
Привет всем! У меня отличные новости: работа с Selenium стала еще проще. Больше никаких танцев с вебдрайверами — теперь всё работает "из коробки"!
В честь этих изменений я хочу поделиться своим опытом работы с этой замечательной библиотекой.

Пользователь
Привет всем! У меня отличные новости: работа с Selenium стала еще проще. Больше никаких танцев с вебдрайверами — теперь всё работает "из коробки"!
В честь этих изменений я хочу поделиться своим опытом работы с этой замечательной библиотекой.

21 марта Redis Ltd. объявила, что, начиная с Redis 7.4, ее «in-memory data store» будет выпускаться под несвободными лицензиями с доступным (source-available) исходным кодом. Новость малоприятная, но вполне ожидаемая. Необычно в этой ситуации обилие альтернатив для тех, кто хочет остаться со свободным ПО: есть как минимум четыре варианта замены, включая уже существующий форк под названием KeyDB и недавно анонсированный проект Valkey от Linux Foundation. Вопрос теперь в том, что предпочтут пользователи, провайдеры и создатели дистрибутивов Linux.

Отказоустойчивость информационных систем необходима для обеспечения непрерывности работы системы и минимизации возможности потери данных в случае сбоев или отказов в работе оборудования. Это особенно важно для критических для бизнеса систем.
Мы начали использовать геораспределенные кластеры и повысили надежность сервисов. В статье опишем, какими инструментами это делали, какие сложности возникали и какие получили результаты.
Привет, Хабр, меня зовут Артур Мечетин, и в этой статье мы со Станиславом Столбовым из Byndyusoft расскажем о том, как повысили стабильность приложений в К8s кластерах с высокой критичностью для бизнеса.

«Однажды темным-темным вечером в темной-темной комнате», — так должна начинаться любая по-настоящему страшная история. Однако история, от которой шевелятся волосы на голове DevOps-инженера, звучит совсем иначе: прод упал и ничего не работает.
Об одном таком случае — как Kube API-серверы заняли всю память и уронили API Kubernetes — мы и рассказали в статье. И конечно, поделились, как ограничивать число запросов в Kubernetes API, чтобы с вами такого не случалось.

Для лиги лени. Какая-то заумь про то, что не нужно, потому что все равно у нормальных людей все приложения давно в облаках на микросервисах, и прекрасно работают.
Часть 3. Что из этого следует, и как устроен планировщик нормального человека в Hyper-V. Тут не будет ничего нового для тех, кто открывал документацию про корневой раздел (root partition)
Для лиги лени. Какая-то заумь про то, что не нужно, потому что все равно у нормальных людей все приложения давно в облаках на микросервисах, и прекрасно работают.
Часть 2. Что из этого следует, и как устроен планировщик в Broadcom ESXi. Тут не будет ничего нового для тех, кто открывал документацию про изменение модели планировщика side-channel aware scheduler (SCA) - SCAv2, и дополнительно читал Performance Optimizations in VMware vSphere 7.0 U2 CPU Scheduler for AMD EPYC Processors и Optimizing Networking and Security Performance Using VMware vSphere and NVIDIA BlueField DPU with BWI

