Эта публикация написана по материалам выступления AlexSerbul на осенней конференции BigData Conference.
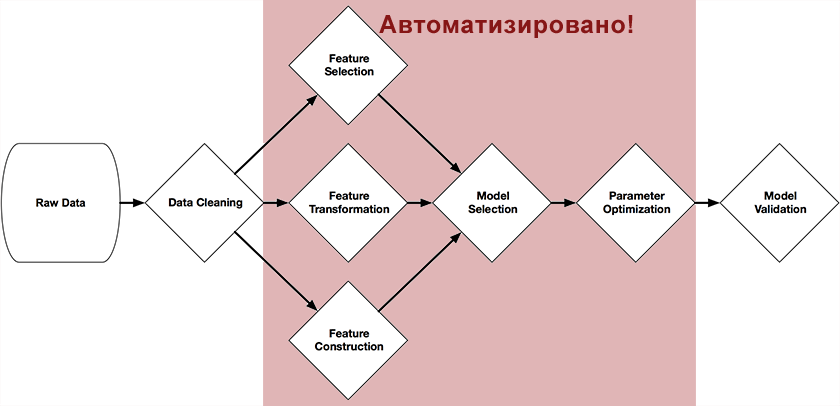
Большие данные — тема модная и востребованная. Но многих по-прежнему отпугивает избыток теоретических рассуждений и некоторый недостаток практических рекомендаций. В этом посте я хочу отчасти заполнить этот пробел и рассказать об использовании параллельных алгоритмов для обработки больших данных на примере кластеризации товарного каталога из 10 млн позиций.
Большие данные — тема модная и востребованная. Но многих по-прежнему отпугивает избыток теоретических рассуждений и некоторый недостаток практических рекомендаций. В этом посте я хочу отчасти заполнить этот пробел и рассказать об использовании параллельных алгоритмов для обработки больших данных на примере кластеризации товарного каталога из 10 млн позиций.








 В то время как за окном температура на пути к очередным рекордам, интересно посмотреть, а какие вообще бывали температуры в произвольный интервал времени, за любые года за последние несколько десятилетий в 30 000 точках по всему миру. А может не прогадать с днями отпуска, и взять их в те дни, когда есть какое-то «статистическое преимущество» в выбранном местоположении по теплой погоде, а может быть по холодной, оценив его визуально на любой из трех типов диаграмм. Ну или можно просто повращать глобус, визуально оценить разнообразие температур и «как прекрасен этот мир».
В то время как за окном температура на пути к очередным рекордам, интересно посмотреть, а какие вообще бывали температуры в произвольный интервал времени, за любые года за последние несколько десятилетий в 30 000 точках по всему миру. А может не прогадать с днями отпуска, и взять их в те дни, когда есть какое-то «статистическое преимущество» в выбранном местоположении по теплой погоде, а может быть по холодной, оценив его визуально на любой из трех типов диаграмм. Ну или можно просто повращать глобус, визуально оценить разнообразие температур и «как прекрасен этот мир».