Всем привет! На связи команда ad-hoc аналитики X5 Tech.
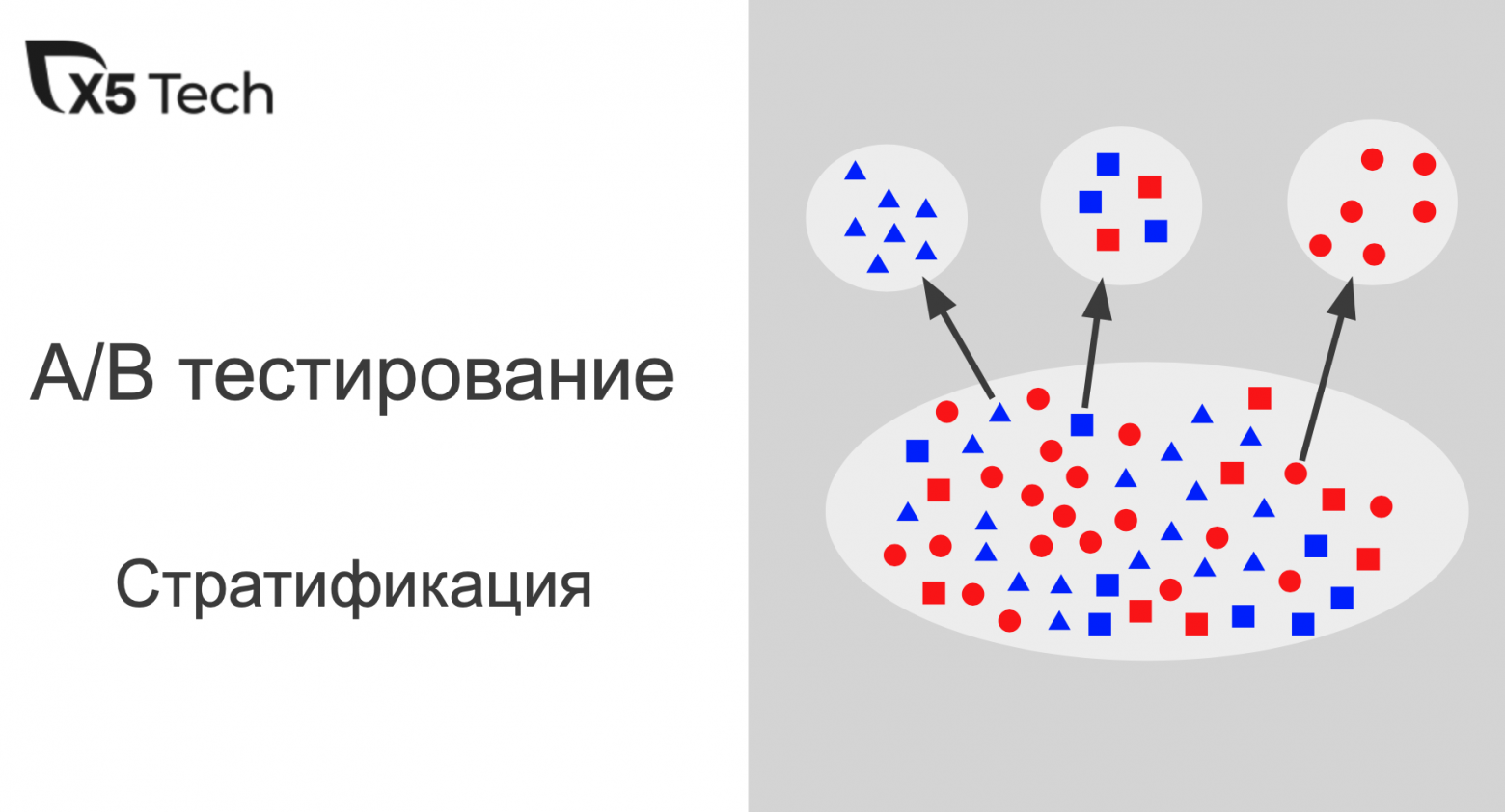
Сегодня подробно обсудим применение стратификации для повышения чувствительности оценки AB экспериментов.

Пользователь
Всем привет! На связи команда ad-hoc аналитики X5 Tech.
Сегодня подробно обсудим применение стратификации для повышения чувствительности оценки AB экспериментов.

Всем привет!
Иногда кажется, что для решения проблемы недостаточно простого выполнения расчётов в Spark и хочется более эффективно использовать доступные ресурсы. Меня зовут Илья Панов, я инженер данных в продукте CVM5 (Customer Value Management торговой сети Пятёрочка) группы X5, и хочу поделиться некоторыми подходами параллельных вычислений в Apache Spark.

Окончательно разбираемся с выводами о том, какая криптовалюта наименее подвержена рискам внезапного и резкого обесценения; и в какой крипте риск санкционных заморозок минимален.

В попытке избежать санкций Запада и контрсанкций со стороны РФ, многие россияне спешно переводят сбережения в криптовалюту. В этой статье я разбираюсь в финансовой надежности крупнейшего и старейшего стейблкоина USDT (спойлер: к ней есть серьезные вопросы).