Написать этот материал меня побудило... отсутствие хороших статей по корутинам в C++ в русскоязычном интернете, как бы странно это не звучало. Ну серьезно, C++20 существует уже несколько лет как, но до сих пор почти все статьи про корутины, что встречаются в рунете, относятся к одному из двух типов. Или обзор начинается с самых глубин и мелочей, пересказывая cppreference, а потом автор выдыхается и все сводится к "ну а дальше все понятно, возьмите и примените это в своем коде", что напоминает известную картинку с совой. Либо иногда в статьях рассматривается применение корутин на примере генераторов, и этим все и ограничивается. Но, давайте будем честны, генераторы — это замечательно, но за все время моей многолетней карьеры разработчика я, вероятно, делал что‑то подобное генераторам разве что разок, в то время как асинхронный ввод‑вывод приходится использовать почти в каждом проекте. И поэтому меня гораздо больше интересует реализация асинхронного ввода‑вывода с использованием корутин, а не генераторы. Поэтому пришлось разбираться во всем самому.
Привет, Хабр! Меня зовут Алексей Кокухин, я бэкенд-разработчик в Friflex. Мы создаем сайты и мобильные приложения и специализируемся на решениях для ритейла. Для наших клиентов конверсия в покупку — значимая метрика, поэтому мы постоянно изучаем, какие факторы на нее влияют.
Часто пользователи уходят просто потому, что поиск не смог распознать их запрос. По статистике Baymard Institute, проблемы с распознаванием поисковых запросов есть почти у каждого второго онлайн-магазина. В этой статье предлагаю разобраться, как настроить поиск мобильного приложения, чтобы он распознавал два самых популярных вида запроса — точные и ошибочные.
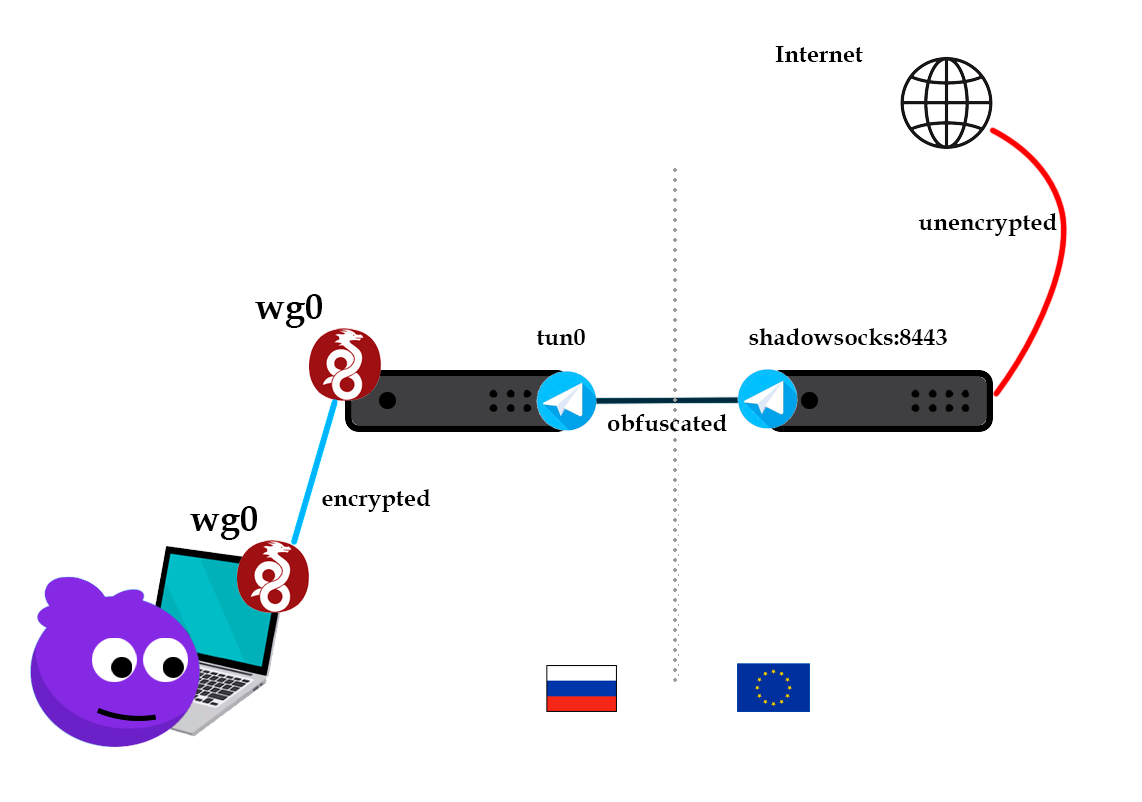
У Wireguard есть немало прекрасного, включая его простоту реализации, скорость и минималистичные клиенты, которые не вызывают проблем у пользователей.
В начале августа некоторые интернет операторы и провайдеры начали блокировку протокола WireGuard в РФ по его рукопожатию.
Лично испытывал блокировку у Мегафон и Теле2, но не заметил у Ростелеком. VPN по-прежнему работал через последнего.
Очень не хотелось отказываться от Wireguard в пользу прокси-серверов в духе VLESS+TLS-Vision, в виду того, что все наши пользователи уже сильно привыкли именно к Wireguard.
Поэтому вариант с кардинальной сменой клиентского софта не рассматривался.
Поскольку трафик Wireguard блокируется только на зарубежные адреса было принято решение добавить еще один хоп в систему, а начальное подключение осуществлять к серверу в РФ.
> С 10 апреля 2024, 3 месяца спустя,
> данная статья заблокирована РКН на территории РФ,
> но доступна с IP других стран, а также через веб-архив.
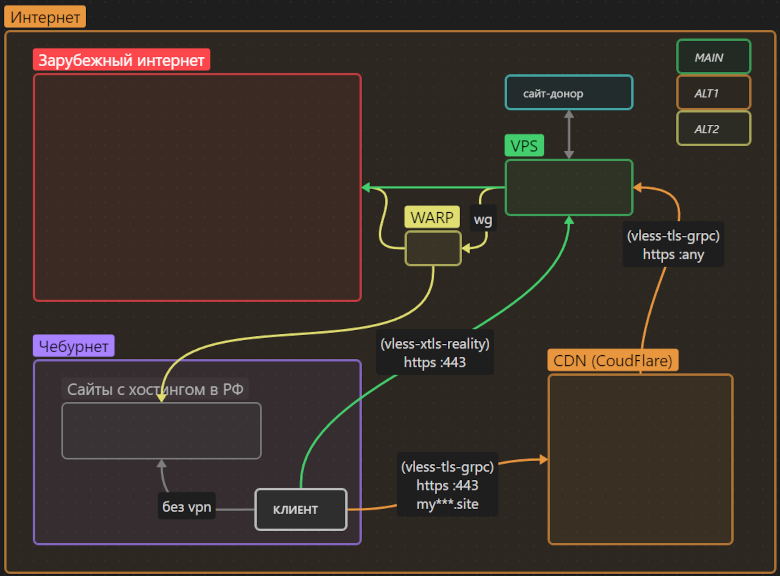
На фоне прошлогоднего обострения цензуры в РФ, статьи автора MiraclePTR стали глотком свободы для многих русскоязычных айтишников. Я же хочу приоткрыть дверь к свободной информации чуть шире и пригласить «не‑технарей» («чайников»), желающих поднять личный прокси‑сервер для обхода цензуры, но дезориентированных обилием информации или остановленных непонятной технической ошибкой.
В этой статье я описал универсальное решение, которое обеспечивает прозрачный доступ к международному интернету в обход цензуры, использует передовые технологии маскировки трафика, не зависит от воли одной корпорации и главное — имеет избыточный «запас прочности» от воздействия цензоров.
Статья рассчитана на «чайников», не знакомых с предметной областью. Однако и люди «в теме» могут найти нечто полезное (например, чуть более простую настройку проксирования через CloudFlare без необходимости поднимать nginx на VPS).
Если у вас ещё нет личного прокси для обхода цензуры — это знак.
Хочу поделиться с сообществом простым и полезным шаблоном скрипта-обёртки на bash для запуска заданий по cron (а сейчас и systemd timers), который моя команда повсеместно использует много лет.
Сначала пара слов о том зачем это нужно, какие проблемы решает. С самого начала моей работы системным администратором linux, я обнаружил, что cron не очень удобный планировщик задач. При этом практически безальтернативный. Чем больше становился мой парк серверов и виртуальных машин, тем больше я получал абсолютно бесполезных почтовых сообщений "From: Cron Daemon". Задание завершилось с ошибкой - cron напишет об этом. Задание выполнено успешно, но напечатало что-нибудь в STDOUT/STDERR - cron всё равно напишет об этом. При этом даже нельзя отформатировать тему почтового сообщения для удобной автосортировки. Сначала были годы борьбы с использованием разных вариаций из > /dev/null, 2> /dev/null, > /dev/null 2>&1, | mail -E -s '<Subject>' root@.


