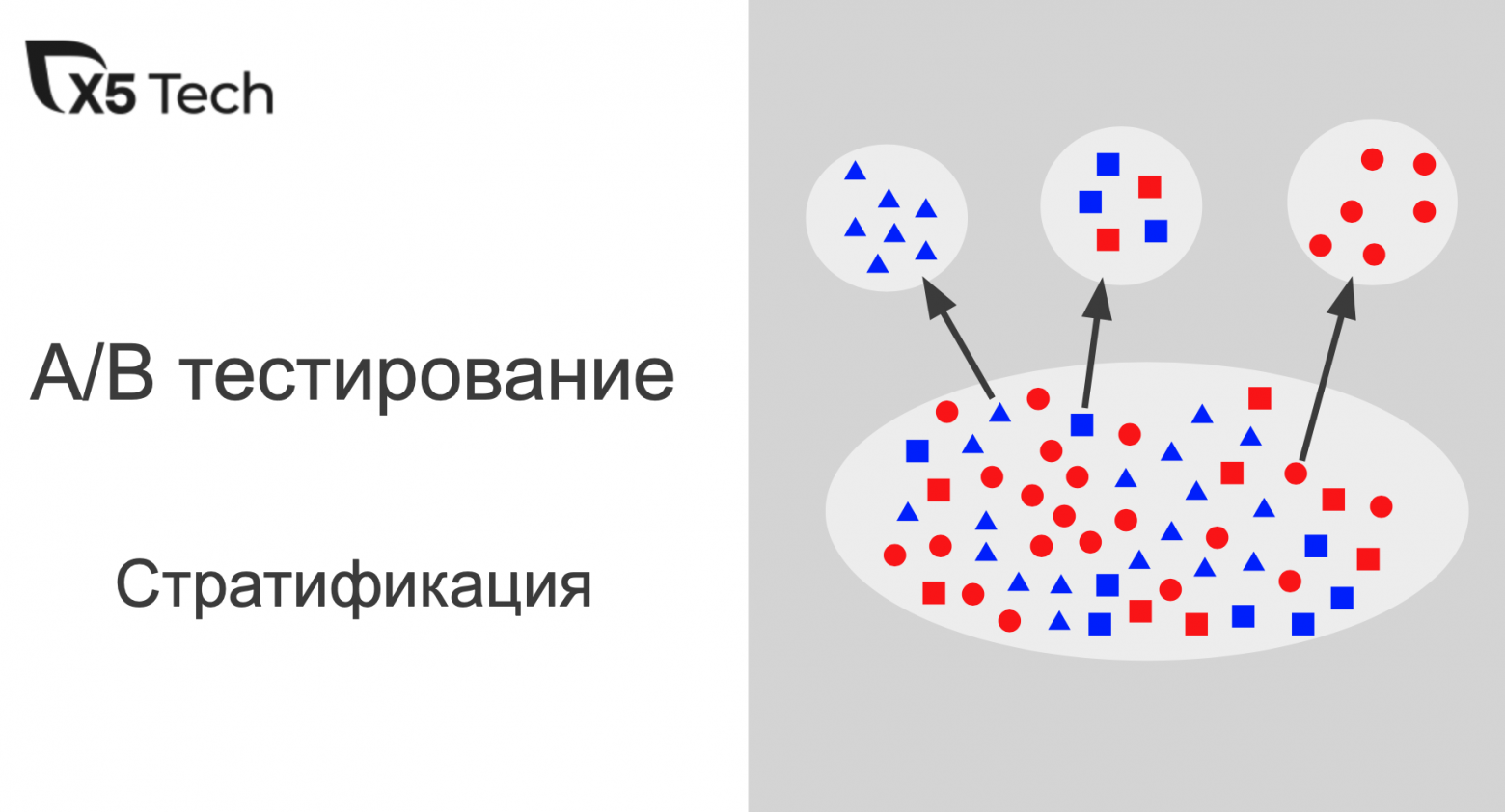
Предназначено для тех, кто задумывается о цифровизации предприятий. Телеграм-бот - это отличный способ сделать интерфейс между базой данных и сотрудником, у которого нет в данный момент доступа в корпоративную сеть (к своему компьютеру). Безусловно, мобильное приложение решает этот вопрос лучше, но затраты на создание/поддержание мобильного приложения несопоставимы с затратами на простого ТГ-бота (или даже средней сложности), то же относится и ко времени разработки/внедрения. Надеюсь, данная статья будет полезной для энтузиастов широкого внедрения ТГ-ботов как технологии цифровизации промышленных (и не только) предприятий.