

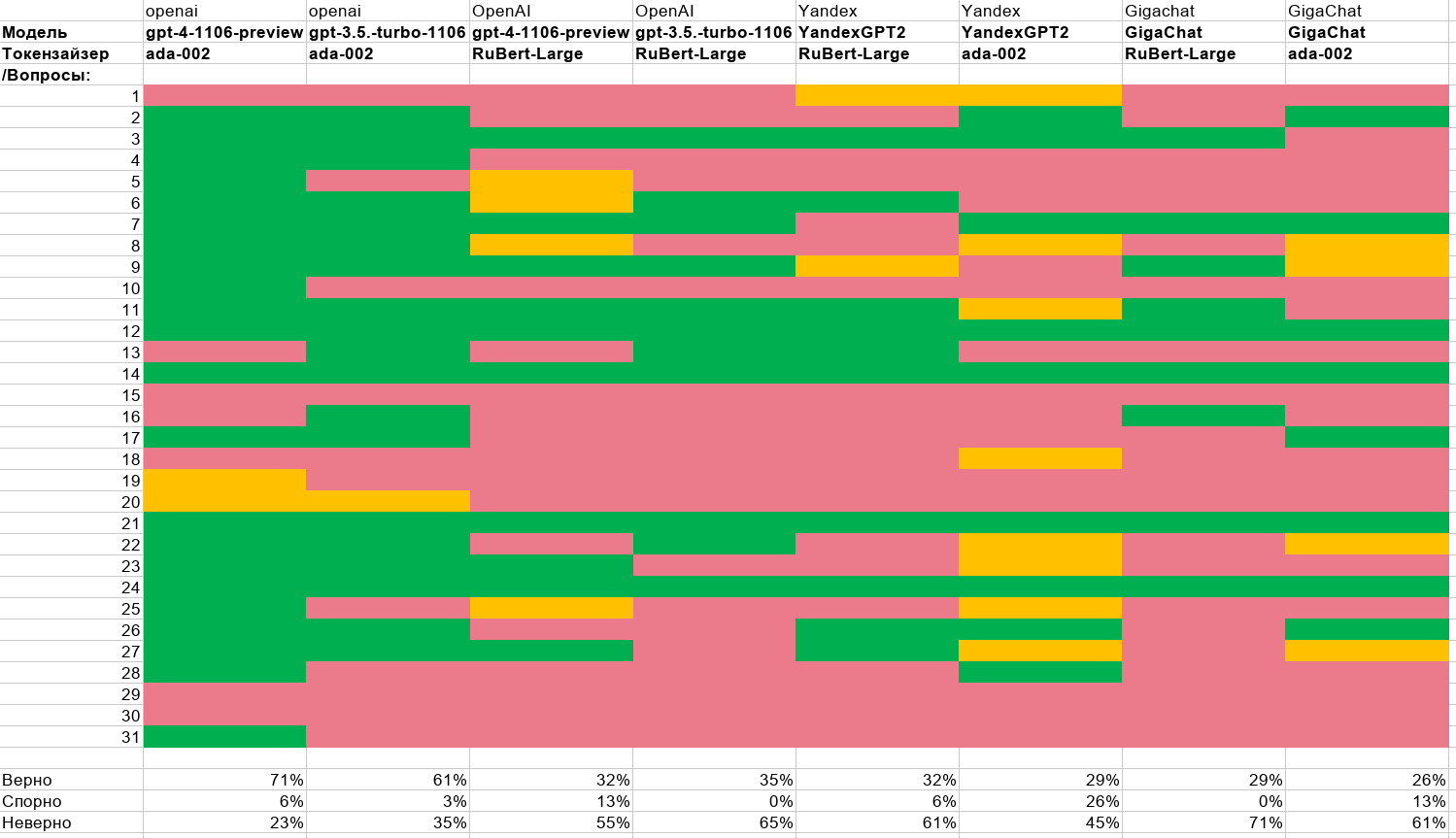
Привет, Хабр! Сегодня мы поговорим о том, почему BI-платформам нужен движок, какие сложности создает ClickHouse для аналитиков, когда речь действительно заходит о больших данных, зачем нужно оптимизировать SQL и о многих других вещах, которые часто остаются «за горизонтом» в дискуссиях о BI и хранении данных. Говоря другими словами, я хочу рассказать о том, как мы разрабатывали ДанКо — новый движок, который лежит сегодня в основе Visiology 3, а главное — каким образом ДанКо позволяет достичь высокой производительности в аналитических задачах (в некоторых случаях показывая ускорение вплоть до х100)! Эта статья будет полезна тем, кто еще не сталкивался с задачей организации хранения аналитических данных компании, а также интересна тем, кто как раз, наоборот, уже делал это.








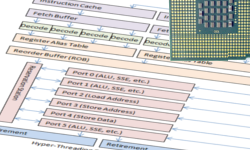 Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.
Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.