
Moby/Docker в продакшене. История провала
Обновление: у этой статьи появилось продолжение, переведённое @achekalin. В каком порядке читать — на ваше усмотрение: в этой статье можно получить удовольствие от обширной попоболи автора, а в продолжении — от сделанных им выводов.
Примечание переводчика: в предыдущей статье о подготовке к девопс-конференциям, Gryphon88 задал резонный вопрос: как отличить cutting-edge и хайп? Нижеследующая статья наполнена сочной незамутненной истерикой, которую так приятно читать с утра, попивая чашечку кофе. Минус в том, что она написана в ноябре 2016, но нетленка не стареет. Если после прочтения захочется добавки, есть комментарии на Hacker News. А у тебя, юзернейм, такой же ад? Пиши в комментариях. Итак, начнем.
В первый раз я встретился с Докером в начале 2015. Мы экспериментировали с ним, чтобы понять, для чего бы его можно употребить. В то время нельзя было запустить контейнер в фоне, не было команд чтобы посмотреть что запущено, зайти под дебагом или SSH внутрь контейнера. Эксперимент оказался быстрым, Докер был признан бесполезным и более похожим на альфу или прототип, чем на релиз.
Промотаем нашу историю до 2016. Новая работа, новая компания, и хайп вокруг докера поднялся безумный. Разработчики уже выкатили докер в продакшен, так что сбежать с него не удастся. Хорошая новость в том, что команда run наконец-то заработала, мы можем запускать и останавливать контейнеры. Оно шевелится!
У нас 12 докеризованных приложений, бегающих на проде прямо в момент написания этой заметки, размазанные на 31 хост на AWS (по одному приложению на хост, дальше объясню — почему).
Эта заметка рассказывает, как мы путешествовали вместе с Докером — путешествие полное опасностей и неожиданных поворотов.





 Будьте осторожны
Будьте осторожны
 Здравствуйте, коллеги. Рассмотрим обычный онлайн-эксперимент в некоторой компании «Усы и когти». У неё есть веб-сайт, на котором есть красная кнопка в форме прямоугольника с закругленными краями. Если пользователь нажимает на эту кнопку, то где-то в мире мурлычет от радости один котенок. Задача компании — максимизация мурлыкания. Также есть отдел маркетинга, который усердно исследует формы кнопок и то, как они влияют на конверсию показов в клико-мурлыкания. Потратив почти весь бюджет компании на уникальные исследования, отдел маркетинга разделился на четыре противоборствующие группировоки. У каждой группировки есть своя гениальная идея того, как должна выглядеть кнопка. В целом никто не против формы кнопки, но красный цвет раздражает всех маркетологов, и в итоге было предложено четыре альтернативных варианта. На самом деле, даже не так важно, какие именно это варианты, нас интересует тот вариант, который максимизирует мурлыкания. Маркетинг предлагает провести A/B/n-тест, но мы не согласны: и так на эти сомнительные исследования спущено денег немерено. Попробуем осчастливить как можно больше котят и сэкономить на трафике. Для оптимизации трафика, пущенного на тесты, мы будем использовать шайку многоруких байесовских бандитов (bayesian multi-armed bandits). Вперед.
Здравствуйте, коллеги. Рассмотрим обычный онлайн-эксперимент в некоторой компании «Усы и когти». У неё есть веб-сайт, на котором есть красная кнопка в форме прямоугольника с закругленными краями. Если пользователь нажимает на эту кнопку, то где-то в мире мурлычет от радости один котенок. Задача компании — максимизация мурлыкания. Также есть отдел маркетинга, который усердно исследует формы кнопок и то, как они влияют на конверсию показов в клико-мурлыкания. Потратив почти весь бюджет компании на уникальные исследования, отдел маркетинга разделился на четыре противоборствующие группировоки. У каждой группировки есть своя гениальная идея того, как должна выглядеть кнопка. В целом никто не против формы кнопки, но красный цвет раздражает всех маркетологов, и в итоге было предложено четыре альтернативных варианта. На самом деле, даже не так важно, какие именно это варианты, нас интересует тот вариант, который максимизирует мурлыкания. Маркетинг предлагает провести A/B/n-тест, но мы не согласны: и так на эти сомнительные исследования спущено денег немерено. Попробуем осчастливить как можно больше котят и сэкономить на трафике. Для оптимизации трафика, пущенного на тесты, мы будем использовать шайку многоруких байесовских бандитов (bayesian multi-armed bandits). Вперед.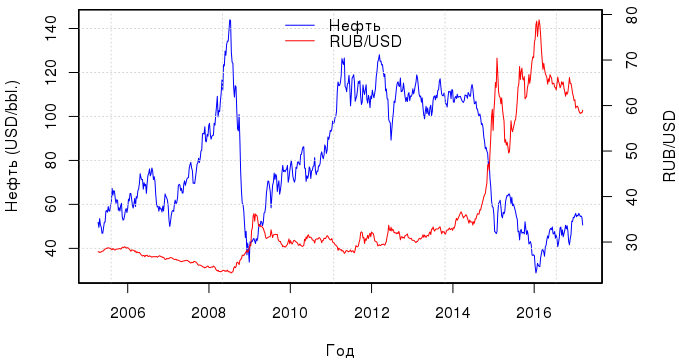
 Прогнозирование временных рядов — это достаточно популярная аналитическая задача. Прогнозы используются, например, для понимания, сколько серверов понадобится online-сервису через год, каков будет спрос на каждый товар в гипермаркете, или для постановки целей и оценки работы команды (для этого можно построить baseline прогноз и сравнить фактическое значение с прогнозируемым).
Прогнозирование временных рядов — это достаточно популярная аналитическая задача. Прогнозы используются, например, для понимания, сколько серверов понадобится online-сервису через год, каков будет спрос на каждый товар в гипермаркете, или для постановки целей и оценки работы команды (для этого можно построить baseline прогноз и сравнить фактическое значение с прогнозируемым).

 Привет, Хабр!
Привет, Хабр!
