
Trrr @amaranth
Пользователь
Обработка больших объемов данных в памяти на C#
7 мин
Хочу поделиться недавно приобретенным в C# опытом по загрузке и обработке в памяти больших объемов данных. Все нижеуказанное касается Visual Studio 2008 и .Net Framework 3.5.1, на случай каких-либо отличий в других версиях языка или библиотек.
Итак, у нас возникли следующие задачи:
1. Расположить в памяти до 100 миллионов записей, состоящих из строки, длиной 16 символов (уникальный ключ) и двух целочисленных значений, длиной 4 байта каждый;
2. Быстро находить и редактировать запись по ключу.
Итак, у нас возникли следующие задачи:
1. Расположить в памяти до 100 миллионов записей, состоящих из строки, длиной 16 символов (уникальный ключ) и двух целочисленных значений, длиной 4 байта каждый;
2. Быстро находить и редактировать запись по ключу.
Возможности PCI-E SSD Intel 910
5 мин
Раньше у нас долгое время для кеширования random IO использовались intel 320 серии. Это было умеренно быстро, в принципе, позволяло сократить число шпинделей. При этом обеспечение высокой производительности на запись требовало, мягко говоря, неразумное количество SSD.
Наконец, в конце лета к нам приехал Intel 910. Сказать, что я глубоко впечатлён — не сказать ничего. Весь мой предыдущий скепсис относительно эффективности SSD на запись развеян.
Впрочем, обо всём по порядку.
Intel 910 — это карточка формата PCI-E, довольно солидных габаритов (под стать дискретным видеокартам). Впрочем, я не люблю unpack-посты, так что перейдём к самому главному — производительности.

Цифры реальные, да, это сто тысяч IOPS'ов на произвольную запись. Подробности под катом.
Наконец, в конце лета к нам приехал Intel 910. Сказать, что я глубоко впечатлён — не сказать ничего. Весь мой предыдущий скепсис относительно эффективности SSD на запись развеян.
Впрочем, обо всём по порядку.
Intel 910 — это карточка формата PCI-E, довольно солидных габаритов (под стать дискретным видеокартам). Впрочем, я не люблю unpack-посты, так что перейдём к самому главному — производительности.
Картинка для привлечения внимания
Цифры реальные, да, это сто тысяч IOPS'ов на произвольную запись. Подробности под катом.
Люминофоры — светящиеся в темноте краски. Немного теории и практики
3 мин
 Как и обещал, продолжение темы «светящихся в темноте красок».
Как и обещал, продолжение темы «светящихся в темноте красок». Примерно полгода назад мы искали для себя дополнительный бизнес с элементами развлечения. Остановились на люминофорах — светящихся в темноте красках и предметах. Потом дополнили свой опыт флуоресцентными компонентами (светятся в ультрафиолете). Настоящий вау-эффект был, когда мы своими руками покрасили буквы из пенопласта. Писал об этом в июле.
Наша компания на данный момент имеет весьма большой опыт работы с поставщиками и ассортимент того, что мы сами опробовали как качественное.
Для начала нужно сказать, что разновидностей люминофоров весьма достаточно:
- Фотолюминофоры
- Электролюминофоры
- Катодолюминофоры
- Рентгенолюминофоры
- Радиолюминофоры
Я изучаю фотолюминофоры. Даю ссылку на единственного известного мне производителя люминофоров в России, если кому-либо интересно «посмотреть всех».
Выбор платформозависимой библиотеки в runtime
4 мин
Суть вопроса
В большинстве случаев .NET-приложения являются платформонезависимыми. Мы ожидаем, что наше приложение будет одинаково выполняться как в 32-хразрядной ОС, так и 64-хразрядной.
