На днях из Америки приехало два любопытных устройства: микрокомпьютер electric imp и оптический датчик уровня углекислого газа в воздухе K30. Каждый из них любопытен по-своему, расскажу немного о каждом из них и о их соединении.

Импы — это вид бесенят в немецком фольклоре. А также сокращение от Interface Message Processor, одного из проектов-предшественников Интернета. Создатели системы признают обоих предшественников. В жизни эта штука оказалась довольно покладистой, хорошо документированной платформой для разработки embedded приложений.
Статью-обзор интернет анонсов можно почитать в статье на хабре, я постараюсь рассказать о конкретике и тонкостях, которые выяснились в процессе работы.
Electric imp
Импы — это вид бесенят в немецком фольклоре. А также сокращение от Interface Message Processor, одного из проектов-предшественников Интернета. Создатели системы признают обоих предшественников. В жизни эта штука оказалась довольно покладистой, хорошо документированной платформой для разработки embedded приложений.
Статью-обзор интернет анонсов можно почитать в статье на хабре, я постараюсь рассказать о конкретике и тонкостях, которые выяснились в процессе работы.
 Многие из вас знакомы с анонсом Electric Imp, который не так давно
Многие из вас знакомы с анонсом Electric Imp, который не так давно 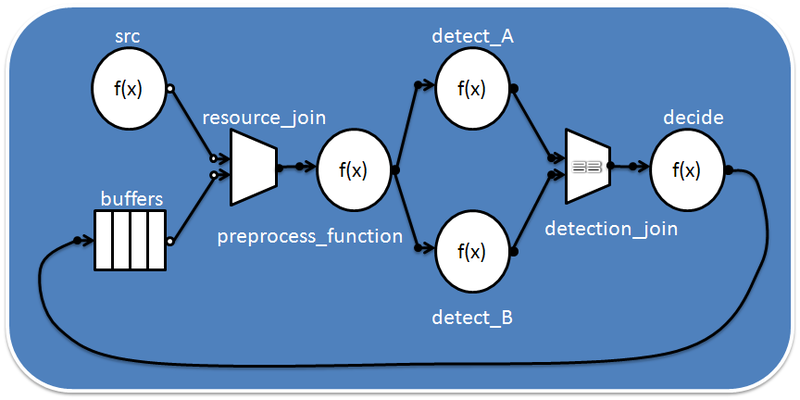

 При разработке приложений с модульной структурой на JavaScript возникает две проблемы:
При разработке приложений с модульной структурой на JavaScript возникает две проблемы: