Ассeмблерные хаки из книги «xchg rax, rax»
5 мин

Разбор фрагментов кода из загадочной книги, которая содержит только ассемблерный листинг и никаких комментариев. Часть 1

Пользователь
Разбор фрагментов кода из загадочной книги, которая содержит только ассемблерный листинг и никаких комментариев. Часть 1

При постройке домашней солнечной электростанции, очень многие владельцы наступают на одни и те же грабли, совершают однотипные ошибки. Цена этих ошибок может быть порой очень высокой - как минимум потеря генерации за довольно длительный период, как максимум - потеря станции и самого дома, на котором стоит СЭС. Вы точно готовы заглянуть по ту сторону солнечной энергетики? Тогда прошу под кат!
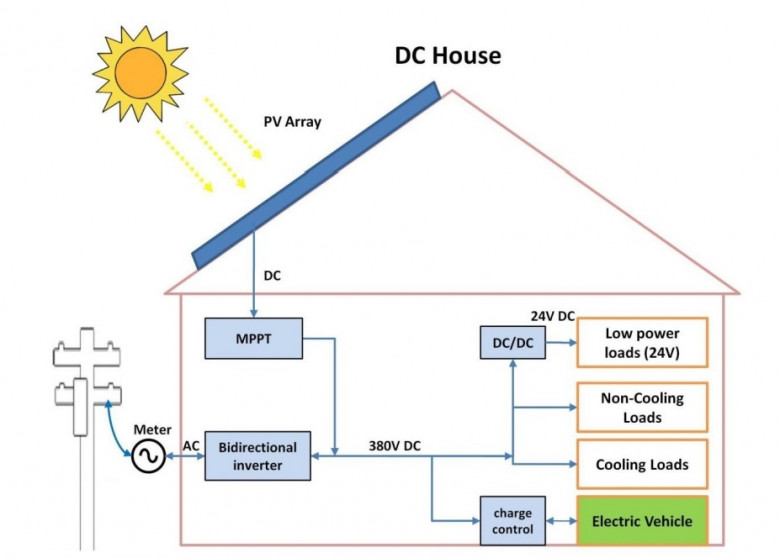
Постоянный ток с каждым днём завоёвывает всё новые рубежи в каждом доме. К кому то он приходит со светодиодными лентами, кому то с DIY и Arduino. Время идёт, и вот уже вчерашние любители без страха и упрёка начинают делать мощные аккумуляторные сборки и запитывать бытовую технику напрямую от солнечных панелей. За кадром остаётся главный нюанс - безопасности. Ведь токи и напряжения выросли вместе с игрушками, а о последствиях почти никто не задумывается.

Определение понятия "рефлексия" из Википедии:
In computer science, reflective programming or reflection is the ability of a process to examine, introspect, and modify its own structure and behavior.
В последние годы разрабатываются варианты ввода рефлексии в стандарт C++.
В этой статье мы напишем код на C++ с рефлексией для решения разных задач, скомпилируем и запустим его на форке компилятора с рабочей реализацией рефлексии.

Была у меня мечта - писать backend на C++. А вот разбираться в unix socket'ах, TCP, многопоточной/асинхронной обработке запросов и во многом другом совсем не хотелось. Не верил я, что до сих пор нет каких-то минималистичных фреймворков. И сегодня я вам расскажу, как можно просто сделать HTTP API микросервис на C++ с помощью фреймворка Drogon.



Есть настоящие профи по управлению проектами или те гении, которые придумывают изящные решения для заказчика. Однако почти в каждом, даже самом многообещающем проекте рано или поздно возникают проблемы. Иногда эти проблемы принимают монструозные масштабы, и команда проекта уже не может справиться с ними самостоятельно. И я тот самый человек, который их решает. Как я это делаю - тема отдельной статьи. Почему практически каждый раз получается? Ответ прост: всегда полезен взгляд со стороны. Однако наступил момент, когда этого оказалось мало. Я вляпался в настоящий факап, и единственным выходом из него были переговоры.