Так обычно и происходит до тех пор, пока нам не понадобится использовать внешние платформозависимые библиотеки, например неуправляемые. Если такая библиотека существует в вариантах и для
x86, и для x64, то это может принести нам определенную головную боль. Будем исходить из того, что ограничивать наше приложение, например, только 32-хразрядным процессом не в наших правилах.Возможно, нам придется поддерживать вдвое больше конфигураций проекта. В этом случае при отладке придется переключать конфигурации, ведь разработческий веб-сервер Cassini существует только в
x86 варианте, а ReSharper может запускать тесты и в 64-хразрядном процессе. Кроме того, придется выпускать два дистрибутива и предоставлять пользователю при скачивании с сайта ох какой нелегкий выбор. Поэтому разумным решением выглядит выбор подходящей для работы библиотеки уже в runtime в зависимости от того, в каком процессе (32-х или 64-хразрядном) код выполняется. При этом сами проекты остаются AnyCPU.В нашем приложении необходимо подключаться к к Oracle Database, для чего используются библиотеки Oracle Instant Client и Oracle Data Provider for .NET.
Предельная производительность: C#
56 мин
 Я поделюсь 30 практиками для достижения максимальной производительности приложений, которые этого требуют. Затем, я расскажу, как применил их для коммерческого продукта и добился небывалых результатов!
Я поделюсь 30 практиками для достижения максимальной производительности приложений, которые этого требуют. Затем, я расскажу, как применил их для коммерческого продукта и добился небывалых результатов!Приложение было написано на C# для платформы Windows, работающее с Microsoft SQL Server. Никаких профайлеров – содержание основывается на понимании работы различных технологий, поэтому многие топики пригодятся для других платформ и языков программирования.
Результаты новогоднего Хабра-соревнования по программированию, анализ и обсуждение
11 мин
 Честно говоря, я не ожидал такого количества решений: за 24 часа было прислано 265 решений, из которых после удаления повторных отправок осталось 183.
Честно говоря, я не ожидал такого количества решений: за 24 часа было прислано 265 решений, из которых после удаления повторных отправок осталось 183. Из 183 решений у 11 был превышен допустимый размер решения, в 19 случаях — не удалось скомпилировать (об этих ошибках подробнее ниже). Далее 47 дали неправильные ответы на простых тестах (1..1000000), 8 не успели посчитать ответ за минуту (образец решения из условия задачи для 1млн работал 5 минут 36 секунд).
На сложных тестах — 5 решений выдали неверный ответ, и 12 — не уложились в одну минуту. 86 — успешно прошли все тесты.
Если кто потерял, вот топик о старте соревнования с условиями задачи.
Еще один взгляд на Entity Framework: производительность и подводные камни
10 мин
Ни для кого не секрет, что адаптация Entity Framework проходит очень медленно. Огромное количество компаний продолжают использовать Linq2Sql и не планируют менять его на что-то новое в обозримом будущем, несмотря на то, что EF – официально рекомендуемая Microsoft технология доступа к БД, а Linq2Sql уже почти не поддерживается.
Тех, кто всё еще сомневается, можно ли использовать EF (и особенно – code first) на реальных проектах, приглашаю под кат.
Тех, кто всё еще сомневается, можно ли использовать EF (и особенно – code first) на реальных проектах, приглашаю под кат.
Что такое TCHAR, WCHAR, LPSTR, LPWSTR,LPCTSTR (итд)
12 мин
Туториал

Многие C++ программисты, пишущие под Windows часто путаются над этими странными идентификаторами как TCHAR, LPCTSTR. В этой статье я попытаюсь наилучшим способом расставить все точки над И. И рассеять туман сомнений.
В свое время я потратил много времени копаясь в исходниках и не понимал что значат эти загадочные TCHAR, WCHAR, LPSTR, LPWSTR,LPCTSTR.
Недавно нашел очень грамотную статью и представляю ее качественный перевод.
Статья рекомендуется тем кто бессонными ночами копошиться в кодах С++.
Вам интересно ??
Прошу под кат!!!
Как правильно мерять производительность диска
14 мин
Туториал
abstract: разница между текущей производительностью и производительностью теоретической; latency и IOPS, понятие независимости дисковой нагрузки; подготовка тестирования; типовые параметры тестирования; практическое copypaste howto.