Привет, Хабр! Наконец, после множества бессонных ночей, я завершил работу над второй частью обновления open-source проекта Wunjo AI и воплотил своё видение приложения. В этом обновлении основное внимание уделено звуку: улучшено клонирование голоса, извлечение вокала или мелодии из песен и повышение качества речи. Но это не все, также появились новые функции для работы с видео и создания дипфейков. Давайте рассмотрим все по порядку: начнем с звука и перейдем к видео и дипфейкам. В конце статьи вы найдете ролик, в котором объясняется работа с видео в приложении и функционирование нейронных сетей для создания дипфейков и не только.
Если вам интересно, вы можете прочитать предыдущие статьи на Хабре о создании дипфейков в Wunjo AI и функциях работы с дипфейками и изменениями видео с помощью текста.
Давайте начнем с звука. Одной из основных задач во второй части обновления была работа над звуком. Изначально в Wunjo AI использовалась адаптированная версия Real Time Voice Cloning, но подход был полностью переработан, что привело к улучшенной версии клонирования голоса. Теперь я использую кодировщик, обученный на аудиоматериале через Real Time Voice Cloning, в сочетании с HuBERT Soft. Этот метод позволяет точнее копировать скорость и тембр речи на этапе синтеза звука и перед работой вокодера. Кроме того, на основе исходного аудио, очищенного от шумов, определяется пол голоса (мужской или женский), а затем настройки вокодера подбираются в соответствии с типом голоса.
Однако эта статья сконцентрирована на более простых аспектах без технических деталей. Давайте взглянем на процесс клонирования голоса в Wunjo AI.

