Безответственная пресса начинает заполнять наше информационное поле новостями о погибших
от коронавируса, хотя таких сведений не озвучивает ни лечащий врач, ни ВОЗ. Из-за своей невнимательности журналисты де-факто самостоятельно называют причины смерти. И эта маленькая неточность в формулировке имеет колоссальное значение для общества. Сегодня крайне важно не путать общую смертность людей с подтверждённым коронавирусом и смертность непосредственно от коронавируса.
Все мы видели пугающие цифры среди погибших с положительным тестом на Covid-19. Но высокий процент смертности, который мы наблюдаем — есть иллюзия, ибо в большинстве своём мы смотрим на
естественную смертность, которая случилась бы и без заражения, поскольку причиной стало что-то другое. То есть смертность от инфекции как бы умножается на естественную, и мы лицезреем результат этого умножения, хотя нам надо смотреть на частное.
Говоря иносказательно, день смерти для каждого
предопределён и множество людей с коронавирусом, ушедших в мир иной, умерли бы в любом случае. Мы не узнаем их количество, но можем посчитать риски, опираясь на теорию вероятностей. Для этого нам надо сопоставить общую смертность со смертностью при наличии инфекции.
В своей предыдущей статье
«Коронавирус: как мы себя обманываем» я уже демонстрировал разницу между смертностями на примере демографических данных Италии по одной возрастной группе. А сейчас я хочу поделиться свежим
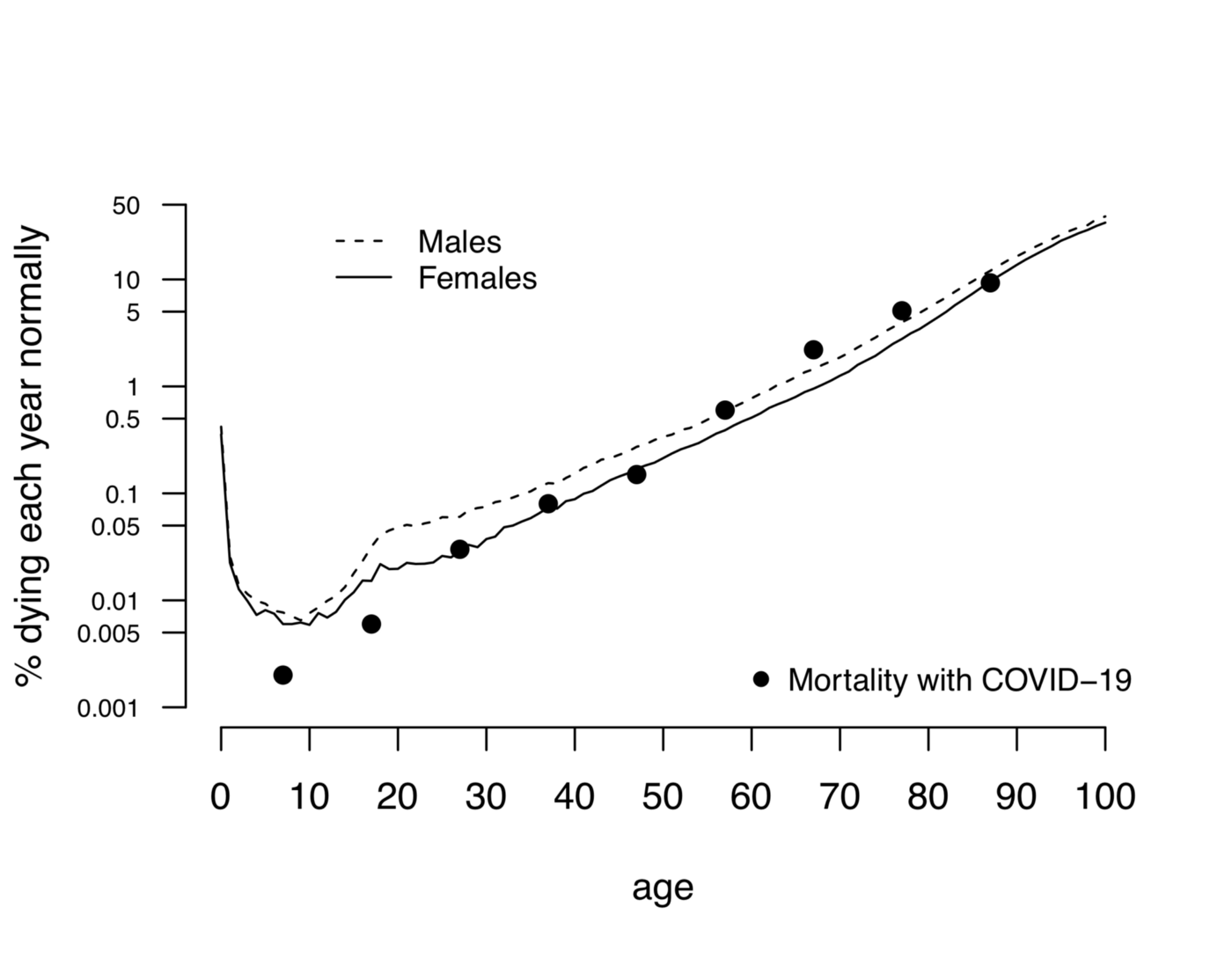
графиком Дэвида Шпигельхальтера, именитого статистика из Университета Кембриджа. В его распоряжении был полный объём данных по Великобритании от Имперского колледжа Лондона.
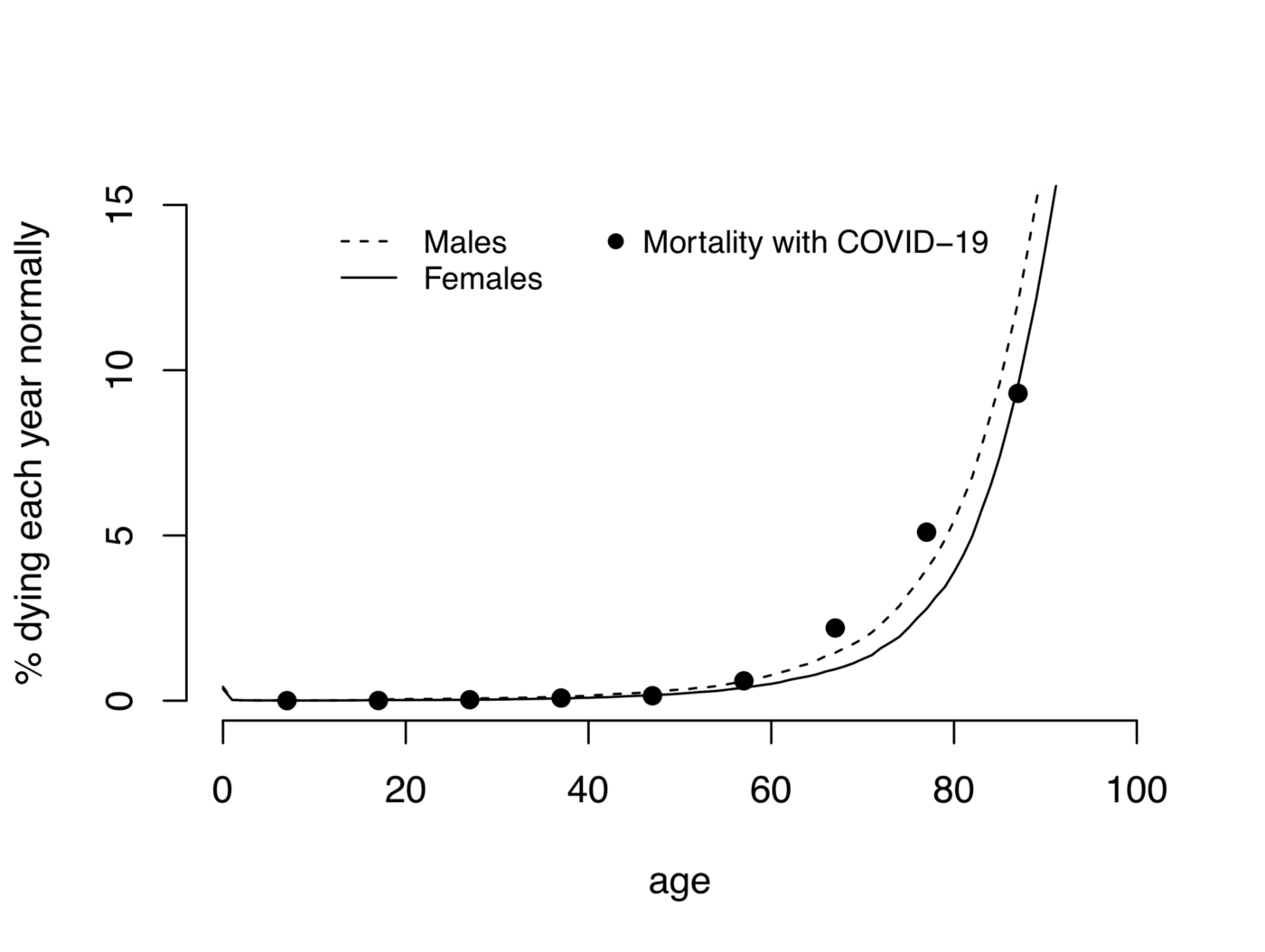
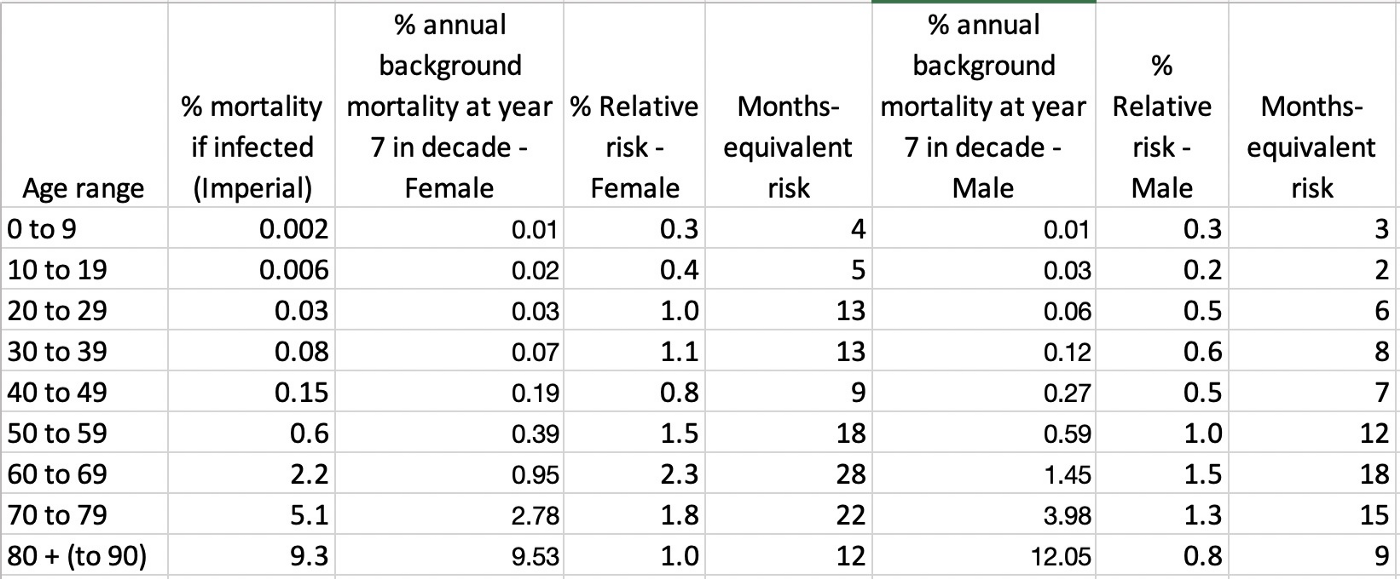
Таблица с данными + те же значения на логарифмической шкале