришла идея автоматизировать этот процесс, чтобы Друзья все делали сами, с минимальным моим участием.