Прим. Wunder Fund: ну, вы наверное, и сами догадываетесь, как мы любим быстрые алгоритмы и оптимизации. Если вы тоже такое любите — вы знаете, что делать)
В наши дни сказать, что изобрёл алгоритм сортировки, который на 30% быстрее того, что считают эталонным, это значит — сделать довольно смелое заявление. Я, к сожалению, вынужден сделать ещё более смелое заявление. Дело в том, что я создал алгоритм сортировки, который, для многих вариантов входных данных, вдвое быстрее std::sort. И, за исключением сортировки специально созданных входных последовательностей, на которых алгоритм упирается в свой худший случай, он всегда быстрее std::sort. (А когда появляются данные, приводящие к худшему случаю алгоритма, я эту ситуацию детектирую и автоматически перехожу на std::sort).
Почему я сказал: «…к сожалению, вынужден…»? Вероятно из-за того, что мне, скорее всего, предстоит нелёгкое дело убеждения читателя в том, что я действительно увеличил скорость сортировки в два раза. Поэтому материал, который я начинаю писать, вполне может получиться достаточно длинным. Но весь мой код открыт — это значит, что вы можете попробовать мои наработки на данных, характерных для вашей сферы деятельности. Поэтому я могу убедить вас в достоинствах моего алгоритма с помощью массы аргументов и результатов измерений. А ещё вы можете просто попробовать алгоритм самостоятельно.
Учитывая то, о чём я писал в моём прошлом материале, это, конечно, вариант поразрядной сортировки (radix sort). То есть — его временная сложность ниже, чем O(n log n). Вот два основных направления, по которым я усовершенствовал базовый алгоритм:

В свое время я случайно узнал, что исключения в моём горячо любимом языке C# — и, как следствие, во всем .NET — не все ведут себя одинаково. Причём, что ещё гораздо интереснее, далеко не все и не всегда могут быть обработаны и перехвачены. Что, казалось бы, полностью противоречит интуитивному восприятию конструкции try-catch-finally.
Изучая этот вопрос, я находил всё новые и новые исключения среди исключений, которые оказывались «сильнее», чем конструкция try-catch-finally. К тому моменту, когда мой список вырос до 7 пунктов, я внезапно осознал, что нигде не было такого места, где можно было бы найти их все сразу. Максимум — 2 или 3 случая, рассмотренных в одной статье.
Это и подтолкнуло меня к написанию данной статьи.

Здесь показана реализация алгоритма Дейкстра для преобразования инфиксной записи в постфиксную, или обратную польскую запись, разбор и вычисление значения выражения в постфиксной нотации.
При работе с неизменяемыми типами данных, такими как readonly struct, нам часто приходится писать методы, которые создают копию объекта, изменяя определенное свойство или поле. Такие методы позволяют сделать код чище и проще, обеспечивая неизменяемость. Но почему бы не переложить эту скучную работу на генератор кода?

В этой серии статей я собираюсь взглянуть на некоторые из новых функций, которые появились в .NET 6. Про .NET 6 уже написано много контента, в том числе множество постов непосредственно от команд .NET и ASP.NET. Я же собираюсь рассмотреть код некоторых из этих новых функций.
Часть 1. ConfigurationManager
В данной статье мы рассмотрим, зачем в стандартной библиотеке нужна конструкция для вывода общего типа, как она реализована и как она работает.

CallerArgumentExpression говорят уже много лет. Предполагалось, что он станет частью C# 8.0, но его внедрение в язык отложили. А в этом месяце он, наконец, появился — вместе с C# 10 и .NET 6.
В последние годы все большую популярность у разработчиков завоевывает структурное логирование. В этой статье я хотел бы рассмотреть, как мы можем добавить поддержку структурного логирования с использованием интерполированных строк при помощи новых возможностей C# 10.