Предупреждение: много букв, долго читать.
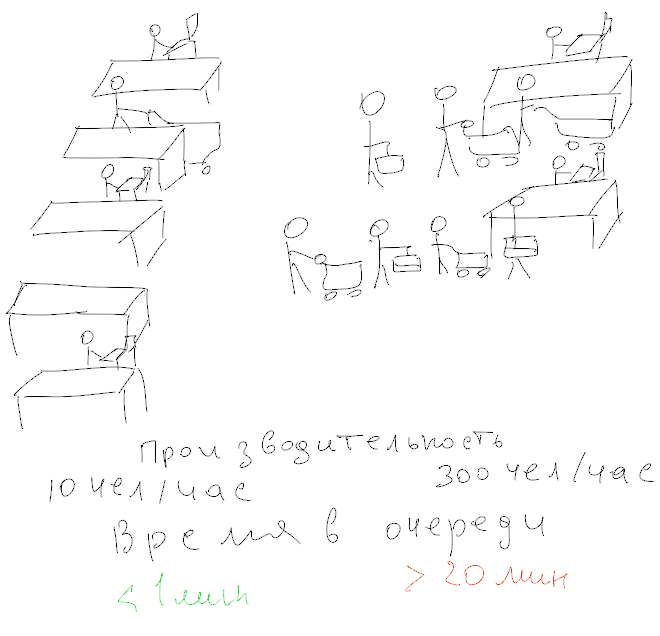
Очень частой проблемой, является попытка понять «насколько быстрый сервер?» Среди всех тестов наиболее жалко выглядят попытки оценить производительность дисковой подсистемы. Вот ужасы, которые я видел в своей жизни:
Это всё совершенно ошибочные методы. Дальше я разберу более тонкие ошибки измерения, но в отношении этих тестов могу сказать только одно — выкиньте и не используйте.
Предупреждение: много букв, долго читать.
Лирика
Очень частой проблемой, является попытка понять «насколько быстрый сервер?» Среди всех тестов наиболее жалко выглядят попытки оценить производительность дисковой подсистемы. Вот ужасы, которые я видел в своей жизни:
- научная публикация, в которой скорость кластерной FS оценивали с помощью dd (и включенным файловым кешем, то есть без опции direct)
- использование bonnie++
- использование iozone
- использование пачки cp с измерениема времени выполнения
- использование iometer с dynamo на 64-битных системах
Это всё совершенно ошибочные методы. Дальше я разберу более тонкие ошибки измерения, но в отношении этих тестов могу сказать только одно — выкиньте и не используйте.
IOPS — что это такое, и как его считать
4 мин
 IOPS (количество операций ввода/вывода – от англ. Input/Output Operations Per Second) – один из ключевых параметров при измерении производительности систем хранения данных, жестких дисков (НЖМД), твердотельных диски (SSD) и сетевых хранилища данных (SAN).
IOPS (количество операций ввода/вывода – от англ. Input/Output Operations Per Second) – один из ключевых параметров при измерении производительности систем хранения данных, жестких дисков (НЖМД), твердотельных диски (SSD) и сетевых хранилища данных (SAN).По сути, IOPS это количество блоков, которое успевает считаться или записаться на носитель. Чем больше размер блока, тем меньше кусков, из которых состоит файл, и тем меньше будет IOPS, так как на чтение куска большего размера будет затрачиваться больше времени.
Значит, для определения IOPS надо знать скорость и размер блока при операции чтения / записи. Параметр IOPS равен скорости, деленной на размер блока при выполнении операции.
Что не пишут в википедии о глобальных навигационных спутниковых системах
8 мин
Вдохновлённый серией постов «Теория радиоволн», я решился на аналогичный пост о системах спутникового позиционирования. Я работаю в структуре, которая занимается обеспечением функционирования системы ГЛОНАСС, поэтому постараюсь рассказать о ней и её конкурентах с несколько другой точки зрения. Пост будет именно об их устройстве, попутно хотелось бы развеять несколько мифов.
