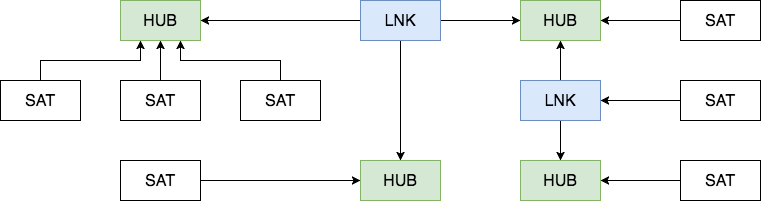
На прошлом уроке я рассказал о том, как повысить контрастность изображения и как выделить на изображении особе точки. Затем мы попробовали работать с найденными особыми точками. В частности, превратили эти точки в список координат и попытались объединить близкие точки в одну, так как у нас получилось очень много точек рядом. В статье был предложен следующий алгоритм: при составлении списка, перед добавлением в список очередной точки проверять, находится ли она близко от последней, если да, то добавлять в тот же список, если нет, то начинать новый список. Только проблема в том, что обход точек был через развертку, и могло получиться так, что близкие точки попадают в разные списки. Поэтому объединение точек получилось «криво». Сегодня мы исправим этот недочет.
Для начала, почему мы вообще начали все эти хитрости с алгоритмом? Дело в том, что если решать задачу «в лоб», то время работы алгоритма у нас будет пропорционально квадрату размера списка. Собственно, давайте сначала проверим, насколько критично будет время работы алгоритма «в лоб» при разных ситуациях. И так, нам нужно перебрать все точки и сравнить их расстояния со всеми точками:




 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.