Сборщик мусора в .NET предрекал конец ручного управления памятью и защиту от ее утечек. Идея в том, что при наличии сборщика мусора, работающего в фоновом режиме, разработчикам больше не нужно беспокоиться о необходимости управления жизненным циклом объектов — сборщик сам позаботится о них, когда они станут не нужны.
В реальности все оказалось гораздо сложнее. Сборщик мусора, конечно, помогает избежать наиболее распространенных утечек из тех, что встречаются в неуправляемых программах, утечек, которые возникают из-за того, что разработчик забыл освободить выделенную память, когда работа с ней закончена. Автоматическая сборка мусора также решает проблему преждевременного освобождения памяти, хотя способ решения этой проблемы может и сам привести к утечкам, ведь у сборщика может быть свое, особое мнение на то, является ли объект еще "живым" и в какой момент его необходимо удалить. И чтобы мы могли со всем этим справиться, необходимо понять, как работает сборщик мусора.

Опытные .NET-разработчики знают, что даже несмотря на наличие в .NET сборщика мусора (Garbage Collector), утечки памяти все равно возникают с завидной регулярностью. Утечки возможны не из-за ошибок в сборщике мусора, а потому что даже в управляемом коде есть множество способов их появления.
В этой статье мы пройдемся по наиболее частым причинам возникновения утечек памяти в .NET-приложениях. Все примеры написаны на C#, но описанные проблемы и способы их решения справедливы и для других .NET-языков.
Когда я предложил перевести на русский мою последнюю статью Easy Concurrency with Python Shared Objects на английском, поступило предложение "написать в несколько раз короче и понятнее". Просьба более чем обоснована. Поскольку я уже порядка десяти лет пишу многопоточку и БД, то описываемые мной логические связи выглядели самоочевидно, и я ошибочно расчитывал на аудиторию из трех с половиной человек, которые сидят сейчас где-то в яндексе или гугле. Судя по всему, они там и сидят, но тема им не интересна, поскольку в питоне нет настоящих потоков, а значит для этих людей такого языка программирования не существует. Потому я немножко снижаю планку и делаю общий обзор проблематики параллельных вычислений для людей, которые в них разбираются, но не являются экспертами в области.
Из-за чего весь сыр-бор?

Прим. Wunder Fund: В статье описаны базовые подходы к работе с корутинами в 20м стандарте С++, на паре практических примеров разобраны шаблоны классов для промисов и фьючеров. По нашему скромному мнению, можно было бы реализовать и поизящнее. Приходите к нам работать, если имеете сильные мнения о корутинах хе-хе.
Возникает такое ощущение, что тема реализации корутин в C++20 окутана серьёзной неопределённостью. Полагаю, это так из-за того, что в проекте технической спецификации C++20 сказано, что работа над механизмами корутин всё ещё ведётся, в результате в данный момент нельзя ожидать полной поддержки этих механизмов компиляторами и стандартной библиотекой.Множество проблем, вероятно, возникает из-за отсутствия официальной документации по работе с корутинами. Нам дали синтаксическую поддержку корутин в C++ (co_yield и co_return), но не всё то, что я счёл бы признаками их полной библиотечной поддержки. В стандартной библиотеке имеются хуки и базовый функционал поддержки корутин, но нам приходится самостоятельно встраивать всё это в наши собственные классы. Я ожидаю, что полная поддержка корутин-генераторов появится в C++23.
Если вы — Python- или C#-разработчик и ожидаете увидеть в C++ простую механику работы с корутинами, то вас ждёт разочарование, так как фреймворк общего назначения C++20 недоработан. Учитывая это, можно отметить, что в интернете имеется множество публикаций, в состав кода, обсуждаемого в которых, входит шаблонный класс, поддерживающий корутины-генераторы. В этом материале вы найдёте шаблон корутины, применимый на практике, а также примеры кода. Всё это предваряется общими сведениями о корутинах.