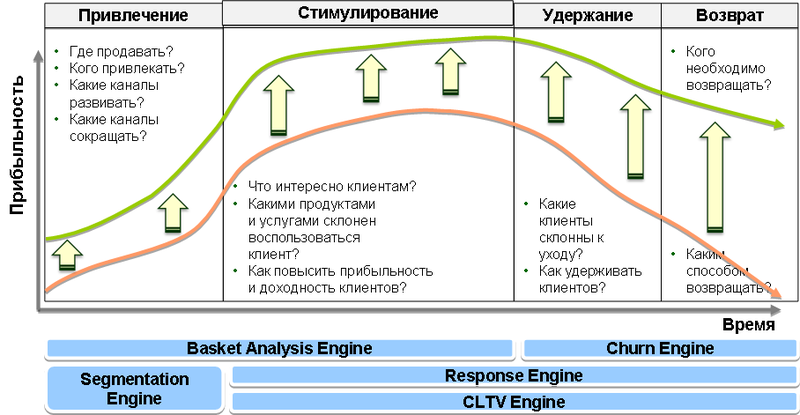
Введение
Добрый день, уважаемые читатели.
После написания предыдущего поста про анализ временных рядов на Python, я решил исправить замечания, которые были указаны в комментариях, но при их исправлении я столкнулся с рядом проблем, например при построении сезонной модели ARIMA, т.к. подобной функции а пакете statsmodels я не нашел. В итоге я решил использовать для этого функции из R, а поиски привели меня к библиотеке rpy2 которая позволяетиспользовать функции из библиотек упомянутого языка.
У многих может возникнуть вопрос «зачем это нужно?», ведь проще просто взять R и выполнить всю работу в нем. Я полность согласен с этим утверждением, но как мне кажется, если данные требуют предварительной обработки, то ее проще произвести на Python, а возможности R использовать при необходимости именно для анализа.
Кроме этого, будет показано как интегрировать результаты выдачи работы функции R в IPython Notebook.






 В
В  Во всех онлайн сервисах и играх самая большая доля аудитории уходит прямо на старте – в первые же минуты и часы знакомства с продуктом. Этой теме уже посвящены сотни книг и статей с самыми различными гипотезами успеха и причин лояльности аудитории – уникальность, простота, юзабилити, бесплатность, обучение или инструкция, эмоциональность, и еще множество факторов считаются крайне важными.
Во всех онлайн сервисах и играх самая большая доля аудитории уходит прямо на старте – в первые же минуты и часы знакомства с продуктом. Этой теме уже посвящены сотни книг и статей с самыми различными гипотезами успеха и причин лояльности аудитории – уникальность, простота, юзабилити, бесплатность, обучение или инструкция, эмоциональность, и еще множество факторов считаются крайне важными.