Это вторая часть серии (надеюсь) статей про современные Source Generators в .NET. Мотивация и общее описание есть в первой части, рекомендую начинать знакомство с неё.
В этой части мы поговорим про типовые сценарии разработки генераторов.
Недавно мне понадобилось написать генератор кода для одного из своих проектов. Так как надо было обеспечить поддержку Unity 2021, от более современного API — incremental generators пришлось отказаться сразу. Но пост не об этом, а о том, как повысить читаемость и поддерживаемость синтаксического дерева для генерации исходного кода.

Сборная солянка из существующих best practices по работе с Grafana и немного с Prometheus, проверенных мной лично. Можно просто положить в закладки — когда-нибудь да пригодится.

В этом году руководство приняло решение обновлять железо в серверной. Но, с учетом уго древности, требовалось обновить если не всё, то почти всё.
На момент принятия решения об обновлении мы имели полку HP C3000 с блэйд серверами g6-g7 поколений, подключенную к дисковым хранилищам, через ethernet 1GbE аплинки. Дисковые хранилища с sas 10k без кэша. Все это добро работало по iSCSI протоколу, на блэйд серверах были старенькие ESXi. Из нагрузки имелось порядка 70-80 vm разной направленности - начиная от 1С с базами данных до высоконагруженных сервисов. Признаюсь, я умолчал о standalone сервере на nvme под сверх нагруженный сервис, но об этом, может, расскажу позже, если статья зайдет.
Итак. Хотелось чего то современного, быстрого, чтоб аж волосики назад, желательно на nvme дисках и не сильно бьющее по бюджету организации. Ну и надежного, как без этого.
В итоге согласовали покупку 4 серверов hp dl360g10 в nvme исполнении backplane, сетевых карт 2*25GbE, свитчей mellanox SN2410-CB2FC, nvme дисков с минимум 3 DWPD. Всё оборудование с поддержкой RDMA/RoCE.
О том, как всё это новое добро настраивалось и какие решения были приняты далее.

Expression Trees — это, пожалуй, самое удобное средство манипуляции кодом в run-time.
Расширять код метапрограммами в compile-time позволяют Roslyn Source Generators, с ними это стало проще, чем когда-либо.
Пора использовать одно во благо другого, даже если мир к этому еще не совсем готов.