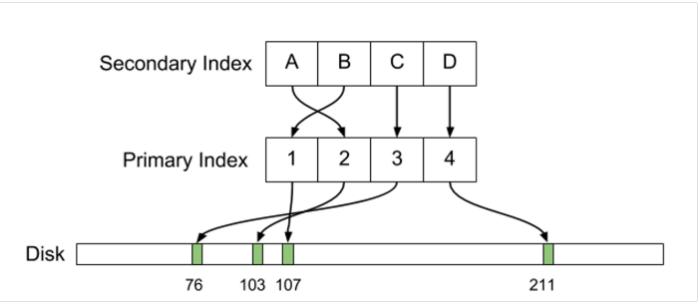
→ Вводная часть (со ссылками на все статьи)
Сложные системы (распределённые/крупные/со сложной логикой/сложной системой данных) – как живой организм: подвижный, изменчивый и самостоятельный. Всё это требует постоянного контроля со стороны разработчиков/администраторов/DevOps-инженеров.
К этому выводу я пришёл, когда система несколько раз «загибалась» в ходе её разработки, настройки сервера и эксплуатации. Это натолкнуло меня на мысль, что мониторинг должен осуществляться не только на этапе производственной эксплуатации, но и на этапе разработки.
Обо всём по порядку…
Сложные системы (распределённые/крупные/со сложной логикой/сложной системой данных) – как живой организм: подвижный, изменчивый и самостоятельный. Всё это требует постоянного контроля со стороны разработчиков/администраторов/DevOps-инженеров.
К этому выводу я пришёл, когда система несколько раз «загибалась» в ходе её разработки, настройки сервера и эксплуатации. Это натолкнуло меня на мысль, что мониторинг должен осуществляться не только на этапе производственной эксплуатации, но и на этапе разработки.
Обо всём по порядку…

 Приветствую бойцов невидимого бэкенда!
Приветствую бойцов невидимого бэкенда!









 Доброго времени суток, жителям Хабра!
Доброго времени суток, жителям Хабра!