Бездисковая загрузка по сети и жизнь после нее
6 мин
История
Однажды к нам пришли (ну, не сами...) серверы с 14 хардами по 2Тб. Избавившись от аппаратного рейда (зачем — вопрос отдельный), мы задумались о том, что неплохо бы сделать для них загрузку по сети, дабы избавиться от возни с разделами. Диски предполагалось экспортировать по iSCSI, и не хотелось выделять какие-то диски на Особенные Системные Диски, а какие-то на всё остальное. Таким образом возникла задача сделать загрузку по сети с размещением корневого каталога в оперативной памяти.
Завершён перевод книги «Pro Git»
1 мин
Что может быть лучшим подарком на день знаний для программиста? Конечно, полезная книга ;) Поэтому команда переводчиков «Pro Git» поднапряглась и доделала перевод книги на русский язык.
«Pro Git» — это довольно обширная обучающая книга о Git от Скотта Шакона — активного участника разработки проектов Git и GitHub. Автор рассматривает в тексте всевозможные аспекты работы с Git'ом, начиная с установки программы и базовых принципов работы децентрализованных систем контроля версий, и заканчивая рассмотрением внутреннего устройства Git'а и созданием валидных объектов в базе Git'а собственными руками. Несмотря на довольно обширный материал и затрагивание довольно специфических тем, книга написана довольно простым языком, содержит массу примеров и иллюстраций, и поэтому должна быть понятна и новичкам, только начинающим знакомиться с системами контроля версий.
Последняя версия перевода книги доступна в форматах pdf, epub, mobi.
Также доступна онлайн-версия перевода, но она, к сожалению, не обновлялась с мая.
«Pro Git» — это довольно обширная обучающая книга о Git от Скотта Шакона — активного участника разработки проектов Git и GitHub. Автор рассматривает в тексте всевозможные аспекты работы с Git'ом, начиная с установки программы и базовых принципов работы децентрализованных систем контроля версий, и заканчивая рассмотрением внутреннего устройства Git'а и созданием валидных объектов в базе Git'а собственными руками. Несмотря на довольно обширный материал и затрагивание довольно специфических тем, книга написана довольно простым языком, содержит массу примеров и иллюстраций, и поэтому должна быть понятна и новичкам, только начинающим знакомиться с системами контроля версий.
Последняя версия перевода книги доступна в форматах pdf, epub, mobi.
Также доступна онлайн-версия перевода, но она, к сожалению, не обновлялась с мая.
Теория игр: Введение
6 мин

Что это такое, и с чем его едят.
Теория игр — это раздел математической экономики, изучающий решение конфликтов между игроками и оптимальность их стратегий. Конфликт может относиться к разным областям человеческого интереса: чаще всего это экономика, социология, политология, реже биология, кибернетика и даже военное дело. Конфликтом является любая ситуация, в которой затронуты интересу двух и более участников, традиционно называемых игроками. Для каждого игрока существует определенный набор стратегий, которые он может применить. Пересекаясь, стратегии нескольких игроков создают определенную ситуацию, в которой каждый игрок получает определенный результат, называемый выигрышем, положительным или отрицательным. При выборе стратегии важно учитывать не только получение максимального профита для себя, но так же возможные шаги противника, и их влияние на ситуацию в целом.
IEEE 1588 Precision Time Protocol (PTP)
6 мин
 Много статей написано про всем известный Network Time Protocol (NTP), в некоторых из них упоминается про Precision Time Protocol, который якобы позволяет добиться точности синхронизации времени порядка наносекунд (например, тут и тут). Давайте разберемся, что этот протокол собой представляет и как достигается такая точность. А также посмотрим результаты моей работы с данным протоколом.
