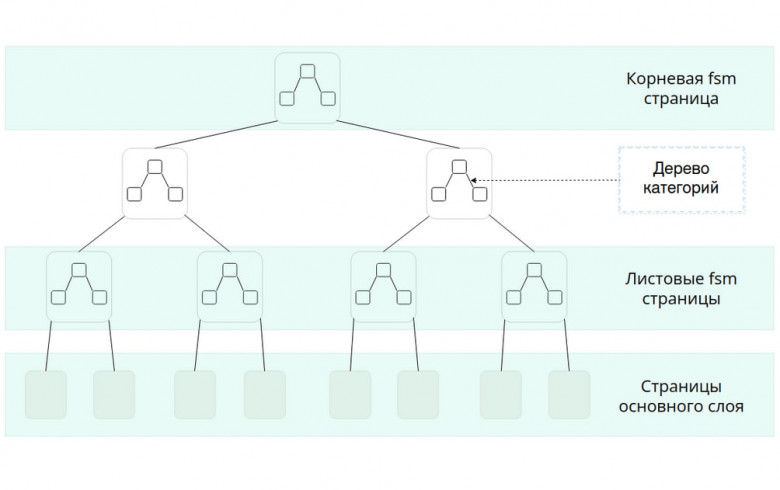
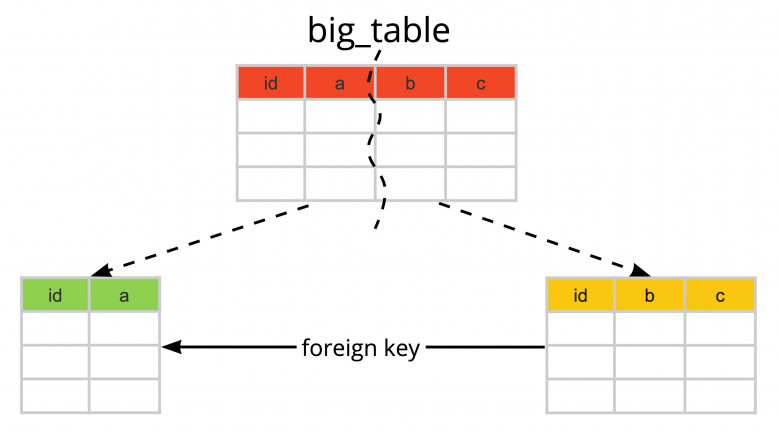
Давно не было обстоятельных интервью, тем более с таким корифеем отечественной СУБД‑разработки. В 2022 году в Postgres Professional перешла команда специалистов по Oracle, включая Марка Ривкина, который занял позицию руководителя отдела технического консалтинга. Вместе с командой он занялся адаптацией продуктов под требования крупных корпоративных заказчиков и доработкой функциональности Postgres Pro — в первую очередь для тех, кто планирует миграцию с проприетарных СУБД.
В интервью для Хабра Марк рассказал, с какими задачами столкнулись на старте, какие функции пришлось внедрять в первую очередь, как выстроена работа с разработкой и сообществом, и в чём сегодня Postgres Pro реально может заменить Oracle, а в чём — пока нет. Поговорили и про ИИ в администрировании, и про перспективы российских форков PostgreSQL, и даже о том, что бы он заложил в архитектуру, если бы проектировал СУБД с нуля. Приятного чтения!