*фарм — (от англ. farming) — долгое и занудное повторение определенных игровых действий с определенной целью (получение опыта, добыча ресурсов и др.).
Недавно (1 октября) стартовала новая сессия прекрасного курса по DS/ML (очень рекомендую в качестве начального курса всем, кто хочет, как это теперь называется, "войти" в DS). И, как обычно, после окончания любого курса у выпускников возникает вопрос — а где теперь получить практический опыт, чтобы закрепить пока еще сырые теоретические знания. Если вы зададите этот вопрос на любом профильном форуме, то ответ, скорее всего, будет один — иди решай Kaggle. Kaggle — это да, но с чего начать и как наиболее эффективно использовать эту платформу для прокачки практических навыков? В данной статье автор постарается на своем опыте дать ответы на эти вопросы, а также описать расположение основных грабель на поле соревновательного DS, чтобы ускорить процесс прокачки и получать от этого фан.


Я с удивлением обнаружил, что многие разработчики, даже давно использующие postgresql, не понимают оконные функции, считая их какой-то особой магией для избранных. Ну или в лучшем случае «копипастят» со StackOverflow выражения типа «row_number() OVER ()», не вдаваясь в детали. А ведь оконные функции — полезнейший функционал PostgreSQL.
Попробую по-простому объяснить, как можно их использовать.
Bash-скрипты: начало
Bash-скрипты, часть 2: циклы
Bash-скрипты, часть 3: параметры и ключи командной строки
Bash-скрипты, часть 4: ввод и вывод
Bash-скрипты, часть 5: сигналы, фоновые задачи, управление сценариями
Bash-скрипты, часть 6: функции и разработка библиотек
Bash-скрипты, часть 7: sed и обработка текстов
Bash-скрипты, часть 8: язык обработки данных awk
Bash-скрипты, часть 9: регулярные выражения
Bash-скрипты, часть 10: практические примеры
Bash-скрипты, часть 11: expect и автоматизация интерактивных утилит





“Если в ваших руках молоток, все вокруг кажется гвоздями”
Как практикующие дата саентисты мы занимаемся анализом данных, их сбором, очисткой, обогащением, строим и обучаем модели окружающего мира, основываясь на данных, находим внутренние взаимосвязи и противоречия между данными, порою даже там, где их нет. Безусловно такое погружение не могло не сказаться на нашем видении и понимании мира. Профессиональная деформация присутствует в нашей профессии точно также, как и в любой другой, но что именно она нам приносит и как влияет на нашу жизнь?
В 2020 году библиотека Natasha значительно обновилась, на Хабре опубликована статья про актуальную версию. Чтобы использовать инструменты, описанные в этом тексте, установите старую версию библиотекиpip install natasha<1 yargy<0.13.
Раздел про Yargy-парсер актуален и сейчас.

Natasha — это аналог Томита-парсера для Python (Yargy-парсер) плюс набор готовых правил для извлечения имён, адресов, дат, сумм денег и других сущностей.В статье показано, как использовать готовые правила из Natasha и, самое главное, как добавлять свои с помощью Yargy-парсера.
Привет, Хабр!
Три года назад на сайте Леонида Жукова я ткнул ссылку на курс Юре Лесковека cs224w Analysis of Networks и теперь мы будем его проходить вместе со всеми желающими в нашем уютном чате в канале #class_cs224w. Cразу же после разминки с открытым курсом машинного обучения, который начнётся через несколько дней.

Вопрос: Что там начитывают?
Ответ: Современную математику. Покажем на примере улучшения процесса IT-рекрутинга.
Под катом читателя ждёт история о том, как руководителя проектов дискретная математика до нейросетей довела, почему внедряющим ERP и управляющим продуктами стоит почитывать журнал Биоинформатика, как появилась и решается задача рекомендации связей, кому нужны графовые эмбеддинги и откуда взялись, а также мнение о том, как перестать бояться вопросов про деревья на собеседованиях, и чего всё это может стоить. Погнали!
На просторах интернета имеется множество туториалов объясняющих принцип работы LDA(Latent Dirichlet Allocation — Латентное размещение Дирихле) и то, как применять его на практике. Примеры обучения LDA часто демонстрируются на "образцовых" датасетах, например "20 newsgroups dataset", который есть в sklearn.
Особенностью обучения на примере "образцовых" датасетов является то, что данные там всегда в порядке и удобно сложены в одном месте. При обучении продакшн моделей, на данных, полученных прямиком из реальных источников все обычно наоборот:
Исторически, я стараюсь учиться на примерах, максимально приближенных к реалиям продакшн-действительности потому, что именно таким образом можно наиболее полно прочувстовать проблемные места конкретного типа задач. Так было и с LDA и в этой статье я хочу поделиться своим опытом — как запускать LDA с нуля, на совершенно сырых данных. Некоторая часть статьи будет посвящена получению этих самых данных, для того, чтобы пример обрел вид полноценного 'инженерного кейса'.

При написании статьи о разработке детектора аномалий я реализовывал один из алгоритмов, который называется "Инкрементальный растущий нейронный газ".
В советской литературе российском сегменте Интернета эта тема освещена достаточно слабо, и нашлась только одна статья, да и то с прикладным применением данного алгоритма.
Итак, что же такое — алгоритм инкрементального растущего нейронного газа?
{kind=link}