Много статей написано про всем известный Network Time Protocol (NTP), в некоторых из них упоминается про Precision Time Protocol, который якобы позволяет добиться точности синхронизации времени порядка наносекунд (например, тут и тут). Давайте разберемся, что этот протокол собой представляет и как достигается такая точность. А также посмотрим результаты моей работы с данным протоколом.Телевизоры. Часть 2. Плазма или ЖК, шасси, диагональ, передача движения, цвет, влияние на зрение
9 мин
Туториал
Снова здравствуйте, дорогие хабрачеловеки.
Первая часть вызвала определенный интерес, поэтому было решено продолжить эту тему.
Хочу сказать отдельное спасибо, тем кто уделил внимание первой части. Я не думал, что моя скромная статья вызовет такой немалый интерес.
Можем продолжить. Во второй части я хотел бы поделиться своими размышлениями о выборе диагонали телевизора для различных применений, выборе технологии, а так же о том, как кадровая интерполяция влияет на плавность движения и попытаться развенчать некоторые мифы касательно современных телевизоров. Также, хочу затронуть тему влияния различных параметров телевизора на зрение.
Первая часть вызвала определенный интерес, поэтому было решено продолжить эту тему.
Хочу сказать отдельное спасибо, тем кто уделил внимание первой части. Я не думал, что моя скромная статья вызовет такой немалый интерес.
Можем продолжить. Во второй части я хотел бы поделиться своими размышлениями о выборе диагонали телевизора для различных применений, выборе технологии, а так же о том, как кадровая интерполяция влияет на плавность движения и попытаться развенчать некоторые мифы касательно современных телевизоров. Также, хочу затронуть тему влияния различных параметров телевизора на зрение.
Телевизоры. Часть 1. Типы телевизоров, подсветок и технологий, практические различия
7 мин
Туториал
Recovery Mode
Здравствуйте, уважаемое хабрасообщество.
Я надеюсь, что эта статья сможет помочь таким же, как я — тем людям, которые выбирают телевизор, но не очень-то владеют тонкими техническими вопросами в этой области. Хотел бы поделиться с вами своими размышлениями и практическими выводами по-поводу выбора большого и качественного телевизора.
Я надеюсь, что эта статья сможет помочь таким же, как я — тем людям, которые выбирают телевизор, но не очень-то владеют тонкими техническими вопросами в этой области. Хотел бы поделиться с вами своими размышлениями и практическими выводами по-поводу выбора большого и качественного телевизора.
Внутреннее устройство ASLR в Windows 8
7 мин
 ASLR — это Address Space Layout Randomization, рандомизация адресного пространства. Это механизм обеспечения безопасности, который включает в себя рандомизацию виртуальных адресов памяти различных структур данных, чувствительных к атакам. Расположение в памяти целевой структуры сложно предугадать, поэтому шансы атакующего на успех малы.
ASLR — это Address Space Layout Randomization, рандомизация адресного пространства. Это механизм обеспечения безопасности, который включает в себя рандомизацию виртуальных адресов памяти различных структур данных, чувствительных к атакам. Расположение в памяти целевой структуры сложно предугадать, поэтому шансы атакующего на успех малы.Реализация ASLR в Windows тесно связана с механизмом релокации (relocation) исполняемых образов. Релокация позволяет PE-файлу загружаться не только по фиксированной предпочитаемой базе. Секция релокаций в PE-файле является ключевой структурой при перемещении образа. Она описывает, какие необходимо внести изменения в определенные элементы кода и данных для обеспечения корректного функционирования приложения по другому базовому адресу.
Всё что вы стеснялись спросить о бэкапах Microsoft SQL Server
14 мин
Перевод
В ходе проведения презентаций о бэкапах и восстановлении баз данных SQL Server, обычно задаются два типа вопросов. Первые задаются прямо по ходу презентации из зала, вторые задаются уже после, в приватной беседе. Эти, «приватные» вопросы, зачастую более интересны и я попробую дать ответы на наиболее сложные и интересные из них, вместо того чтобы писать ещё одну статью о том как вы должны делать бэкапы, или почему вы должны делать бэкапы, или даже почему вы должны проверять свои бэкапы (но вы и вправду должны проверять свои бэкапы).